

트랜스포머 논문 Attention is All You Need에서 Multi-Head Attention에 대해 공부한 내용입니다.
지난 글에서는 “Positional Encoding”에 대해 이야기했습니다. 데이터를 병렬로 한 번에 처리하는 트랜스포머의 특징으로 인해 Positional Encoding을 통해 위치 벡터를 추가해줘야 된다는 내용이었습니다. (자세한 내용은 아래 링크를 참고하시길 바랍니다.)


이번 글은 트랜스포머 깊게 공부하기 두 번째로 “Multi-head Attention”에 대해 공부한 내용을 정리했습니다.
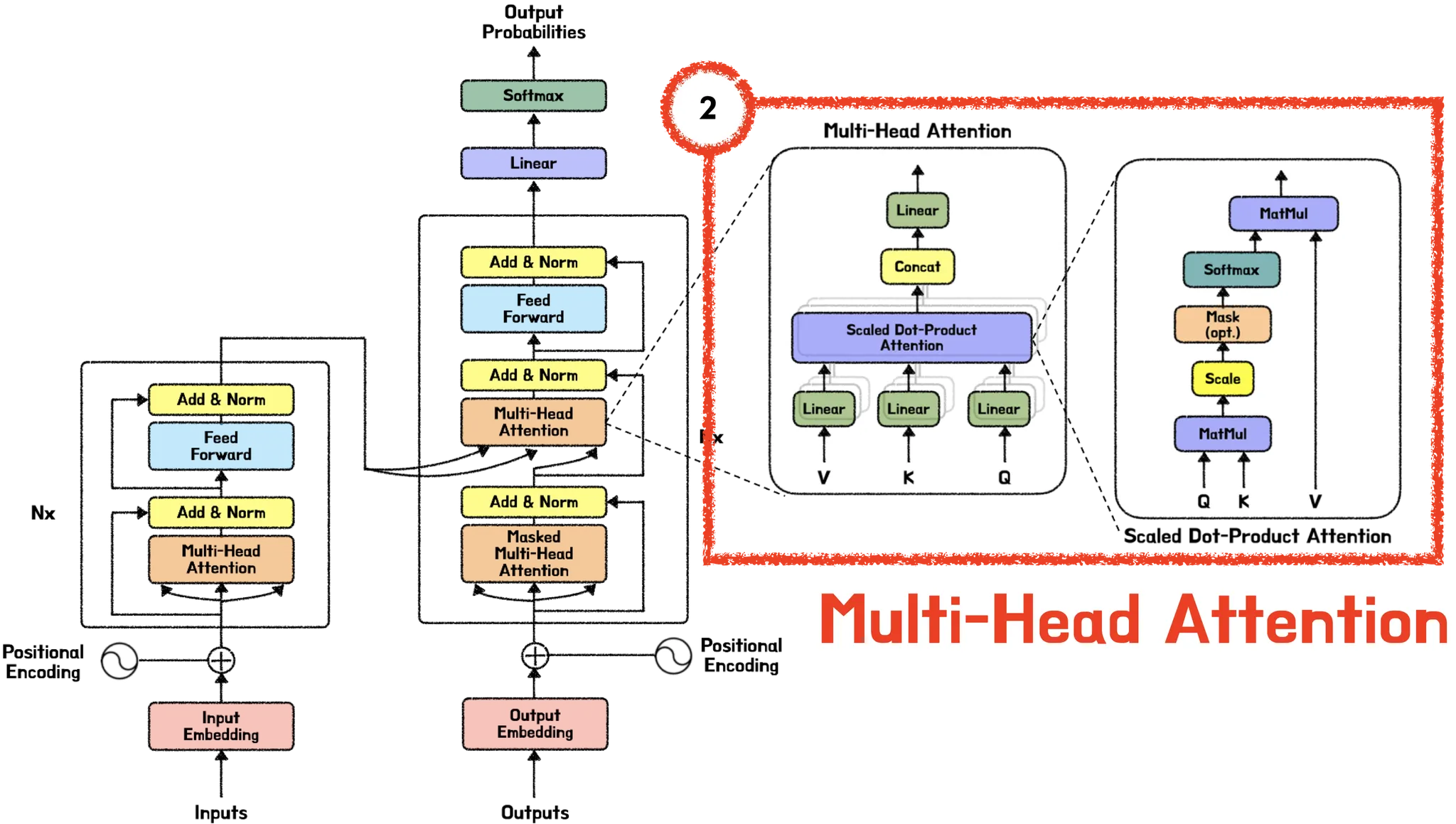
1. Attention? Self-Attention?
위 그림을 살펴보니 흔히 Self-Attention이라 불리워지는 Scaled-dot product Attention이 Multi-Head Attention을 구성하는데 가장 중요한 역할을 한다는 걸 알 수 있다. 그런데 Attention(link)은 들어봤어도 Self-Attention은 무엇일까? 우리가 흔히 아는 Attention과 다른건가? 다르다면 어떤 점이 다른걸까? 이와 같은 궁금점들을 해결하기 위해 먼저 Attention과 Self-Attention에 대해 살펴보면서 Self-Attention에 대해 좀더 자세히 살펴보고자 한다.
우선 Neural Machine Translation[2]을 통해 우리가 일반적으로 알고있는 Attention의 경우 주어진 입력값에서 중요한 단어들에 더 집중할 수 있도록 한다.
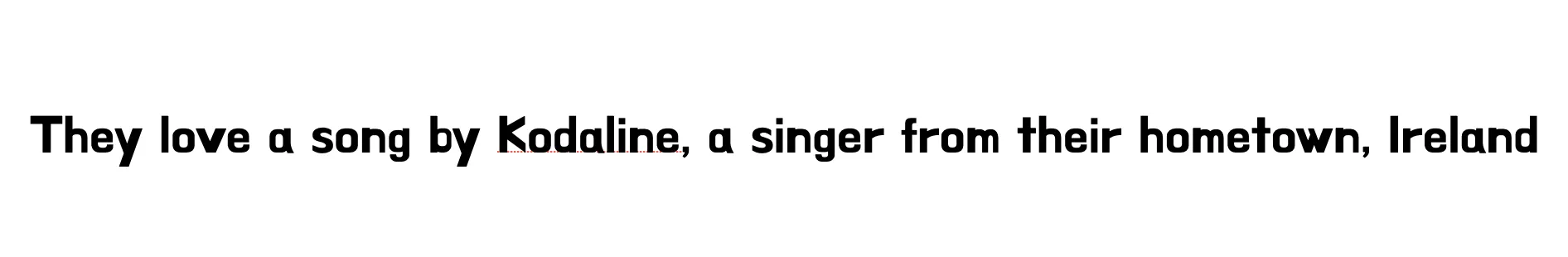
예를 들어 위와 같은 문장이 주어졌고, Who is the singer? 라는 질의가 있다고 가정해보자. 이때 우리는 한 번에 정답을 찾을 수 있지만 컴퓨터는 그렇지 않다. 따라서 “They”, “love”, “a”, “song” 등등 단어 하나하나 singer와의 연관성을 확인해야 한다. 하지만 이런 경우 주어진 입력값이 길어질 수록 gradient vanishing/exploding 문제가 발생할 수 있다. 따라서 Attention을 통해 아래와 같이 주목해야 될 특정 몇몇 단어에 더 높은 가중치를 부과하여 집중하면 얻고자 하는 답을 빠르게 얻을 수 있게 된다.

그리고 여기서 답은 Kodaline이 된다. (참고로 Kodaline-Shed a tear 노래 좋다.) 아무튼 다시 설명하자면, Attention은 주어진 입력값에서 모델이 더 중요한 부분에 집중할 수 있도록 돕는 역할을 한다.
그렇다면 Self-Attention은 무엇일까. Attention 앞에 붙은 Self-를 통해 짐작할 수 있듯이 Self-Attention은 같은 문장 내에서 단어들 간의 관계. 즉 연관성을 고려하여 어텐션을 계산하는 방법이다.

위 문장을 예로 들어 살펴보면 한 문장 내에서 단어들 간의 관계를 파악함으로 tear와 tear는 서로 다른 뜻임을 알 수 있다. 첫번째 tear의 경우 paper과의 연관성을 통해 ‘찢다’라는 의미를 지니고, 두번째 tear의 경우 shed와의 관계를 통해 ‘눈물’의 뜻을 내포한다는 것을 알 수 있다. 이처럼 Self-Attention의 경우 동일한 문장 내 토큰들 간의 관계(유사도)를 토대로 어텐션을 계산하는 방법이다.
Self-Attention에 대해 더 자세히 살펴보기 전에 위의 그림을 보면 Q, K, V가 Self-Attention의 입력값이라는 걸 알 수 있다. 여기서 Q, K, V는 무엇일지 먼저 살펴보고자 한다. (Q, K, V는 각각 query, key, value를 의미한다.)
2. Query, Key, Value !
어텐션의 목표는 value를 통해 가중치 합계를 계산하는 것이고 각 Value의 가중치는 주어진 Query와 Key가 얼마나 유사한가에 따라 결정된다. 즉 어텐션은 전체 시퀀스를 동일하게 고려하지 않고 query, key, value를 통해 입력 시퀀스의 각기 다른 부분에 집중하게 된다.
더 자세히 설명하자면 query, key, value는 아래와 같다.
•
Query
◦
입력 시퀀스에서 관련된 부분을 찾으려고 하는 정보 벡터(소스)
◦
Machine Translation을 예로 들면, 디코더의 현재 상태
◦
관계성, 즉 연관된 정도를 표현하는 가중치를 계산하는데 사용
•
Key
◦
관계의 연관도를 결정하기 위해 query와 비교하는데 사용되는 벡터(타겟)
◦
Machine Translation을 예로 들면, 소스 문장의 인코더 표현
◦
관계성, 즉 연관된 정도를 표현하는 가중치를 계산하는데 사용
•
Value
◦
특정 key에 해당하는 입력 시퀀스의 정보로 가중치를 구하는데 사용되는 벡터(밸류)
◦
Machine Translation을 예로 들면, 소스 문장의 인코더 표현
◦
관계성을 표현하는 가중치 합이 최종 출력을 계산하는데 사용
일종의 파이썬 딕셔너리라고 생각하면 이해하기가 쉽다. 파이썬 딕셔너리의 경우 찾고자하는 것이 key값과 동일해야만 value를 가져올 수 있다. 하지만 어텐션의 Q, K, V 구조에서는 query와 key가 적당히 유사하면 유사한 만큼 value를 가져올 수 있다. 이때 그 유사도를 계산하는 것이 벡터곱이고, 해당 곱의 양만큼 value의 양을 가져와야 해서 또다시 곱을 하는 건데, 한줄로 설명하기에는 복잡하다. 그래서 아래에서 자세히 설명하려고 한다.
3. Self-Attention
3.1. Linear Layer
다시 설명하자면 그림과 같이 각각의 Linear Layer에는 동일한 Emb+Pos가 입력된다.
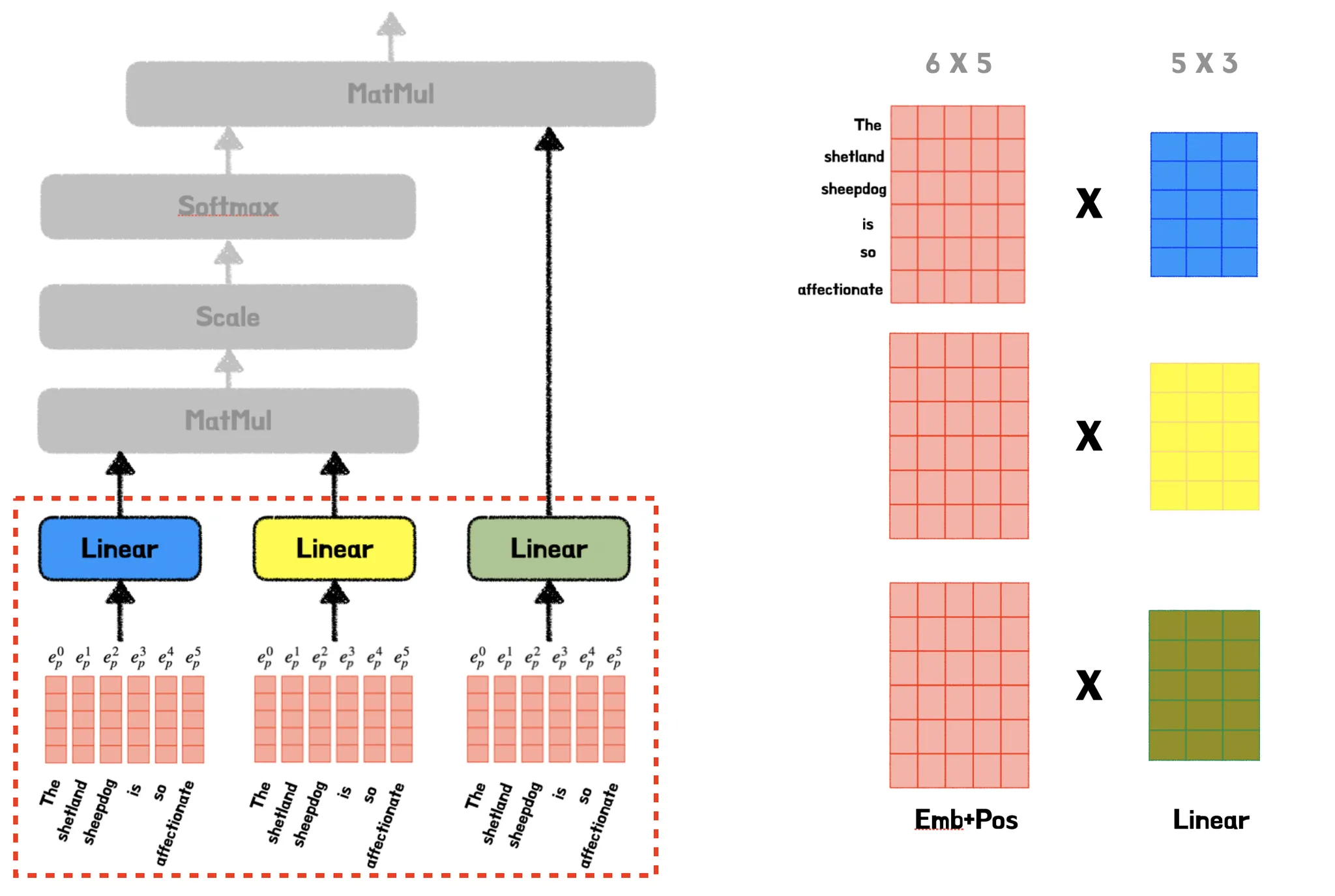
이때 여기서 Linear 연산을 거치는 이유는 두가지로 설명한다면,
•
Linear Layer가 입력을 출력으로 매핑하는 역할을 하고
•
Linear Layer가 행렬이나 벡터의 차원을 바꿔주는 역할을 하기 때문이다.
정리하자면, Emb+Pos가 Linear 연산을 거치는 이유는 query, key, value 각각의 차원을 줄여서 병렬 연산에 적합한 구조를 만들려는 목적이 있기 때문이다.
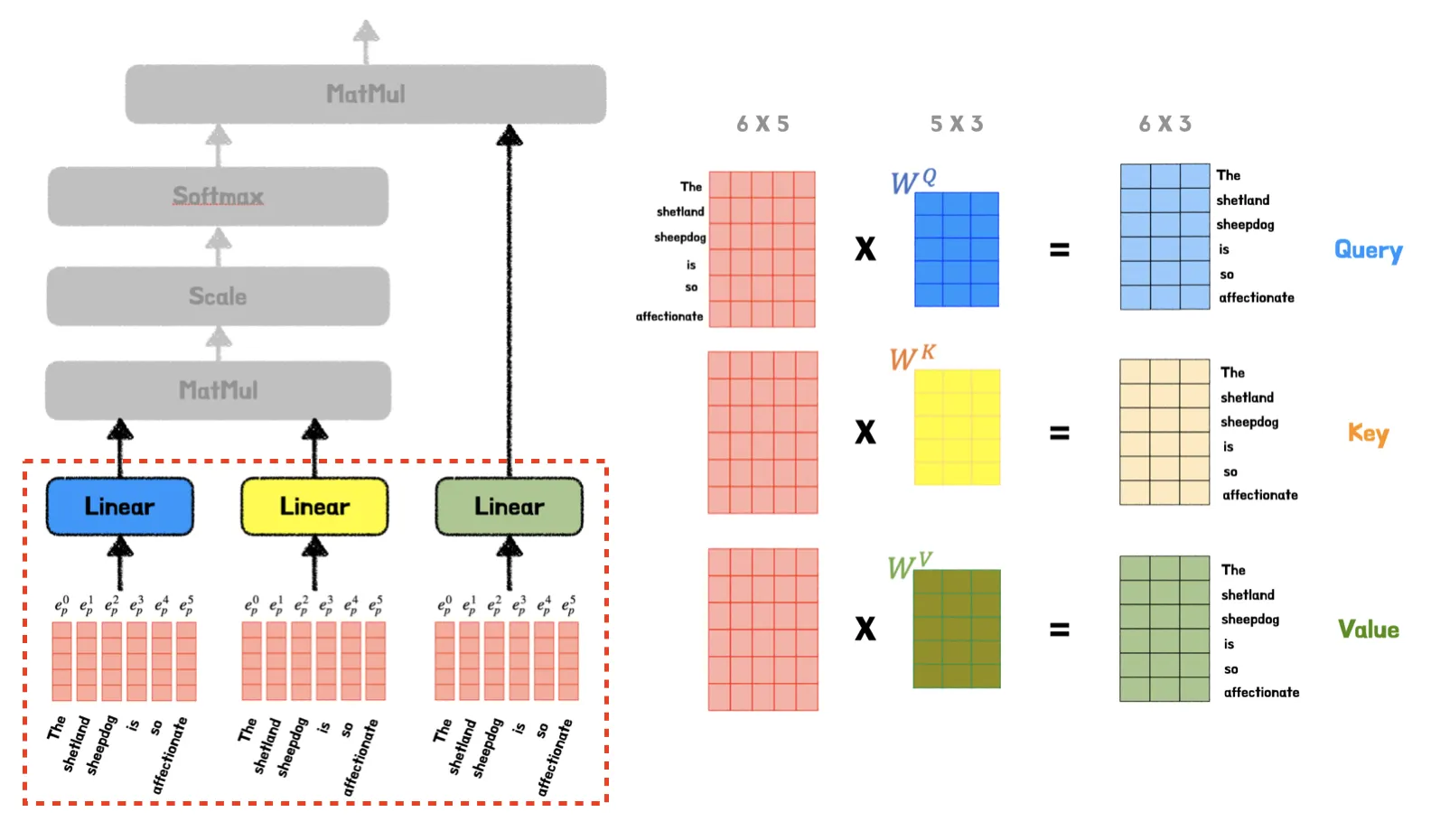
3.2. Attention Score
Linear 연산을 통해 그림과 같이 동일한 query, key, value를 얻게 된다. 그후 다음 연산으로 먼저 query와 key행렬을 내적한다. 그럼 그 결과 아래 그림처럼 Attention Score를 얻게 된다.
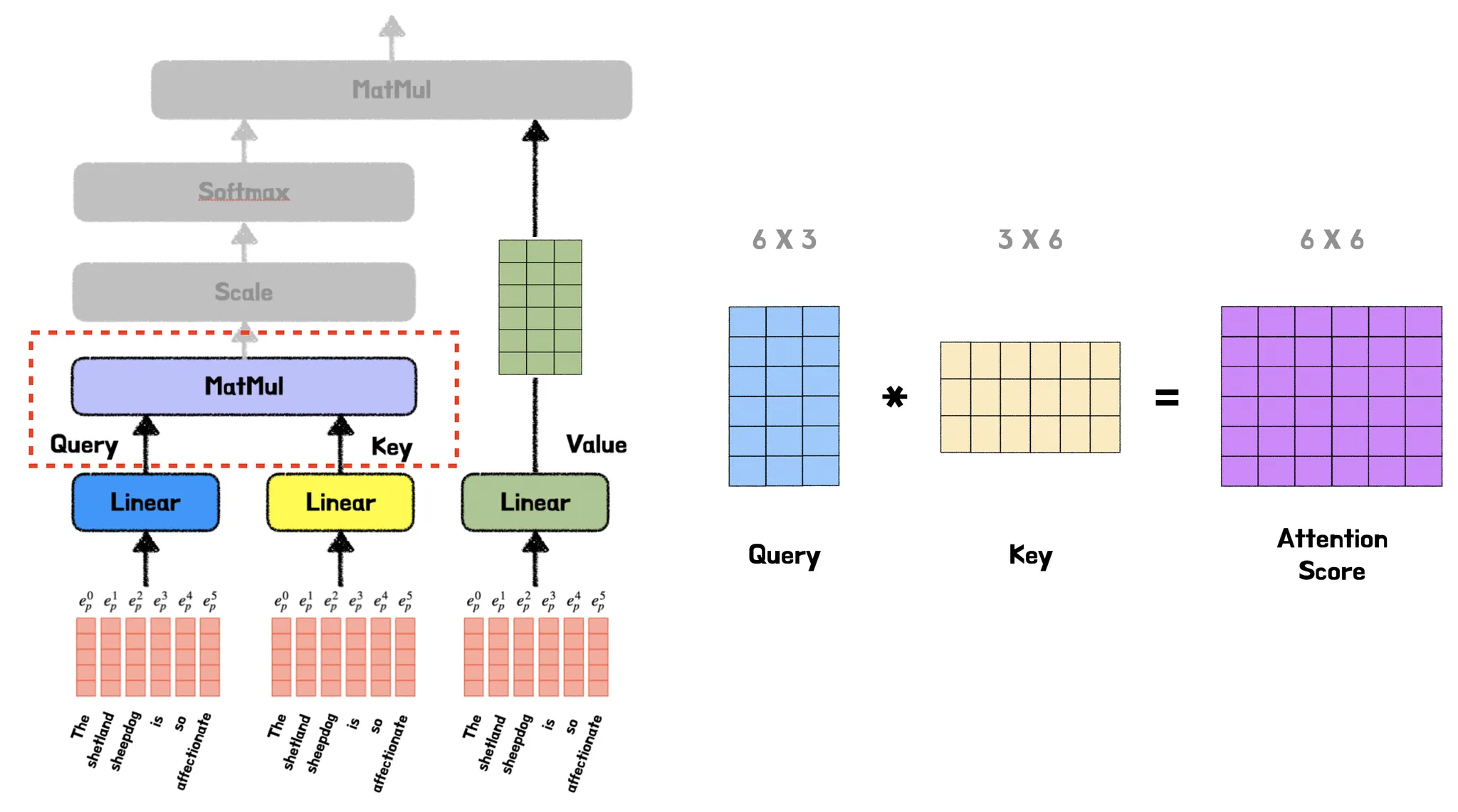
여기서 Attention Score란 query와 key 행렬의 행렬곱으로 이때 행렬곱은 행렬 간의 유사도를 의미하기에 Attention Score는 query와 key 사이의 유사도인 유사도 행렬를 나타낸다.
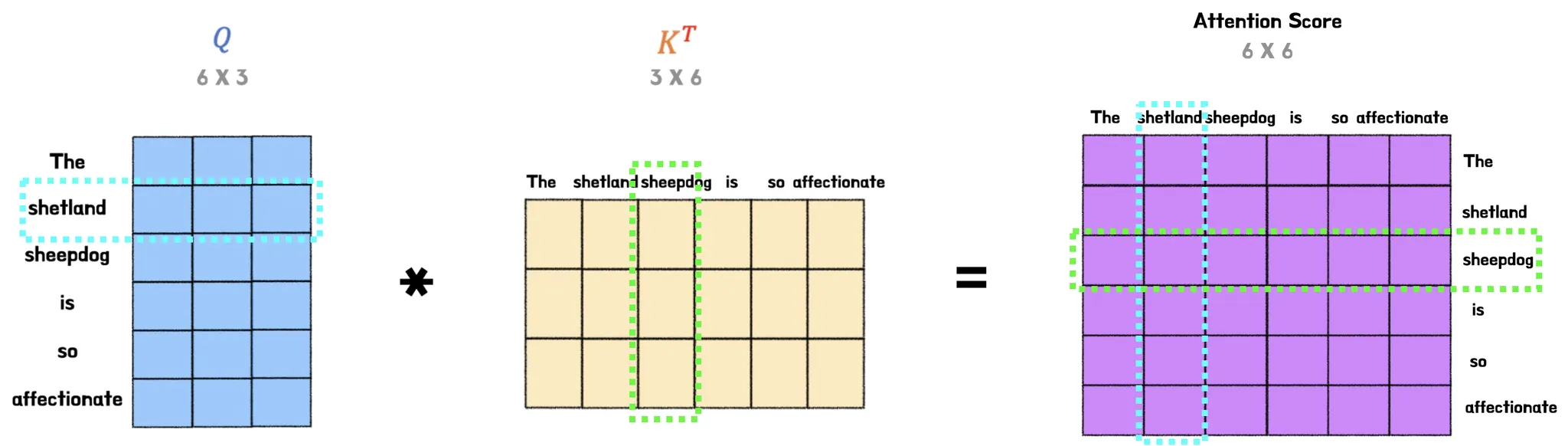
다시 설명하자면 query 행렬의 ‘shetland’ 벡터와 key 행렬의 ‘sheepdog’ 벡터 간의 내적값이 Attention Score가 되고, 이는 query의 ‘shetland’ 벡터와 Key의 ‘sheepdong’ 벡터가 얼마나 유사한지를 나타낸다.
이를 수식을 통해 다음과 같이 설명할 수 있다.
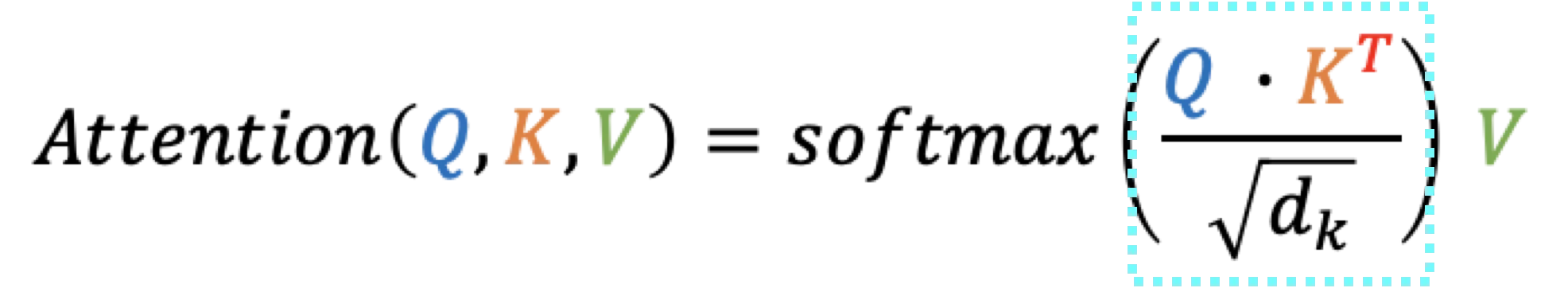
위 식은 우리가 구하고자 하는 Self-Attention이다. 그 중 파란색 상자에 해당하는 유사도 행렬에 대해 살펴본다.

우리가 잘 아는 코사인 유사도 공식이다. 코사인 유사도는 두 벡터가 유사할 수록 값이 1에 가까워지고 두 벡터가 서로 다를 수록 -1에 가까워지는 특징을 가지고 있다. 이러한 코사인 유사도를 다음과 같이 표현할 수 있다.

즉 코사인 유사도는 벡터의 곱을 두 벡터의 L2 norm 곱, 즉 스케일링으로 나눈 값이다. 다시말해 벡터A와 벡터B의 유사도를 구하는 벡터 유사도를 뜻한다.
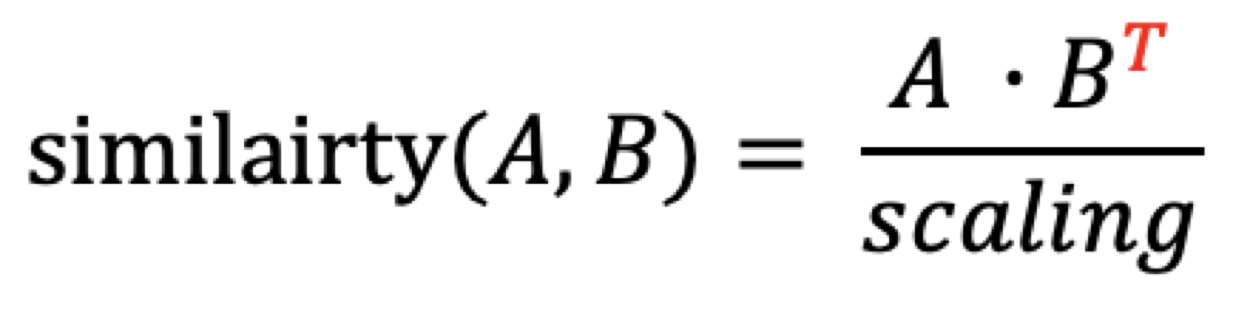
이를 토대로 우리는 이와 같은 행렬 유사도도 구할 수 있게 된다.행렬A와 행렬B의 유사도로 행렬 유사도의 경우 행렬 간의 곱으로 발생하는 차원 충돌을 피하기 위해 행렬B를 전치행렬처리 해준다.

앞서 구한 행렬 간의 유사도에서 행렬A와 행렬B 대신 우리가 구하고자 하는 행렬 query와 행렬 key를 넣어주면 앞서 살펴본 Attention Score를 구하는 식이 된다.
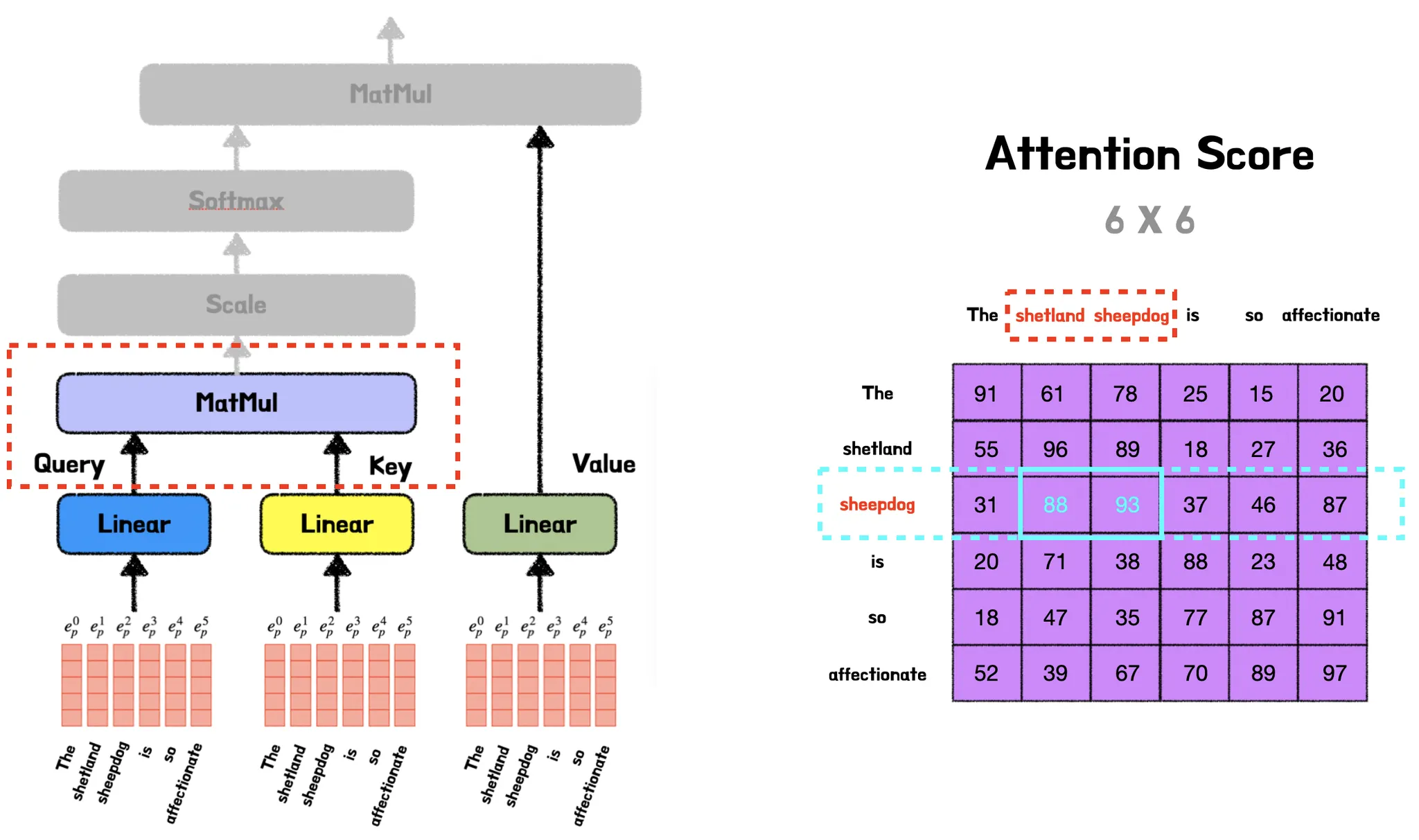
이렇게 구한 Attention Score를 훈련을 시키고 나면 아래와 같은 값을 얻게 되는데 이때 그 값을 보면 자기 자신과 매핑되는 값이 가장 크고 그 다음으로 유사한 값이 크다는 것을 알 수 있다. 그 다음으로 Attention Score를 Scaling하는 과정을 거친다.
3.3. Scaling & Softmax
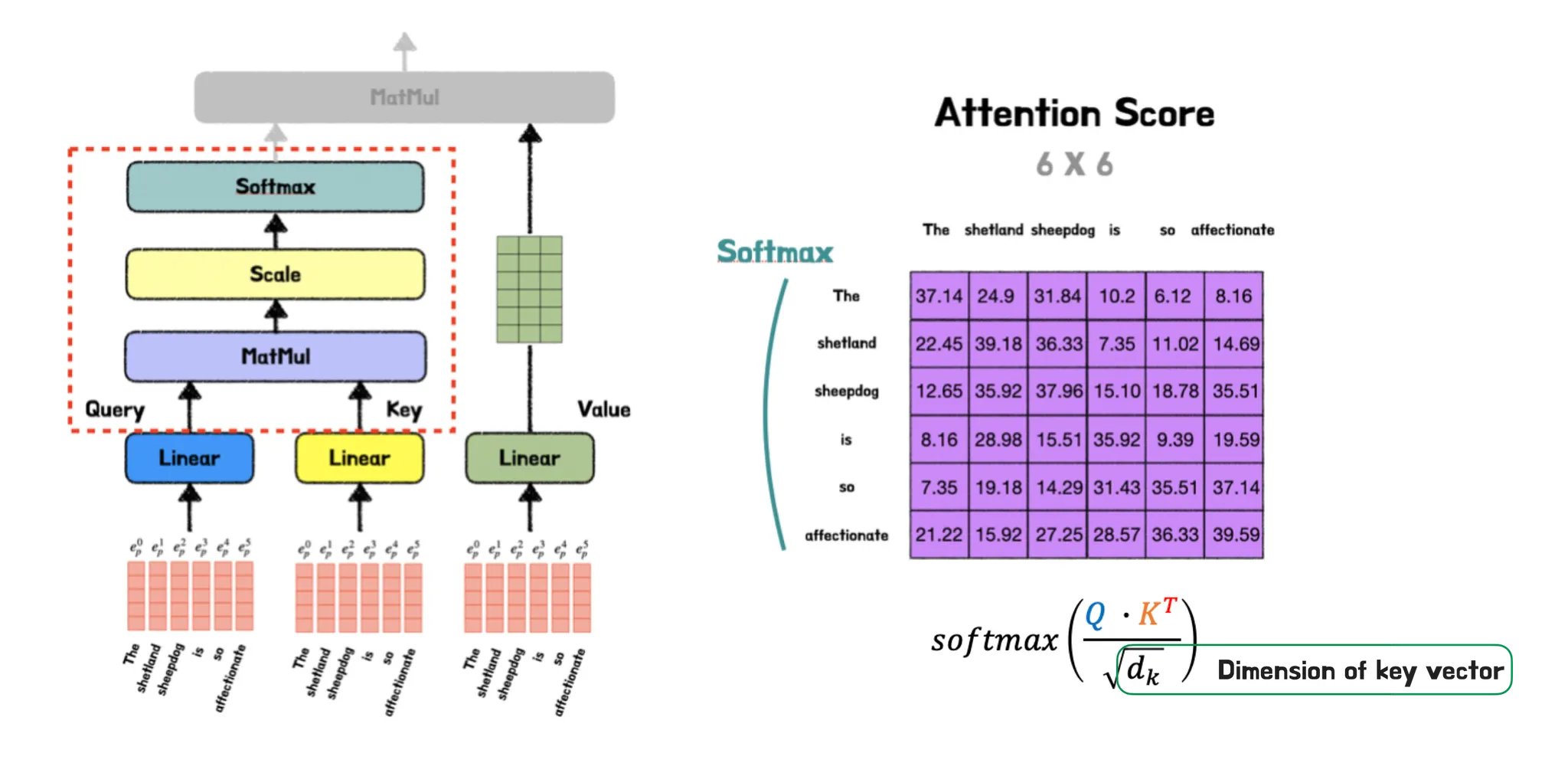
Scale 연산을 수행할 때 Scaling Factor는 Key 벡터의 차원의 제곱근이다. 여기서 스케일링이란 무엇이고 왜 필요한지 이해하기 쉽게 이야기하자면, dot-product 계산은 특성상 문장의 길이가 길어질 수록 더 큰 숫자를 가지게 된다. 문제는 이것들에 나중에 Softmax를 먹이게 될텐데, 큰 값들 사이에서의 Softmax는 특정값만 과도하게 살아남고 나머지 값들은 완전히 죽여버리는 과한 정제가 이루어져 버린다는 점이다. 작은 값들은 작은 gradient로 작용하게 되고 결국 학습도 느려지게 된다. Softmax가 비스므리한 값들 사이에서 이루어지도록 원래값을 Scaled-down 해주면 Softmax 이후에도 살아남는 gradient가 충분히 많아진다. 따라서 Scale 연산을 수행한다. 쉽게말해서 gradient 살리기 대작전이다. 그 다음으로 행렬 Attention Score의 유사도를 0에서 1 사이 값으로 normalize하기 위해 Softmax 함수를 사용한다.
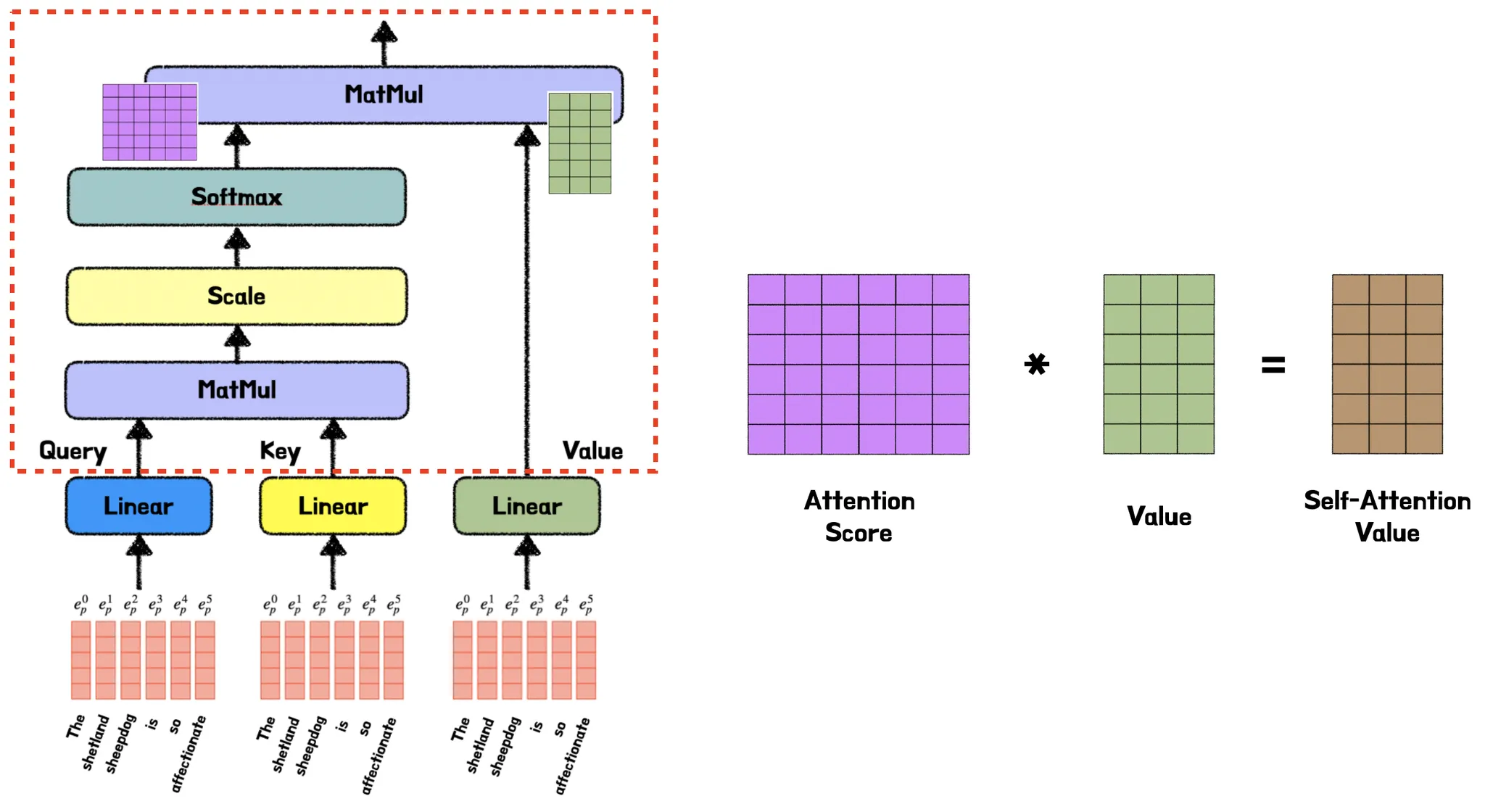
마지막으로 Attention Score와 앞서 구했던 Value를 내적하면 그 결과 Self-Attention Value를 구하게 되면서 Self-Attention 과정을 마무리하게 된다. 중요한 점은 트랜스포머는 이러한 Self-Attention을 여러개 사용하는 Multi-head Attention으로 이루어져있는데 다음에서 자세히 살펴보고자 한다.
4. Multi-head Attention
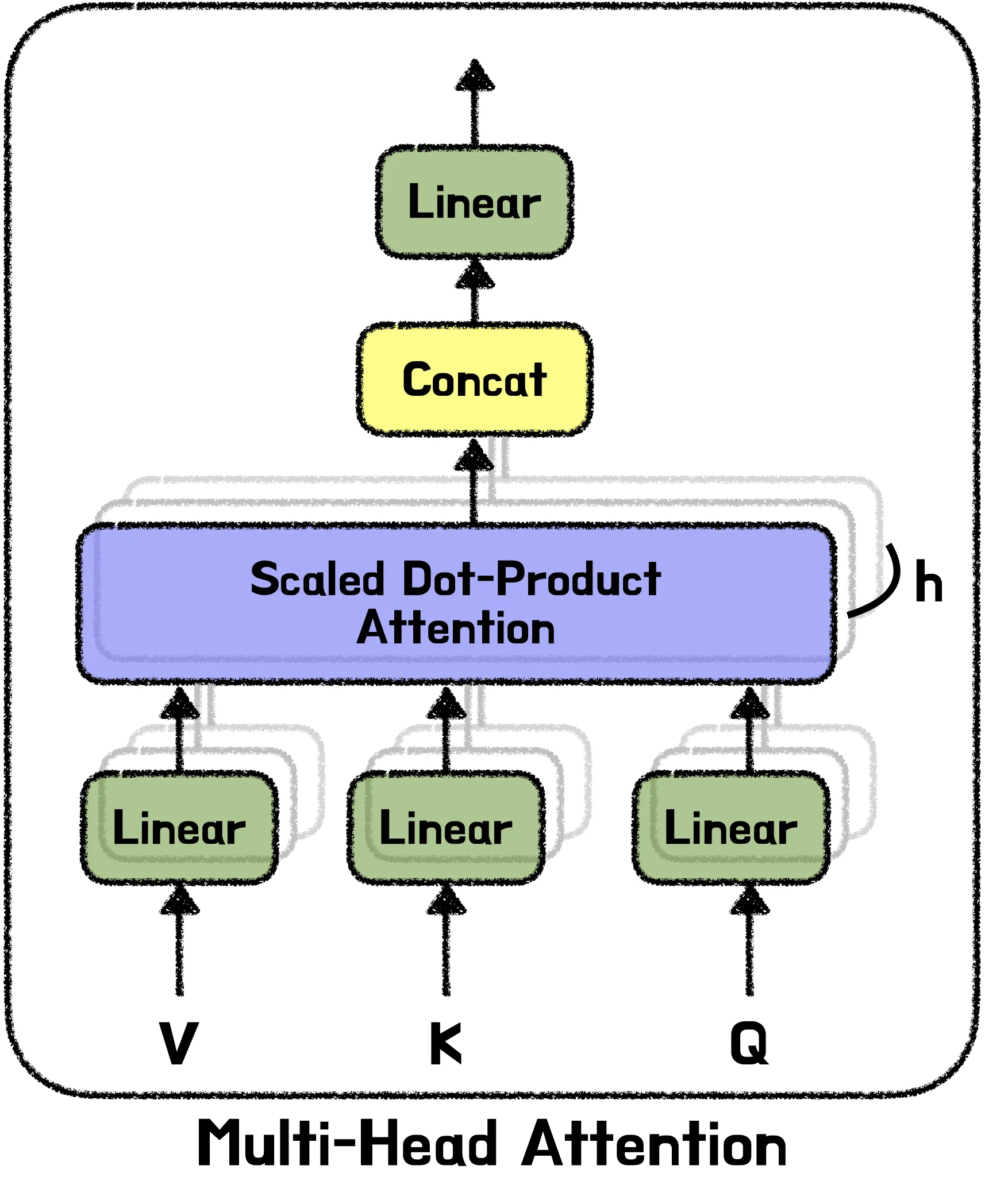
트랜스포머는 앞서 설명한 Self-Attention을 병렬로 h번 학습시키는 Multi-Head Attention 구조로 이루어져 있다. 그렇다면 트랜스포머는 왜 굳이multi-head 구조를 사용하고 있을까? 그리고 왜 병렬로 여러개를 학습하고 있을까?
병렬로 multi-head를 사용함으로 여러 부분에 동시에 어텐션을 가할 수 있어서 모델이 입력 토큰 간의 다양한 유형의 종속성을 포착하고 동시에 모델이 다양한 소스의 정보를 결합할 수 있게 된다.
쉽게 설명하기 위해 “Which do you like better, coffee or tea?” 문장을 예로 들어본다.
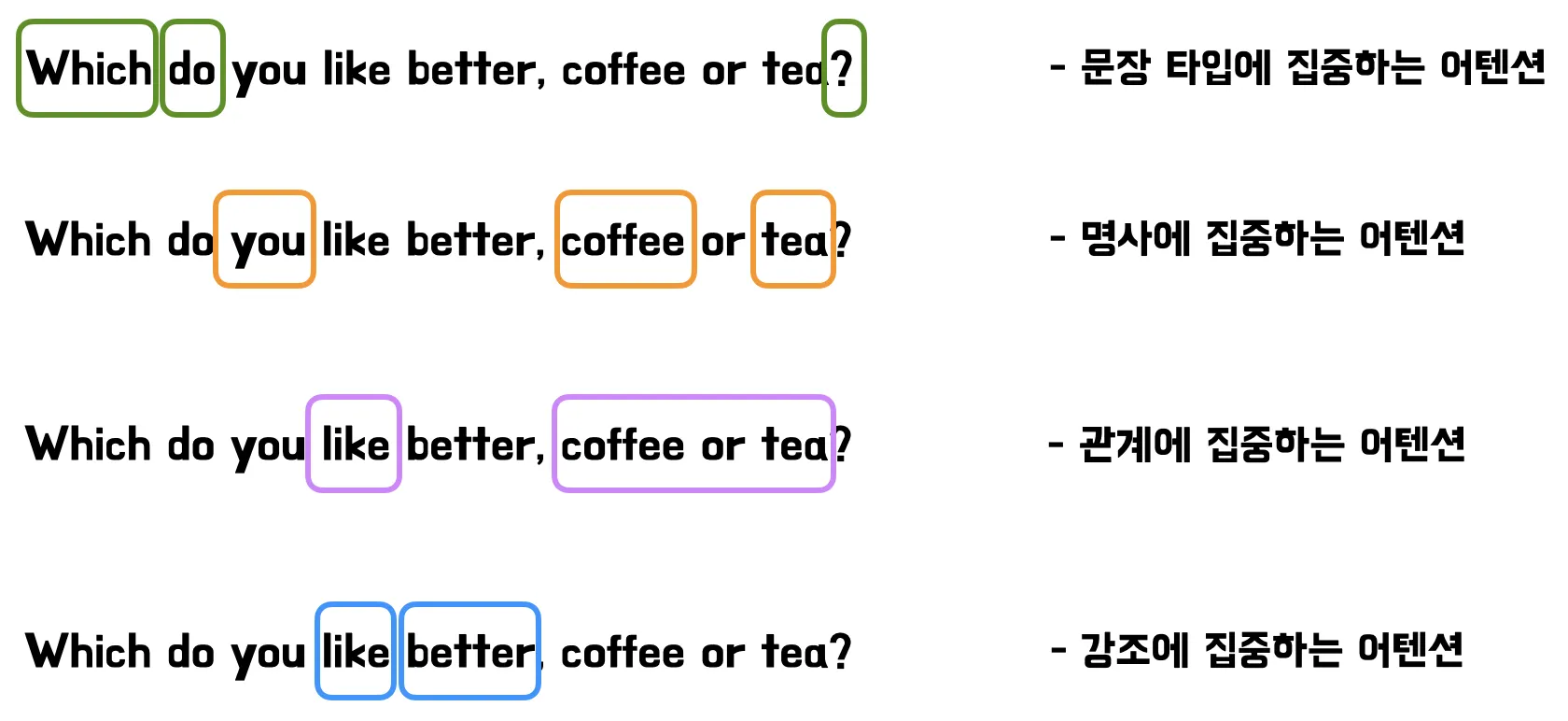
위 그림과 같이 한 head는 문장 타입에 집중하는 어텐션을 줄 수도 있고, 다른 head는 명사에 집중하는 어텐션, 또다른 head는 관계에 집중하는 어텐션 등등 multi-head는 같은 문장 내 여러 관계 또는 다양한 소스 정보를 나타내는 정보들에 집중하는 어텐션을 줄 수 있다.
즉 multi-head attention을 사용하게 되면 각 head는 입력 시퀀스의 서로 다른 부분에 어텐션을 주기 때문에 모델이 입력 토큰 간의 더 복잡한 관계를 다룰 수 있어 입력 시퀀스를 더 많은 정보로 표현할 수 있다. 또한 다양한 유형의 종속성을 포착할 수 있어 표현력이 향상될 수 있고 토큰 간의 미묘한 관계 역시 더 잘 포착할 수 있게 된다.
이번 글에서는 트랜스포머 Attention is All You Need 논문에서 Multi-head Attention에 대한 내용을 정리했습니다. Self-Attention은 같은 문장 내 토큰들 간의 관계(유사도)를 통해 어텐션을 구하며, Multi-head를 사용하면 모델이 입력 토큰 간의 여러 유형의 종속성을 포착할 수 있고, 더 복잡한 관계도 다룰 수 있게 되어 표현이 풍부해진다는 사실을 알게 되었습니다.
다음 글은 트랜스포머 트릴로지의 마지막 “트랜스포머 깊게 공부하기 — 3. Decoder & Masked Attention” 으로 트랜스포머 디코더에 대해 설명하면서 Residual Connection, Encoder-Decoder Attention, 그리고 Masked Attention에 대해 정리할 예정입니다.


참고자료
[2] Dzmitry Bahdanau et al. “Neural Machine Translation by Jointly Leraing to Align and Translate”, ICLR 2015
[3] Minh-Thang Luong et al. “Effective Approaches to Attention-based Neural Machine Translation”, EMNLP 2015
•
이 글을 작성할 때, Peltarion 블로그에 있는 “Self-attention: step-by-step video”도 참고했었는데 레퍼런스를 달려고 해당 사이트에 다시 들어가보니 사이트 자체가 없어져서 찾을 수 없게 되었음을 알려드립니다.
•
설명에 사용된 그림은 전부 키노트로 그린 그림입니다.