




안녕하세요. Physics-based Humanoid Control in AI Robotics를 전공하고 있는 이민경입니다. 2020년에 잠시 추천시스템에 흥미가 생겨서 개인적으로 공부했습니다. 다양한 딥러닝, 로보틱스 관련 공부도 하면서 논문들 읽고 재구현하는 것을 좋아해요.
 Email: blossominkyung@gmail.com
Email: blossominkyung@gmail.com오늘은 2016년 Google이 발표한 Wide & Deep Learning for Recommender Systems를 리뷰하려고 한다. YouTuebe Recommendation System Trilogy 마지막 논문인 What Video to Watch Next에서 Wide & Deep 모델 확장하고 있어서 겸사겸사 공부하며 리뷰를 해보려고 한다.
Content
Wide & Deep Learning Model은 실제로 구글 플레이 스토어 앱에 적용된 랭킹 알고리즘이다. 이 논문은 선형 모델과 신경망을 함께 훈련하는 하나의 모델을 제안하여 Memorization과 Generalization 둘다를 얻는 이슈에 중점을 두고 있다.
앞서 말했듯 구글 플레이 스토어 앱의 추천엔진을 위한 논문이기에 추천할 대상이 이미 정해진 상태로 제안된 모델이다. 다시말해 플레이 스토어 앱 검색 관련 사용자 및 사용자 정보 관련 쿼리를 추천 랭킹 하는 것이 본 논문의 제안 사항이라는 것을 알고 논문을 보면 좋다.
1. Recommender System Overview
다른 논문들과는 다르게 이 논문은 친절하게도 구글 플레이 스토어 앱의 전반적인 추천엔진을 다음 그림과 함께 설명해준다.
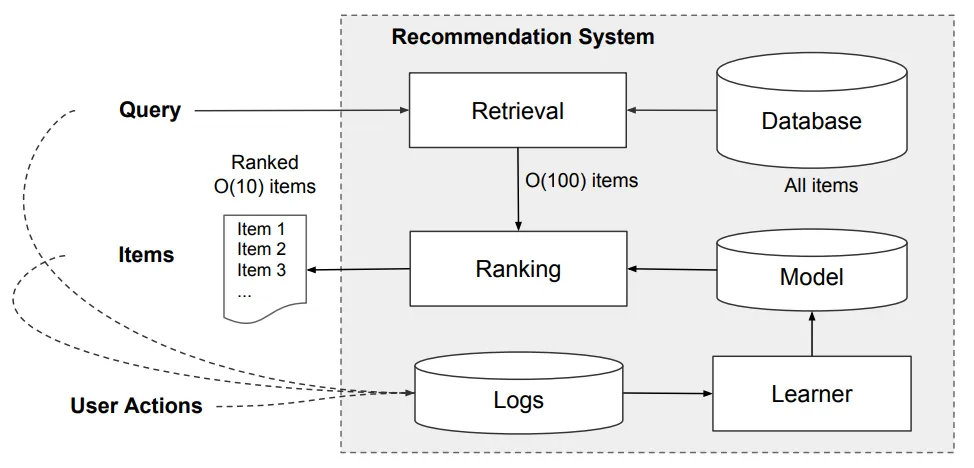
[From The Paper] Overview of Recommender System.
그림의 과정을 간략하게 설명하면, 사용자가 앱 스토어에 방문했을 때 사용자와 관련 정보를 포함한 쿼리가 생성된다. 추천 시스템은 클릭 또는 구매와 같이 사용자 행동들이 있는 앱 리스트를 반환한다. 이와 같은 사용자 행동들은 learner를 위한 훈련데이터로 로그에 기록된다. 그러나 DB에 백만개가 넘는 앱이 있기에, serving latency 내에서 모든 쿼리에 대하여 모든 앱에 점수를 주는 것이 어렵다.
따라서 쿼리를 받는 첫 번째 단계는 Retrieval이다. 검색 시스템은 일반적으로 머신 러닝 모델과 사람이 정의한 규칙의 조합을 사용하여 쿼리와 가장 일치하는 항목들을 반환한다. candidate pool을 줄인 후, 랭킹 시스템은 점수에 따라 모든 항목들의 순위를 매긴다. 여기서 점수는 보통 로 user feature, contextual feature, impression feature을 포함하는 feature 가 주어진 사용자 행동 레이블 의 확률로 계산한다. (user feature는 국가, 언어, 인구통계 등의 정보를 담고 있고, contextual feature는 기기, 하루 사용 시간, 주간 사용 시간 등을, impression feature는 앱 사용기간, 앱 통계 등을 담고 있다.)
이와같은 추천엔진을 토대로 이 논문은 Wide & Deep Learning을 사용한 랭킹 모델을 제안한다.
2. Wide & Deep Learning
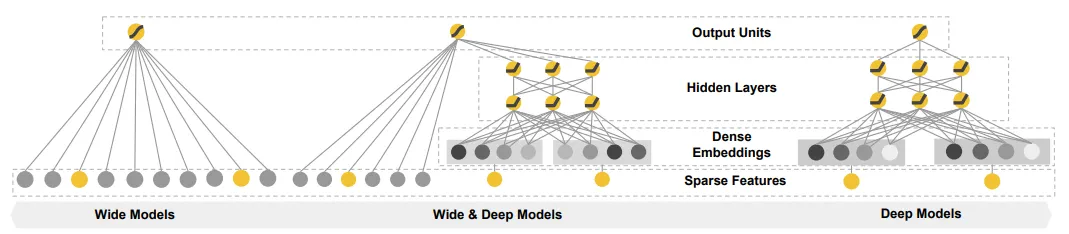
[From The Paper] The Spectrum of Wide & Deep Model.
2.1. The Wide Component
위의 그림과 같이 Wide Model은 형태의 일반적인 선형 모델이다. 사용되는 feature set은 Raw Input feature와 Transformed feature를 포함하고 있다. 이때 가장 중요한 transformation은 cross-product transformation으로 다음과 같이 나타낼 수 있다.
Binary feature에 따라 구성하는 feature가 모두 1인 경우에만 cross-product transformation은 1이다. 예를 들어, AND(gender=female, language=en)를 구성하는 (gender=female)과 (language=en)이 모두 성립되어야 AND(gender=female, language=en)가 성립된다.
2.2. The Deep Component
위의 오른쪽 그림과 같이 Deep Model은 Feed-Forward Neural Network이다. categorical feature들로 인해 초기 입력값은 (language=en)과 같이 feature string이다. 각각의 희소하고 고차원의 categorical feature들은 먼저 Dese Embedding에서 low-dimensional and dense real-valued vetor로 전환된다. 임베딩 차원은 주로 에서 순으로 주어진다. 임베딩 벡터는 무작위로 초기화 된 후, 모델 훈련 중에 손실함수 마지막 값을 최소화하도록 훈련된다. 그 후, 저차원의 밀집 임베딩 벡터는 Hidden Layer에 입력된다. 이때 Hidden Layer에서는 다음과 같은 과정을 수행한다.
이때 은 레이어 갯수이고, 는 활성함수로 ReLU 함수이다.
2.3. Joint Training of Wide & Deep Model
Wide모델과 Deep모델은 Joint Training을 위해 하나의 로지스틱 손실 함수에 들어가는 예측으로 Output Log Odds의 가중치 합을 사용하여 결합된다.
이때 Ensemble이 아닌 Joint Training을 사용한 이유는 다음과 같다.
•
Joint Training은 훈련 시간에 합계의 가중치 뿐만 아니라 Wide & Deep의 모든 파라미터들을 동시에 최적화한다.
•
Joint Training의 경우, wide model은 소수의 cross-product feature transformation으로 deep model의 약점만 보완하면 된다.
Wide & Deep model Joint Training은 미니배치 확률적 최적화(mini-batch stochastic optimization)를 사용하여 output에서 wide와 deep으로 동시에 gradient를 역전파(backpropagation)하여 수행된다. 본 논문에서는 Deep model에 AdaGrad를, Wide model에는 L1 regularization을 최적화 알고리즘으로 적용하며 Follow-the-regularized-leader 알고리즘을 함께 사용하였다.
로지스틱 회귀의 경우 Wide & Deep 모델 예측은 다음과 같다.
•
- sigmoid 함수
•
- 초기 feature 의 cross product transformation
•
- Wide 모델 전체 가중치 벡터
•
- 마지막 활성함수 가 적용된 가중치
3. System Implementation
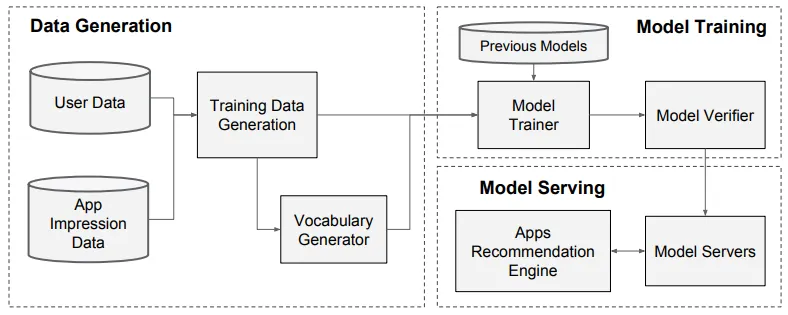
[From the Paper] Apps Recommendation Pipeline Overview
3.1. Data Generation
특정 시간 동안 사용자와 앱 노출 데이터를 통해 훈련 데이터를 생성한다. 이때 레이블은 app acquisition인데, 1이면 노출된 앱이 설치되었다는 것을 의미한다. 범주형 피처 문자열을 정수 ID로 매핑하는 테이블인 Vocabularies도 Data Generation 단계에서 생성된다.
3.2. Model Training
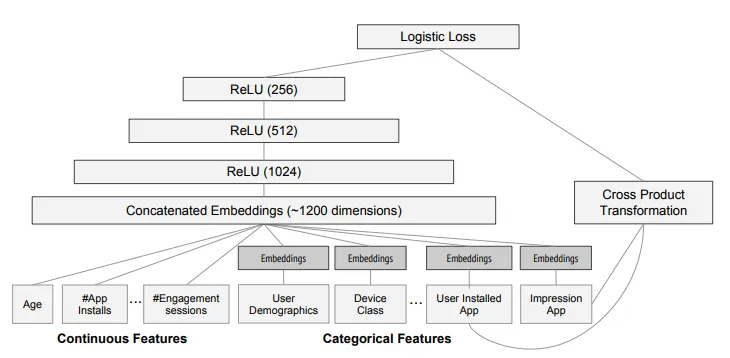
[From the Paper] Wide & Deep model structure for app recommendation.
본 논문의 구현 파트에서 사용된 모델 구조는 위의 그림과 같다. 그림과 같이, 훈련 중에 입력 레이어는 훈련 데이터와 Vocabularies를 가져와 레이블과 함께 희소하고 밀집한 피처들을 생성한다.
Wide Component는 설치된 앱의 사용자와 노출 앱들의 cross-product transformation으로 구성되어 있고, Deep Component의 경우 32 차원의 임베딩 벡터가 각각의 범주형 피처들에 대해 학습한다. Wide & Deep 모델은 5000억개 이상의 사례들로 훈련된다. 이때 기존 모델의 경우 새로운 학습 데이터셋이 생성될 때마다 모델을 다시 학습해야한다. 그러나 매번 처음부터 다시 학습해야 되기 때문에 비용과 지연시간 문제가 발생한다.
따라서 본 논문은 이전 모델의 임베딩과 선형 모델 가중치로 새로운 모델을 초기화하는 warm-starting 시스템을 구현했다.
3.3. Model Serving
모델이 훈련되고 검증되면, model serving을 해야한다. 각 요청에 대해 서버는 앱 검색 및 사용자 피처로부터 앱 후보셋을 받아서 각 앱에 점수를 매긴다. 그러면 최고점부터 최저점까지 앱에 대한 랭킹이 매겨지고, 이것을 사용자들에게 공개한다.
이때 각 요청을 10ms로 처리하기 위해 단일 배치 추론 단계에서 모든 후보 앱의 점수를 매기는 대신, 더 작은 배치를 병렬로 실행하여 멀티쓰레드 병렬처리 방법으로 성능을 최적화한다.
논문의 나머지 부분은 Experiement Results와 Conclusion 부분이라 생략한다.
해당 논문을 리뷰하게 된 이유는 앞서 말했듯 YouTube RecSys Trilogy의 마지막 논문 모델에서 Wide & Deep 모델을 참고하고 있기 때문이다. 그러나 해당 논문에서 Wide&Deep 모델을 자세히 설명하고 있지 않는다. 따라서 이번 글은 Wide&Deep 모델의 구조를 알아보고자 작성하였다.