
2022년 IROS에서 Amazon Alexa AI가 발표한 논문에 대해 정리한 글입니다.
 Summary
Summary•
DialFRED는 ALFRED를 기반으로한 agent가 사람 사용자에게 적극적으로 질문할 수 있고, 사용자의 응답에서 추가된 정보로 agent가 주어진 테스크를 더 잘 수행하는데 사용될 수 있도록 한다.
•
Affordance-aware Multimodal Neural SLAM은 agent가 주어진 환경에서 지도되지 않은 곳을 탐색하고 다양한 테스크를 수행하는 문제를 해결하고자 한다. 이를 위해 멀티모달로 로봇의 위치를 추정하는 Neural SLAM 모델을 제안하고, 이를 통해 로봇의 행동을 결정하는 알고리즘을 학습한다. 특히 로봇이 환경에서 수행할 수 있는 액션에 대한 affordance 정보를 고려하여 알고리즘을 설계했다.
Insights•
DialFRED
1.
구체화된 지시를 더 잘 따르기 위해 agent와 사람 간의 대화 사용 효과
2.
올바른 질문을 하는 것의 중요성
3.
사람이 주석을 단 데이터셋을 사용해서 사람이 테스크 지향적인 질문을 하고 대답하는 방식 모델링
•
AMSLAM
1.
정교한 affordance 인식 네비게이션을 지원하기 위해 agent가 상호작용할 수 있는 관점에서 객체 정보를 추정하는 affordance 인식 의미 표현
2.
언어 지시, 시각적 입력, 이전에 탐색한 영역의 지시를 받아 탐색의 효과 및 효율성을 개선하는 테스크 중심의 멀티모달 탐색
Future works•
DialFRED
1.
정교한 질문 생성 기법 탐구
2.
테스크 성능 향상을 위한 멀티모달 입력의 사용 조사
3.
환경에 대해 심층적 이해가 필요한 복잡한 테스크 개발
•
AMSLAM
1.
agent 성능 향상을 위해 오디오/햅틱 피드백 등 추가적인 모달리티 사용 탐색
2.
탐색 전략을 최적화하고 일반화를 개선하기 위해 강화학습 기법 사용
대화형 시뮬레이션 환경에서 네비게이션 및 객체 조작과 관련된 멀티모달 테스크의 이슈를 해결할 수 있도록 AI를 통해 agent를 훈련해야 하는데. 구체적으로는 agent 개발을 위해 long-horizon planning, vision-language grounding, sample-efficient algorithms 개발이 필요하다.
이와 관련되서 Amazon Alexa AI 팀이 작년에 발표한 두 논문이 있는데 이번 글에서 이들을 소개하려고 한다.


•
DialFRED는 agent가 사용자와 능동적으로 대화하고 그 결과 정보를 사용하여 테스크를 더 잘 완료할 수 있도록 지원한다.
•
Affordance-aware SLAM은 agent의 계획과 네비게이션 수행 능력을 개선하기 위해 제안됐다. 즉 환경 안의 객체를 어떻게 사용할 수 있는지 모델링하는 접근방식을 통해 로컬라이제이션 및 매핑(SLAM)을 수행하는데. 이는 탐색에 vision과 language를 모두 사용하는 최초의 affordance 인식 모델이다.
DialFRED
Problem Statement
•
자연어 지시의 경우
◦
다음과 같은 두가지 챌린지가 있는데.
1.
자연어의 모호함을 해결하고 복잡한 환경에서 지시를 행동으로 매핑하는 것
2.
장기적인 행동 시퀀스를 계획하고 가능한 여러 실패들로부터 복구하는 것
이러한 챌린지로 인해 agent 혼자서 테스크를 처리하는 것이 어려운 경우 존재
•
agent의 경우
◦
사람에게 적극적으로 질문하고 언어적 응답을 활용하여 의도를 이해하고 테스크를 수행하는 데 어려움을 극복할 수 있어야 함.
Proposed Approach
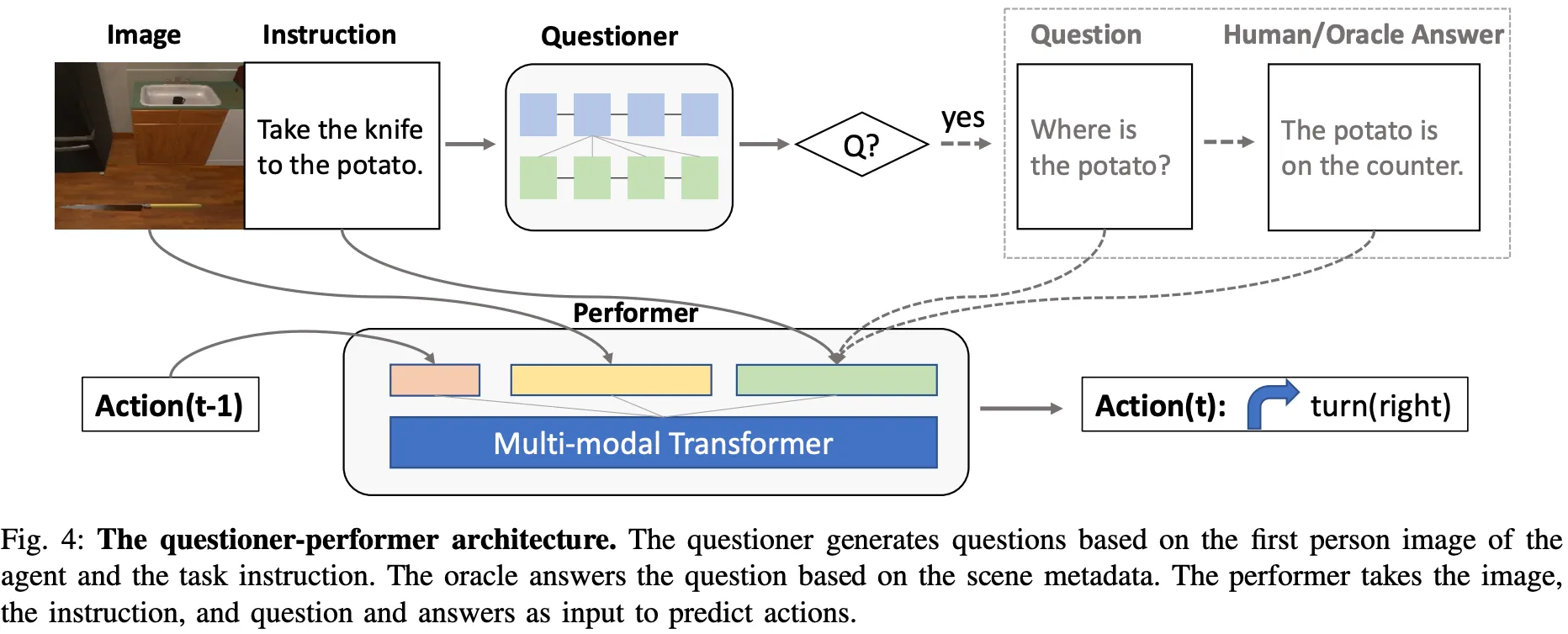
•
Agent가 사람에게 적극적으로 질문하고, 사람의 응답에 포함된 정보를 사용하여 테스크를 잘 완료해야 한다. 이때 agent의 목표는 일련의 테스크를 수행하여 환경 상태를 타겟에 맞게 변경하는 것으로. 자연어 지시가 주어지면 agent는 사람에게 질문하거나 질의응답과 함께 원래 지시의 정보를 바탕으로 주어진 환경에서 물리적 행동을 실행할 수 있어야 한다.
◦
여러 테스크 유형에 대해 기존 연구인 ALFRED를 개선.
◦
25가지 유형의 하위 목표 수준으로 테스크 확장.
◦
53,000개의 사람이 주석을 단 테스크 관련 질의응답 제공.
◦
agent와 사람 간의 대화를 촉진. (대화 지원 agent는 사람에게 질문도 가능)
◦
대화를 추가하면 수행 후 지시를 개선하는데 큰 도움이 된다는 것을 보여주는 questioner-performer 프레임워크 모델.
•
DialFRED는 questioner와 performer로 구성됨.
1.
Questioner는 테스크 지시 및 agent 관찰에 기반하여 질문.
•
좋은 questioner는 언제 질문을 해야되고, 어떤 질문을 해야되는지 알고있어서 performer가 테스크를 더 잘 완료할 수 있게 도움.
•
사람이 주석을 단 대화 세션으로 사전학습 되어 언제 질문을 해야할 지 예측. 주어진 상황에 적합한 질문 생성.
•
Quesioner는 다음과 같이 구성됨: (1) Attention이 있는 Seq-to-Seq 아키텍처 기반. (2) LSTM으로 구현된 인코더 및 디코더 모듈 (그림참고)
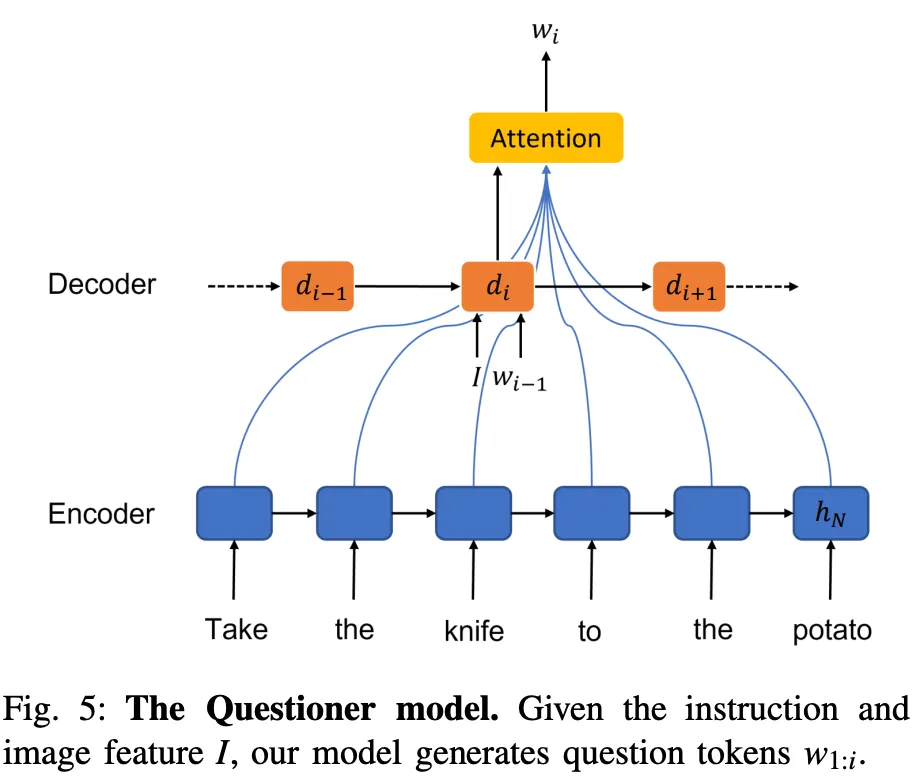
2.
Performer는 원래의 지시와 질의응답을 기반으로 환경에서 실행할 일련의 테스크들을 예측.
•
지시와 QA, 시각적 관찰 및 행동의 전체 히스토리를 인코딩해서 미래의 행동을 예측하는 Attention-based multi-layer transformer 모델인 Episodic Transformer 기반
•
Questioner fine-tuning using RL
◦
Questioner의 목표는 Performer가 테스크를 완료하도록 필요한 질문을 하는 것.
◦
강화학습을 통해 Questioner를 파인튜닝하여 언제 질문을 하고, 분할된 검증에서 어떤 질문을 해야하는 지 학습할 수 있음.
◦
구현된 대화 agent를 훈련하기 위해 대화형 Q&A 프렘워크 제공
▪
시뮬레이션 환경의 실사 기반 메타데이터를 사용하여 생성된 질문에 대한 답변을 자동으로 생성하는 오라클 포함.
▪
Q&A 학습은 Markov Decision Process로 모델링.
◦
Questioner 모델은 각 상태 벡터를 확률적 질문 정책에 매핑하는 정책 네트워크로 리워드 함수를 기반으로 학습하여 질문 수와 성과 이득 간의 균형을 맞춤.
▪
리워드 함수 구조: 과제 완료 리워드, 질문 당 패널티, 무효 질문 패널티
▪
리워드 함수: Actor-Critic 손실 함수로 그레디언트는 모델이 올바른 시간에 필요한 질문을 하는 법을 할 수 있도록 업데이트하는 데 사용됨.
◦
Questioner 파인튜닝 중에는 Performer 모델이 업데이트되지 않음.
Data collection
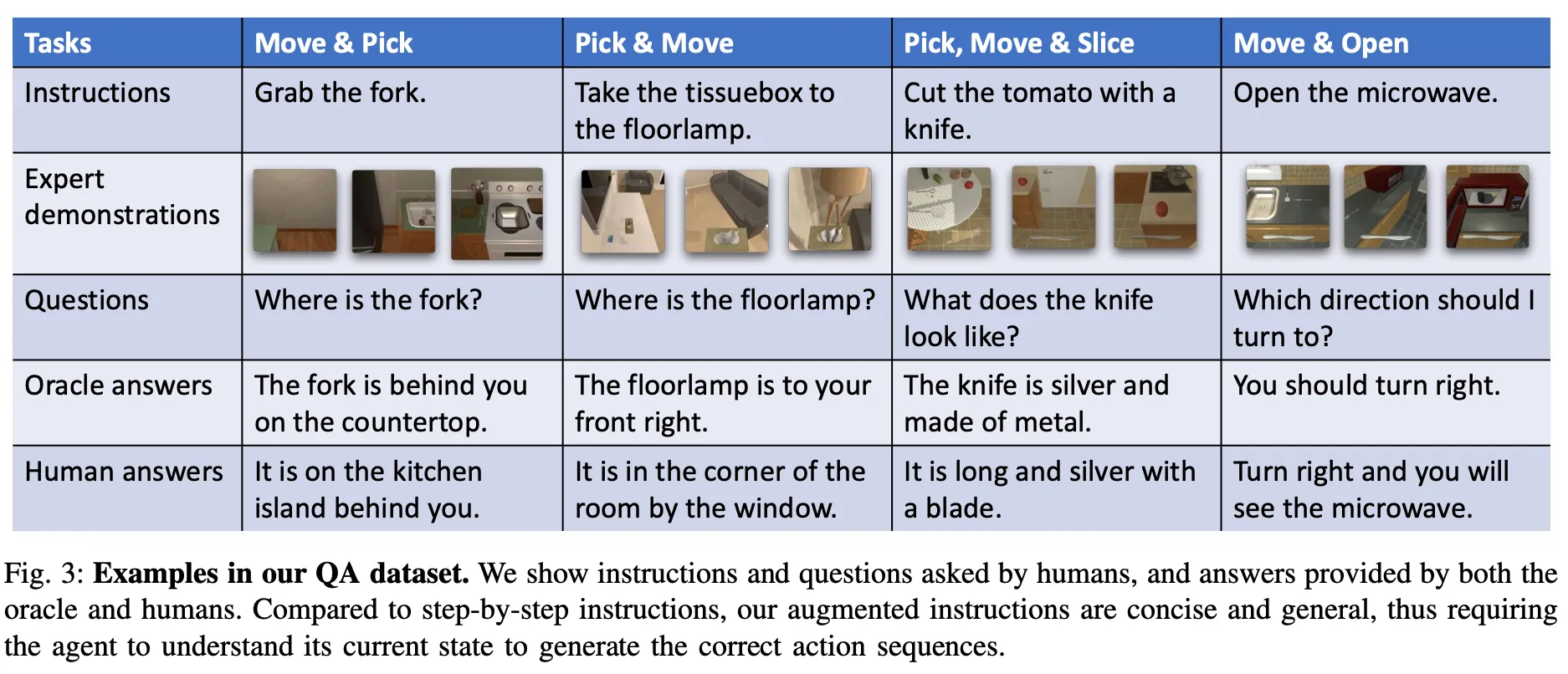
•
Amazon Mechanical Turk를 사용해서 데이터 수집을 위한 새롭고 저렴하며 확장 가능한 방법을 고안. (이전처럼 데이터 수집을 위해 두 사람을 짝지어주는 복잡한 서비스 불필요)
◦
29,376개의 하위목표에 대한 사람의 질의응답 수집
◦
각 하위목표에 대한 두명의 다른 어노테이터에게 질의응답 제공 요청
◦
서로 다른 어노테이터들 간의 질문 선택에 대한 적정한 수준의 일치
•
사람 답변 외에도 agent가 더 쉽게 이해할 수 있도록 템플릿화된 답변을 제공하는 오라클 구축. (위 표는 몇가지 테스크에 대해 오라클이 생성한 답변 보여줌.)
◦
객체 위치에 대답하기 위해 agent를 기준으로 객체의 방향과 객체 장소 계산
◦
객체 생김새 질문에 답하기 위해 색상과 재질에 초점 맞춰 대답
▪
객체 재질은 AI2-Thor의 씬 메타데이터에서 추출
▪
객체 색상은 이미지에서 픽셀 RGB 값 추축하여 색이름에 매핑
▪
방향은 테스크 종료 시점의 agent 위치를 agent의 초기 위치와 비교
Affordance-aware SLAM
Problem Statement
1.
효율적인 탐색 — 주어진 환경에서 지도되지 않은 곳 탐색.
2.
일반화 — 다앙한 테스크를 수행하는 문제 해결.
3.
장기적 계획
4.
추론 시 획득한 시맨틱 맵은 아래 두 가지 이유로 이상적이지 않음.
•
1) 불완전성 — 장면 탐색이 충분하지 않아 정보 누락과
•
2) 부정확성 — 작은 객체의 경우 맵에서 객체 위치 예측 오류
Proposed Approach
지시에 따라 작업을 수행하는 agent를 만들려면 affordance 인식 네비게이션 즉 장시간 방황하지 않고 액션에 대한 행동유도 정보를 인식하는 네비게이션을 수행할 수 있어야 한다. 이를 위해 Planning과 Navigation 성능에 집중해야 하는데. 이 논문은 처음으로 탐색을 위해 여러 모달리티를 활용하고 affordance 인식 시맨틱 맵을 예측하며 동시에 계획하는 Neural SLAM 접근법을 제안한다
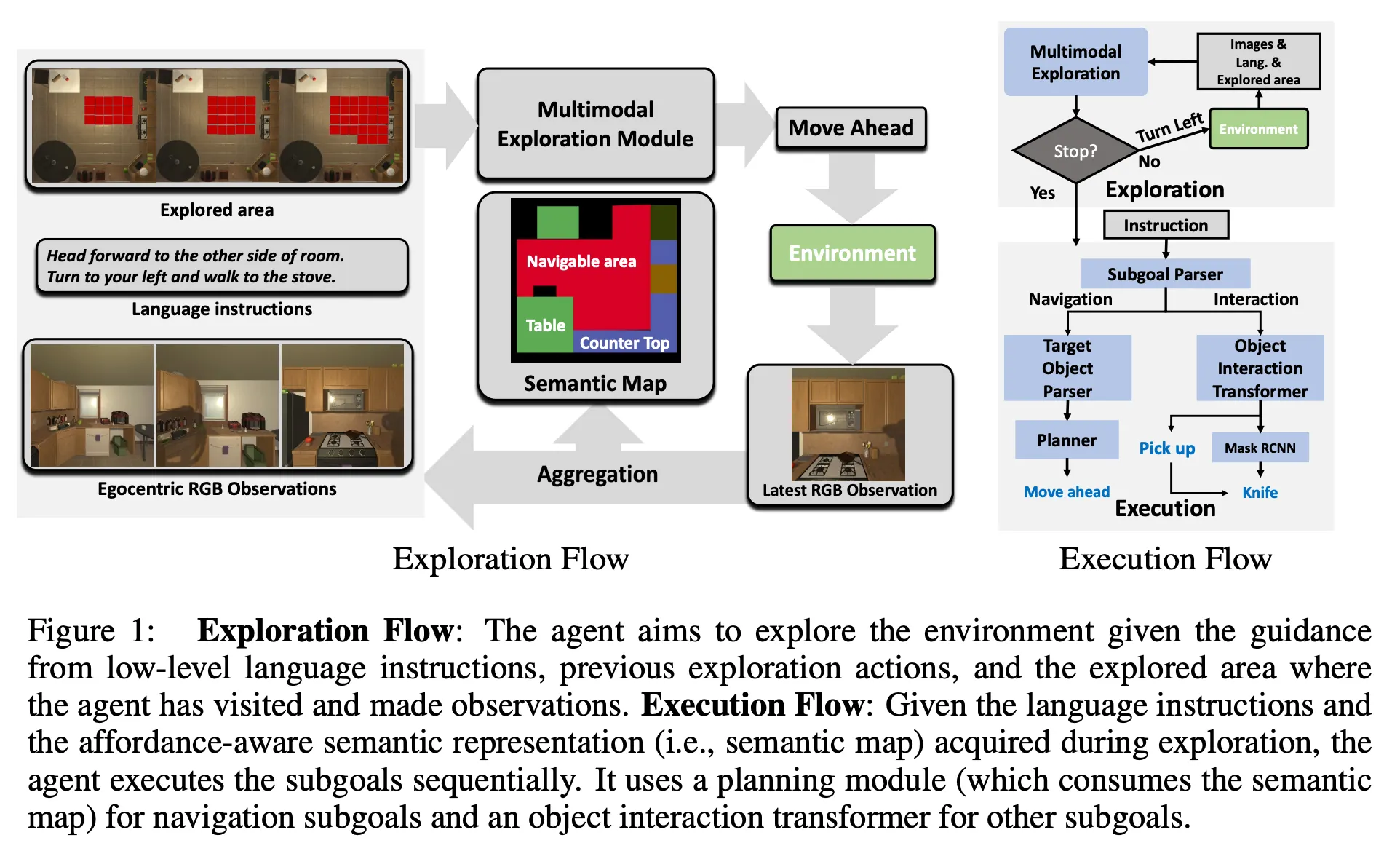
논문이 제안하는 Affordance-aware Multimodal Neural SLAM (AMSLAM)은 — (1)장기적 계획 (2)효율적인 탐색 (3)일반화 —챌린지를 해결하기 위해 아래와 같은 두가지 인사이트로 구현됐다.
1.
Affordance-aware Semantic Representation
•
장거리 네비게이션 및 상호작용 테스크를 해결하는 데 가장 큰 병목현상은 정교한 Affordance 인식 네비게이션. 객체의 정확한 공간 좌표를 알기 위해 정확한 깊이 정보 필요. Affordance 인식 네비게이션은 기본적으로 타겟 객체와의 상호작용에 적합한 agent의 포즈 요구하기에 coarse 공간 정보만 필요.
•
agent는 타겟 객체의 정확한 위치가 아니라, 타겟 객체에 대한 잠재적인 후속 동작이 가능한 위치와 포즈(waypoint) 필요.
◦
waypoint는 각 객체 유형이 상호작용 가능한 agent의 포즈로, 예를 들어 agent가 냉장고 안에 손을 넣을 수 있는 특정 포즈 등을 의미.
◦
경로 계획을 통해 네비게이션을 합리적으로 해결할 수 있도록 waypoints 생성을 지원하는 맵 표현을 개발하는 것이 목표. 즉 네비게이션을 여러 waypoints 간의 경로 계획 문제로 처리
▪
waypoints 생성 위해, 큰 객체와 작은 객체 다르게 처리함.
▪
큰 객체 — CNN 기반 네트워크가 전방 카메라 이미지에서 예측 & 집계한 2d 그리그 맵을 사용하여 계산
▪
작은 객체 — 사전 학습된 Mask RCNN 사용 & 탐색 단계에서 획든한 모든 관찰 직접 검색
▪
이 표현은 agent가 상호작용할 수 있는 위치를 기준으로 객체 정보 추정하여 정교한 affordance 인식 네비게이션을 지원
•
Affordance 인식 시맨틱 표현은 agent가 목표를 달성하기 위해 보다 효과적이고 효율적인 환경을 탐색할 수 있도록 하는 데 중요한 역할 수행. 이를 통해 앞서 언급한 부정확성 문제 또한 해결할 수 있음.
2.
Task-driven Multimodal Exploration
•
언어 지시, 시각적 입력, 이전에 탐색한 영역에 대한 가이드를 받아 탐색의 효과 및 효율성 개선.
•
멀티모달 탐색 모듈은 학습되거나 사전학습/고정된 여러 하위 모듈로 구성됨.
◦
여기서 멀티모달은 카메라, 깊이 센서, 로봇의 상태 정보 등을 의미.
•
멀티모달 탐색 모듈은 각 단계에서 과거의 시각적 관찰 및 행동, 단계별 언어 지시, agent가 방문한 위치를 표기하는 탐색 영역 맵을 사용해서 탐색 해동응ㄹ 예측하는데, 이를 통해 앞서 언급한 불완전성 문제를 해결 할 수 있음.
•
높은 수준에서 테스크가 주어지면 탐색은 하위목표 파서가 네비게이션 하위 목표를 하나씩 살펴보고 하위목표 파서가 하위목표 네비게이션에 적합한지 여부를 예측.
•
모듈은 네비게이션 하위 목표에 대한 탐색 액션을 자동 회귀적으로 예측.
•
agent가 목표를 달성하기 위해 보다 효율적이고 효과적으로 환경을 탐색할 수 있도록 하는데 중요한 역할을 담당.
◦
낮은 수준의 언어 지시를 사용하면 더 많은 탐색 행동 예측 가능.
◦
추가적인 탐색 영역은 agent에게 명시적인 공간 정보를 제공하여 탐색 용이하게 함.
이번 글에서는 대화형 시뮬레이션 환경에서 멀티모달 테스크 이슈를 해결하기 위한 agent 개발과 관련된 두 논문을 살펴보았다.
두 논문의 모델만 소개하고 성능평가 부분은 생략했는데. 간단하게 두 논문의 한계점에 대해서만 정리하자면, DialFRED의 경우 가정용 테스크만 지원하기에 일반화 하기 어렵고, 질문에 답하기 위해 오라클에 의존하기 때문에 리얼월드에서 오라클이 부재할 경우 해당 모델을 사용하기 어렵다는 한계가 존재한다.
AMSLAM의 경우, 현재 사전에 정의된 affordance나 객체 범주에 의존하기 때문에 미리 정의되지 않은 더 복잡한 환경이나 테스크에서는 충분하지 않을 수 있다. 또한 장기적 계획과 추론 처리가 가능하지만 이 역시 보다 복잡한 추론이나 의사결정이 필요한 테스크에서는 가능하지 않을 수 있고, 계산 비용이 많이 들고 훈련 및 배포에 드는 리소스도 많다는 한계가 존재한다.
그럼에도 두 논문이 갖는 공통된 의의는 일반화 할 수 있는 장거리 계획을 세울 수 있다는 점이라고 생각한다.