




안녕하세요. Physics-based Humanoid Control in AI Robotics를 전공하고 있는 이민경입니다. 2020년에 잠시 추천시스템에 흥미가 생겨서 개인적으로 공부했습니다. 다양한 딥러닝, 로보틱스 관련 공부도 하면서 논문들 읽고 재구현하는 것을 좋아해요.
 Email: blossominkyung@gmail.com
Email: blossominkyung@gmail.com오늘은 2018년 KDD에서 구글이 발표한 "Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts"논문 리뷰를 하려고 합니다. Wide & Deep 모델에 이어서 YouTuebe Recommendation System Trilogy 마지막 논문인 What Video to Watch Next에서 MMoE를 적용했기에 아주 간단하게 정리해 보았습니다.
Index.
최근들어 DNN 모델들이 추천 시스템과 같은 대규모의 애플리케이션들에 성공적으로 적용되고 있다. 이와 같은 추천 시스템은 동시에 여러 목표를 최적화해야 되는 경우가 많다.
예를들어, 사용자들에게 볼만한 영화를 추천하는 경우, 단순하게 영화를 시청하고 구매한 사용자만 고려하면 안된다. 더 나아가 영화를 좋아해서 나중에 더 많은 영화를 보러 올 사용자들도 고려해야 한다. 이를위해, 사용자가 구매한 영화와 매긴 점수를 함께 예측하는 모델이 필요하다.
이와 같은 경우를 위해 멀티 테스크 학습이 필요하다. 멀티 테스크 학습 모델으로 정규화(regularization)와 전이학습(transfer learning)을 활용하여 주어진 테스크 상의 모델 예측을 개선할 수 있다.
그러나 실질적으로 멀티 테스크 학습 모델이 항상 뛰어난 것은 아니다. DNN 기반의 멀티 테스크 학습 모델이 데이터 분포차 나 테스크 간의 관련성과 같은 요인들에 민감하기 때문이다. 이를 해결하기 위해 테스크 당 더 많은 모델 파라미터를 추가하는 경우가 있다. 그러나 대규모 추천시스템은 이미 수백만개의 파라미터들을 내포하기에 추가적인 파라미터는 모델 퀄리티를 현저히 저하시킬 수 있다.
본 논문은 새로운 Multi-gate Mixture-of-Experts기반 Multi-task learning(MMoE)모델을 제안한다.
1. MMoE Architecture
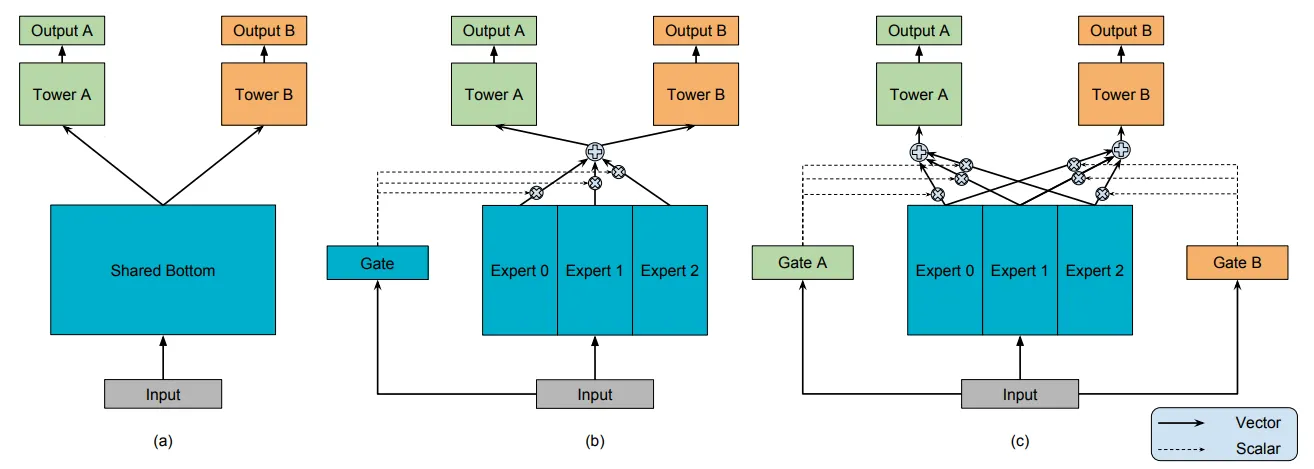
[From the Paper](a) Shared-Bottom model. (b) One-gate MoE model. (c) Multi-gate MoE model
MMoE는 Shared-Bottom multi-task DNN 구조(그림 a 참고)를 기반으로, 모든 테스크에서 하나의 Bottom Network를 공유하는 대신, Expert Network 그룹을 통해 Task를 공유한다. 이때 각각의 Expert는 Feed-Forward Network로 구성되어 있다(그림 c 참고).
각 테스크에 대한 게이트 네트워크는 입력 피처들로 각기 다른 가중치를 가진 Expert를 모아 소프트맥스 게이트를 출력함으로 서로 다른 테스크에서 Expert를 다르게 활용할 수 있도록 한다. 그 후, 모아진 Expert 결과는 테스크 별 타워 네트워크에 전달된다. 이러한 방식을 통해, 서로 다른 테스크에 대한 게이트 네트워크는 Expert에서 모인 서로 다른 혼합 패턴을 학습할 수 있고, 이로인해 테스크 간의 관계도 포착할 수 있다. 이를 위해 피어슨 상관관계(Pearson Correlation)을 사용하였다.
실제로 대규모 컨텐츠 추천시스템에서는 사용자에게 아이템을 추천할 때, 두 가지 분류 과제를 동시에 학습할 수 있도록 MMoE를 테스트한다.
이러한 MMoE 모델이 나오기까지의 과정을 간략하게 살펴보면 다음과 같다.
2. Modeling Approaches
2.1. Mixture-of-Experts(MoE)
•
: experts network
•
: gating network that ensembles the results from all experts
MoE는 MMoE의 근간이 되는 모델이다. 기존 MoE 레이어는 MoE 모델과 동일한 구조를 갖지만 이전 레이어의 출력을 연속 레이어에 대한 입력값과 출력값으로 받아들인다. 그 후 종단간 방식으로 모델 전체를 훈련한다. MoE 레이어의 주요 목표는 네트워크 일부만 활성화 되는 조건부 연산을 달성하는 것이다. 각 입력 예제에 대해 모델은 조건부 게이트 네트워크로 Expert의 서브셋만 선택할 수 있다.
2.2. Multi-gate Mixture-of-Experts(MMoE)
새로 제안하는 MMoE 모델은 Shared-Bottom multi-task 모델에 비해 더 많은 모델 파라미터를 요구하지 않고, Task 간 차이를 알도록 만들어졌다.
MMoE의 핵심 아이디어는 의 Shared-Bottom 네트워크 를 의 MoE 레이어로 대체하는 것이다. 또한 각 테스크 에 대해 별도의 게이트 네트워크 를 추가하는 것이다.
제안하는 MMoE 모델은 기존 MoE와는 다르게 선택적으로 Expert를 선택하고 이전 레이어의 입력값을 그대로 받는다. 이는 멀티 테스크 학습 상황에서 파라미터를 유연하게 공유하는 데 좋은 방법이다. 또한 이를 통해 기존 방법에 비해 훈련하기가 쉬운 모델임을 알 수 있다.
이외에도 게이트 네트워크가 경량 구조이고 Expert 네트워크가 모든 테스크에서 공유되기 때문에 계산상의 장점도 있다. 또한 MMoE의 경우, 게이트 네트워크를 희소한 top-k 모델로 만들어 한층 더 뛰어난 연산 효율성을 달성할 수도 있다.
그러나 본 글은 YouTube Trilogy 마지막 논문을 이해할 수 있을 정도로만 모델 설명만 하였다. MMoE의 경우 논문 그림만 보아도 대략적으로 어떤 모델인지 알 수 있다. 따라서 실험 세팅/성능 평가 부분이 궁금하다면 링크로 걸어둔 논문을 참고하면 좋을 듯 하다. 당연히 성능 평가에 대한 결과는 "Accuracy is good!" 이다.
다음 글로는 Wide and Deep Learning과 MMoE를 적용한 YouTube 추천시스템 "What Video to Watch Next"를 작성하며 YouTube 추천시스템 Trilogy의 마무리를 지어보려 한다.