




안녕하세요. Physics-based Humanoid Control in AI Robotics를 전공하고 있는 이민경입니다. 2020년에 잠시 추천시스템에 흥미가 생겨서 개인적으로 공부했습니다. 다양한 딥러닝, 로보틱스 관련 공부도 하면서 논문들 읽고 재구현하는 것을 좋아해요.
 Email: blossominkyung@gmail.com
Email: blossominkyung@gmail.comYouTube Recommendation System Trilogy
1 - The YouTube Video RecSys
2 - Deep Neural Networks for YouTube Recommendations
3 - What Video to Watch Next : YouTube
•
YouTube RecSys Trilogy 2번째 논문 : Deep Neural Networks를 적용한 추천 시스템 논문으로 유명한 "Deep Neural Networks for YouTube Recommendations" 리뷰 입니다.
Summary
본 논문은 두 개의 신경망, "후보군 생성 네트워크" 및 "랭킹 네트워크" 모델을 통해 유튜브 동영상을 추천하는 방안을 제안하고 있다.
1) 후보군 생성 네트워크 :: 언어 모델링에 사용되는 임베딩 방법에 Dense Representation을 사용한 Input으로 사용하고 Nearest Negihbor Search 알고리즘을 적용
2) 랭킹 네트워크 :: 시청 시간을 예측하는 Logistic Regression을 적용하여 후보군 생성 네트워크에서 형성된 후보 가운데 사용자에게 노출할 동영상들을 결정하는 모델을 학습
Content
1. Introduction
YouTube는 비디오 컨텐츠 제작 및 공유 플랫폼으로, 사용자 개개인들이 원하는 비디오를 추천 할 수 있어야 한다. 그러나 YouTube 비디오 컨텐츠 추천은 다음과 같은 세 가지 중요 문제를 가지고 있다
(1) Scale
(2) Freshness
(3) Noise
본 논문은 YouTube 비디오 추천 시스템에 큰 영향을 끼친 비디오 추천 시스템에 딥러닝을 적용한 방안에 대해 이야기하며 -Candidate generation 과 Ranking- 중 Candidate generation에 중점을 두고 설명하고 있다.
2. System Overview
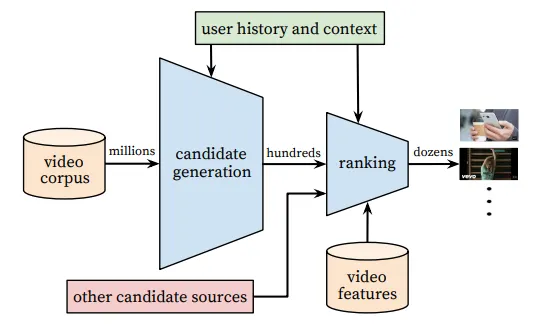
Overall proposed architecutre
그림과 같이 제안하는 시스템은 두 개의 신경망으로 구성된다 - 후보군 생성 & 랭킹 네트워크
•
후보군 생성 네트워크
후보군 생성 네트워크는 Input 값으로 사용자의 YouTube 활동 기록 이벤트를 가져온다. 이벤트라는 큰 코퍼스에서 동영상의 수백 개의 작은 하위 집합들을 검색한다. 이와 같이 형성된 후보군들은 높은 정밀도(precision)로 사용자와 관련이 있다. 또한 협업 필터링을 통해서만 광범위한 개인 맞춤 시스템을 제공한다. 이때 사용자 간의 유사성은 비디오 시청 아이디, 검색 쿼리 토큰 및 인구 통계 등과 같이 조잡한 피처들로 표현된다.
•
랭킹 네트워크
랭킹 네트워크는 비디오와 사용자를 설명하는 다양한 피처들을 통해서 원하는 objective function에 따라 각 비디오에 점수를 할당하는 방식으로 테스크를 수행한다. 점수에 따라 순위가 매겨지므로, 가장 높은 점수를 받는 비디오는 사용자에게 표시된다.
이처럼 2 단계 접근 방식을 사용하게 되면, 사용자 기기에 표시되는 소수의 동영상이 사용자 별 개인추천이 되고, 이를 통해 사용자에게 수백만에 다다르는 동영상들을 추천할 수 있다. 또한 다른 소스들에서 생성된 후보들과도 혼합하는 방식을 통해서 사용자를 위한 또다른 영상들을 추천할 수 있게 된다. (늘 뜨는 것만 뜨는 알고리즘의 늪에서 나오기 위한 방식 같다.)
본 논문은 시스템의 반복적인 업데이트를 가이드하기 위해 정밀도, 회상, 랭킹 손실 등 여러 오프라인 메트릭을 광범위하게 사용한다. 최종적으로 제안하는 사항을 효과를 검증하기 위해서는 라이브 실험을 통한 A/B 테스트를 진행한다.
3. Candidate Generation
3.1 Recommendation as Classification
후보군 생성 네트워크는 사용자와 관련 있을 만한 수백 개의 동영상으로 YouTube 코퍼스를 분류한다. 극단적인 다중 클래스 분류로 추천 시스템을 간주한다. 여기서 다중 클래스 분류는 예측 문제가 사용자()와 컨텍스트()를 기반으로 코퍼스()에서 수백만 개의 비디오( )중 시간()에 시청한 특정 비디오 를 정확하게 분류하는 것을 뜻한다.
•
: 사용자의 고차원적 'Embedding'
•
: 각 후보 비디오의 'Embedding'
해당 세팅에서 임베딩은 단순하게 개별 비디오, 사용자들 등 희소한 엔티티들을 의 고밀도 벡터로 매핑하는 것이다. 심층 신경망의 테스크는 Softmax 분류기를 사용하여 동영상을 구별하는데 유용한 사용자 기록 및 컨텍스트의 함수로서 사용자 임베딩 를 학습하는 것이다.
YouTube에는 좋아요/싫어요, 설문조사 등의 명시적 피드백 메커니즘이 있지만, 본 논문은 비디오를 끝까지 본 사용자의 positive sample에 해당하는 모델을 훈련하기 위해 사용자 시청 암시적 피드백을 사용한다. 이는 더 많은 암시적 사용자 기록을 토대로 하기 때문에, 명시적 피드백이 드문 부분에서도 비디오 추천을 가능하게 한다.
3.1.1 Efficient Extreme Multiclass
수백만 개의 클래스들로 이와 같은 모델을 효율적으로 훈련시키기 위해, 본 논문은 후보 샘플링으로 백그라운드 분포에서 negative 클래스를 샘플링한다. 그 후, 중요도 가중치를 통해 해당 샘플링을 수정한다. 각 example에서 실제 레이블과 샘필링된 negative 클래스에 대한 cross-entropy 손실이 최소화 된다.
서빙 시간에 사용자에게 제시할 상위 N개를 선택하기 위해 가능성 높은 N개의 클래스(비디오)를 계산해야 한다. 수십 밀리초 정도의 서빙 지연시간에서 수백만 개의 아이템들을 평가하려면 클래스 수에서 Sublinear에 가까운 평가 체계가 필요하다. Softmax Output 레이어의 Calibrated Likelihoods는 서빙 시간에 필요하지 않으므로, 평가(점수) 문제는 범용 라이브러리를 사용할 수 있는 내적 공간에서 가장 최근접 이웃 탐색(Nearest Neighbor Search)로 축소된다.(다행히 A/B 테스트 결과는 최근점 이웃 탐색 알고리즘의 선택에 특별히 민감하지는 않다.)
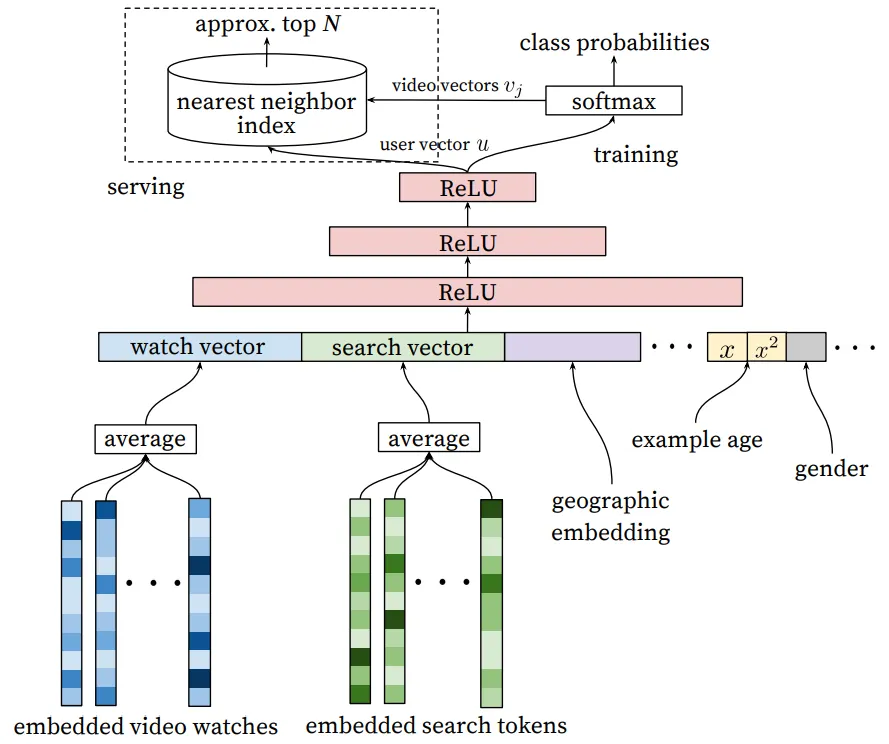
Deep Candidate Generation Model Architecture
•
위 그림은 추가적인 Non-Video 시청 피처들을 포함하는 일반적인 네트워크 아키텍처이다.
3.2 Model Architecture
고정된 어휘로 각 비디오에 대한 고차원 임베딩을 학습하고, 이러한 임베딩을 feedforward 신경망에 공급한다. 사용자의 시청 기록은 임베딩을 통해 밀집 벡터 표현(dense representation)으로 매핑되는 희소한 동영상 ID의 가변 길이 시퀀스로 표현된다. 후보군 생성 네트워크에는 고정된 크기의 밀집 입력값이 필요하고 Sum, Component-wise Max 등 여러 전략들 중 가장 잘 수행된 임베딩을 평균화 해야 한다. 중요한 것은 임베딩이 일반 경사 하강법 역전파 업데이트를 통해 다른 모든 모델의 매개변수와 함께 학습된다는 점이다. 피처들은 넓은 첫 레이어로 연결되고, 그 다음 Fully Connected ReLU 의 여러 레이어로 연결되는 것이 전반적인 후보군 생성 네트워크 모델 아키텍처이다.
3.3 Heterogeneous Signals
Matrix Factorization 중 DNN을 사용하는 경우 "임의의 연속 및 범주형의 피처들을 모델에 쉽게 추가" 할 수 있다.
검색 기록은 시청 기록과 유사하게 처리되는데, 이때 각 쿼리는 유니그램 과 바이그램으로 토큰화되고, 각 토큰은 임베디드 된다. 여기서 평균을 내면, 사용자의 토큰화된 임베디드 쿼리들은 요약된 밀집 검색 기록을 보여준다.
3.3.1 "Example Age" Featrue
매초 마다 많은 분량의 동영상들이 YouTube에 업로드 된다. 최근에 업로드된 Fresh한 콘텐츠를 추천하는 것은 Product로서 YouTube 입장에서는 중요한 일이다. 사용자가 관련 비디오들에 대한 비용을 지불하지 않지만 신선한 컨텐츠를 선호한다는 것을 지속적으로 관찰한다.
단순히 사용자가 보고싶어 하는 새로운 비디오를 추천하는 1차적 효과 외에도, 바이럴 콘텐츠를 부트스트래핑 하고 전파하는 2차적 효과 역시 중요하다.
동영상 인기분포는 매우 Non-Stationary하지만 추천자가 생성한 코퍼스에 대한 다항 분포는 몇 주 동안의 훈련 기간 내 평균 시청 Likelihood를 반영한다. 이를 수정하기 위해, 훈련 중 피처들로 훈련 예제의 Age를 제공한다. 서빙 시간에 피처는 0 또는 음수로 설정되어 모델이 훈련 기간이 끝나는 지점에서 예측한다는 것을 보여준다.
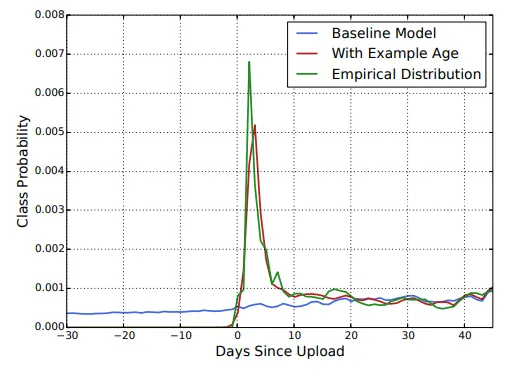
임의로 선택한 비디오에서 Example Age 방식의 효과를 보여준다.
3.4 Label and Context Selection
추천은 종종 Surrogate Problem를 해결하고 결과를 특정 컨텍스트로 전송하는 부분이 포함한다. 이러한 Surrogate Problem 선택은 A/B 테스트 성능에 매우 중요하지만, 오프라인 실험으로는 이를 측정하기가 어렵다.
훈련 사례는 본 논문이 제안하는 추천 사항을 시청하기 보다 모든 YouTube 시청 기록을 통해 생성된다. 그렇지 않으면 새로운 컨텐츠 노출이 현저히 낮고, 추천자가 Exploitation에 지나치게 편향될 수 있다.
Live Metrics를 개선한 또다른 방안으로 사용자 당 고정된 수의 훈련 사례 생성을 통해 손실 함수에서 사용자들에게 균등하게 가중치를 부여하는 방법이 있다. 이 방법을 통해, 손실함수가 매우 활동적인 사용자들로 구성된 작은 집단에 의해 좌지우지하는 것을 방지할 수 있다.
본 논문에서 제안하는 YouTube 추천 모델은 맞춤 동영상 페이지에 나타나는 아이템을 결정하는 것으로, 사용자가 다음에 시청할 동영상을 예측하는 것이다. 따라서 해당 정보가 주어진 분류기는 검색 결과 페이지에 나타나는 동영상이 시청할 확률이 가장 높은 동영상이라 예측할 것이다. 이때 당연히 사용자가 마지막으로 검색한 페이지를 추천 서비스로 제공하면 안된다.
또한 동영상을 시청하는 패턴은 매우 비대칭적으로 다른 사람들과 함께 시청하는 확률들이 있다. 예를 들어, 에피소드 시리즈의 경우, 대게 순차적으로 시청하며, 사용자는 작은 틈새시장에 초점을 맞추기 전에 가장 널리 알려진 장르로 시작하려는 특징을 볼 수 있다.
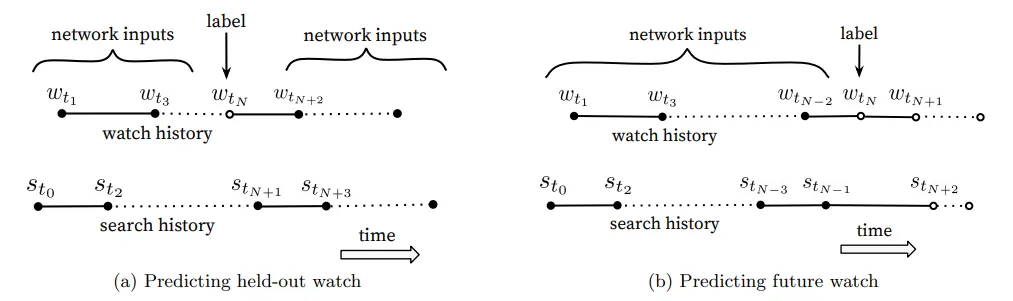
모델에 대한 레이블 및 입력 값을 선택하는 것이 실시간 성능에 큰 영향을 준다는 것을 보여주는 그림.
따라서 위그림 (a)와 같이 사용자가 다음에 시청할 비디오들을 예측하는 것이 성능적 측면에서는 좋다. 또한 많은 협업 필터링 시스템은 임의의 아이템을 잡고, 사용자 기록 내 다른 아이템들에서 예측하여 레이블과 컨텍스트를 암시적으로 선택하는 데, 이 경우 미래 정보를 유출하고 비대칭적 소비 패턴을 무시하게 된다. 이와 반대로, 본 논문은 그림 (a)와 같이 랜덤 시청을 선택하여 사용자의 기록을 롤백하고 보류된 레이블 시청 이전에 사용자가 취한 액션만 입력한다.
3.5 Experiments with Features and Depth
피처와 깊이를 추가하면 아래의 그림과 같이 holdout 데이터의 정밀도가 크게 향상된다.
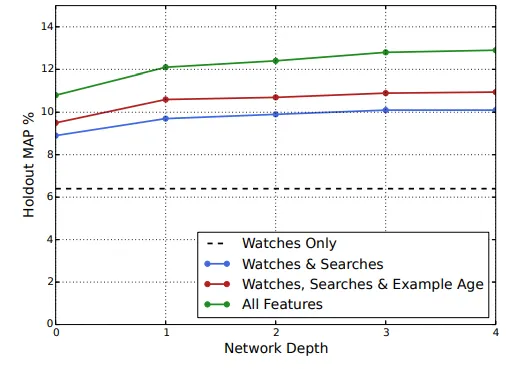
•
Depth 0 : Linear Layer simply transforms the connection layer
•
Depth 1 : 256 ReLU
•
Depth 2 : 512 ReLU → 256 ReLU
•
Depth 3 : 1024 ReLU → 512 ReLU → 256 ReLU
•
Depth 4 : 2048 ReLU → 1024 ReLU → 512 ReLU → 256 ReLU
Depth가 0인 네트워크는 사실상 이전 시스템과 유사한 Linear Fatorization 기법이다. 점진적 이익은 줄어들고 수렴이 어려워질 때까지 폭과 깊이가 추가되는 것을 볼 수 있다.
4. Ranking
랭킹 네트워크는 Impression Data를 사용해서 특정 사용자 인터페이스에 대한 후보 예측을 측정한다. 예를들어, 사용자는 일반적으로 특정 동영상을 높은 확률로 시청할 수 있지만, 썸네일 이미지 선택으로 인해 특정 홈페이지를 클릭할 가능성은 낮다.
따라서 랭킹이 측정되는 동안, 몇백 개의 동영상만 점수가 매겨지므로 동영상과 사용자의 관계를 설명해주는 피처들에 더 많이 액세스 할 수 있다. 또한 랭킹은 직접 비교할 수 없는 여러 후보 소스들을 앙상블링하는 데도 중요하다.
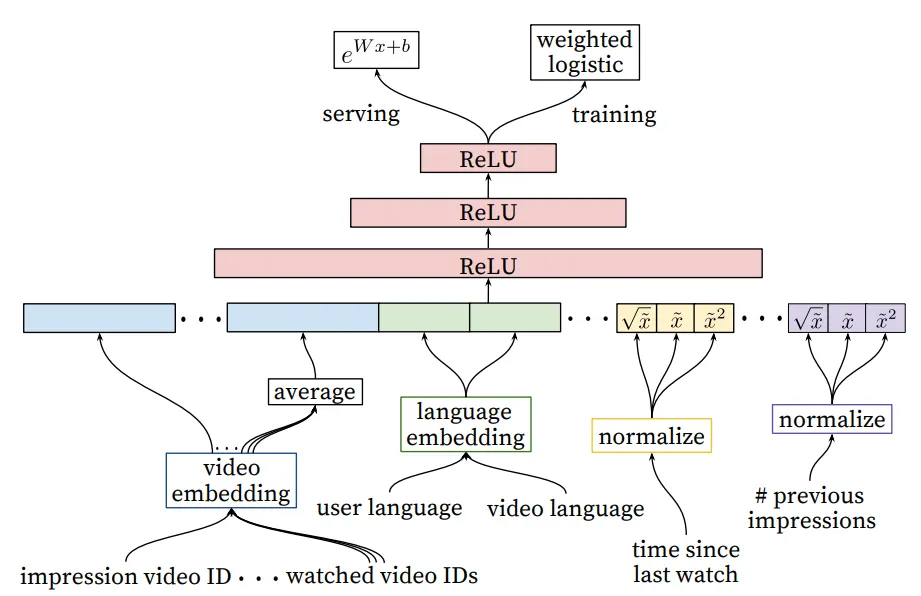
Deep Ranking Network Architecture
랭킹 네트워크는 위 그림과 같이 로지스틱 회귀를 사용하여 각 비디오 노출에 독립적인 점수를 할당하기 위한 후보군 생성과 유사한 아키텍처를 가진 DNN을 사용한다. 랭킹 네트워크 이후, 비디오 목록들은 점수별로 정렬되어 사용자에게 반환된다.
랭킹 네트워크는 실시간 A/B 테스트 결과를 기반으로 지속적으로 조정되지만 노출 당 시청 시간을 나타내는 간단한 함수이다. CTR에 따른 랭킹은 종종 사용자가 끝까지 시청하지 않은 동영상을 추천하지만 시청 시간은 사용자 참여도를 더 잘 표현해준다.
4.1 Featrue Representation
랭킹 네트워크의 피처들은 범주형 및 연속형 피처들로 분리된다. 범주형 피처는 카디널리티가 매우 다양한데 일부는 바이너리(로그인 여부), 일부는 수백만개의 가능한 값(마지막 검색어 등)으로 있다.
피처들은 단일 값에만 기여하는지 아니면 값 세트에 기여하는지에 따라 분할된다. 또한 아이템의 속성(Impression) 또는 사용자 or 컨텍스트의 속성(Query) 설명 여부에 따라 피처를 분류할 수 있다.(이때 쿼리는 요청당 한 번만 계산되는 반면 Impression는 점수가 매겨진 각 아이템에 대해 계산한다.)
일반적으로 랭킹 모델에서 수백 개의 피처들을 사용하면서, 범주형과 연속형을 균등하게 분할한다.
4.1.1. Feature Engineering
DNN이 있지만, Raw Data의 특성으로 인해 Feedforward NN에 직접 입력값을 주는 것은 까다롭다. 여전히 사용자 및 비디오 데이터를 유용한 피처들로 변환하는 엔지니어링 리소스를 사용해야한다. 해결해야할 주된 부분은 사용자 행동의 시간적 시퀀스와 이와 같은 행동들이 점수화된 동영상 노출과 어떻게 관련 있는지 나타내는 것이다. 이때 가장 중요한 시그널은 아이템 자체 및 랭킹 광고 경험과 일치하는 유사 아이템에 대한 사용자의 이전 상호작용이다.
사용자가 현재 채널에서 몇 개의 동영상을 보았는지. 사용자가 유사한 동영상을 마지막으로 본 것이 언제인지 등 관련 아이템에 대한 과거 사용자 행동을 설명하는 연속형 피처는 서로 다른 아이템에서 일반화가 잘 되기 때문에 강력하다.
또한 후보군 생성 네트워크에서 피처의 형태로 랭킹 정보를 전파하는 것 역시 중요하다. 추천 churn을 도입하는데 과거 동영상 노출 빈도를 설명하는 피처들이 중요한 역할을 한다. 사용자에게 최근에 비디오를 추천했지만 사용자가 이를 시청하지 않았다면, 모델은 다음 페이지 로드에서 해당 비디오 노출 빈도를 떨어뜨린다. 최신 노출빈도와 시청기록을 제공하는 것은 엔지니어링 측면에 가깝지만, 반응형 추천 시스템을 생성하는데 상당히 중요하다.
4.1.2. Embedding Categorical Featrues
임베딩을 사용해서 희소한 범주현 피쳐들을 신경망에 적합한 Dense Representation에 매핑한다. 각각의 고유한 ID 공간("vocabulary")에는 별도의 학습된 임베딩이 있다. 이때 해당 임베딩은 고유 값 수의 로그에 근접하게 비례하여 증가하는 차원을 가지고 있다. 이러한 ID 공간("vocabulary")은 훈련 전에 데이터를 한 번 전달하여 만든 간단한 조회 테이블로서, 이를 벗어난 값은 Zero 임베딩에 매핑된다.
•
예를 들어 큰 규모의 카디널리티 ID 공간 (동영상 ID 또는 검색어)은 클릭된 노출의 빈도를 기준으로 정렬한 후 상위 N개만 포함하고, 이를 벗어난 값들은 Zero 임베딩으로 매핑 시킨다.
중요한 점은 동일한 ID 공간의 범주형 피처들도 기본적인 임베딩을 공유한다. 그러나 공유된 임베딩에도 불구하고, 각 피처는 네트워크에 개별적으로 공급된다. 따라서 상위 계층은 피처 별로 전문화 된 표현을 학습할 수 있다. 임베딩은 공유는 일반화(generalization)를 개선하고, 훈련 속도를 높이며, 메모리 요구사항을 줄이는 부분에서 중요하다.
대다수의 모델 매개변수는 이와 같이 높은 카디널리티 임베딩 공간에 위치한다.
4.1.3. Normalizing Continuous Features
신경망은 Input 크기 조정 및 분포에 악명 높은 반면, 의사 결정 트리 앙상블과 같은 대체 접근 방식은 개별 피처들의 크기 조정이 변하지 않는다. 본 연구는 연속형 피처들의 적절한 정규화가 수렴에 중요하다는 것을 발견했다.
4.2 Modeling Expected Watch Time
본 논문의 목표는 Positive(사용자가 노출된 동영상을 클릭) 또는 Negative(사용자가 노출된 동영상을 클릭하지 않음) 훈련 사례들을 고려하여 예상되는 시청 시간을 예측하는 것이다.
예상 시청 시간을 예측하기 위해, Weighted Logistic Regression 기법을 사용한다. 해당 모델은 Cross Entropy Loss 하에 Logistic Regression로 훈련된다. 이때 Positive("clicked") 노출은 관찰된 시청 시간에 따라 가중치가 부여되고, Negative("unclicekd") 노출은 모두 단위 가중치만 부여 받는다.
해당 논문의 실험/성능평가 부분은 생략한다.
본 논문은 추천 알고리즘을 위한 DNN 아키텍처로 "Cadidate Generation Network" 와 "Ranking Network"를 제안한다. 이때 Deep Collaborative Filtering 모델은 많은 signals를 효과적으로 동화하고, Depth Layer와의 상화작용을 모델링하여 YouTube에서 사용된 이전의 Matrix Factorization 접근 방식보다 우수한 결과를 야기했다.
번외로 딥러닝을 말하고 있지만 Feature Engineering이 차지하는 부분도 크다는 것을 알 수 있다.
해당 논문의 경우, NN과 함께 전반적인 YouTube 추천 시스템 관련 방대한 지식들을 간추려서 말하고 있어서 이해하기가 다소 어려웠다. (다시 읽어봐야지ㅠ)