




안녕하세요. Physics-based Humanoid Control in AI Robotics를 전공하고 있는 이민경입니다. 2020년에 잠시 추천시스템에 흥미가 생겨서 개인적으로 공부했습니다. 다양한 딥러닝, 로보틱스 관련 공부도 하면서 논문들 읽고 재구현하는 것을 좋아해요.
 Email: blossominkyung@gmail.com
Email: blossominkyung@gmail.comYouTube Recommendation System Trilogy
1 - The YouTube Video RecSys
2 - Deep Neural Networks for YouTube Recommendations
3 - What Video to Watch Next : YouTube
YouTube RecSys Trilogy 마지막 논문으로 2019년 RecSys에 게재된 "Recommending What Video to Watch Next: A Multitask Ranking System" 리뷰입니다.
Index.
YouTube 추천 시스템은 - Candidate Generation & Ranking - 두 가지 방식을 따르는데 이 논문은 YouTube RecSys. 시리즈 두번째 논문과 다르게 랭킹 모델에 초점을 두고 설명하고 있다.
랭킹 방식이란, 추천시스템이 후보군 생성에서 검색된 수백개의 후보군들을 가지고 있고 정교한 대용량 모델을 적용하여 Next Watch Video로 가장 유망한 아이템의 순위를 매기고 정렬하는 것을 말한다.
[From Paper] Recommending what to watch next on YouTube
1. Problem Description
1.1. Challenge Issues
유튜브가 해결하려고 집중하고 있는 두 가지 과제가 있다.
•
Conflicting Objectives - 영상 시청 외에도 동영상 공유나 좋아요 표시 등 최적의 objective를 잘 설정해야한다.
•
Feedback Loop Effect - 사용자가 동영상이 단순히 추천 영상에 있기 때문에 동영상을 시청할 수 있다. 이처럼 Feedback Loop 효과로 인해 훈련한 모델들이 편향될 수도 있다. 따라서 이러한 편향을 효과적으로 줄이는 방법이 필요하다.
두 가지 과제를 해결하기 위해 추천시스템은 후보 생성과 랭킹으로 문제를 정의한다. 이때 고려해야될 요소 두 가지 요소로- Multimodal Feature Space 와 Scalability -가 있다.
•
Multimodal Feature Space - 컨텍스트 인식 개인화 추천 시스템에서는 비디오 컨텐츠, 썸네일, 오디오, 제목 및 설명, 사용자 인구통계 등 여러 모달리티에서 생성된 피처 공간으로 후보 동영상의 사용자 유틸리티를 학습해야 한다. 멀티모달 피처 공간에서 추천을 위한 학습 표현은 (1)컨텐츠 필터링을 위해 저수준 컨텐츠 피처들의 시맨틱갭을 해소하고 (2)협업 필터링을 위해 아이템의 희소한 분포로부터 학습하는 두 가지 문제를 해결한다.
•
Scalability - 쿼리당 수백명의 후보에 대해 점수를 매기지만, 일부 쿼리와 컨텍스트 정보는 온라인에서만 사용할 수 있으므로 실제 시나리오에서는 점수를 실시간으로 지정해야한다. 따라서 랭킹 시스템은 수십억 개의 아이템 및 사용자에 대한 표현을 학습해야 하고 모델서빙 중에도 효율적이어야 한다.
위의 이슈들을 해결하기 위해 이 논문은 아래 그림과 같이 Multi-task Neural Network Architecture를 제안한다. 제안한 아키텍처는 Multi-gate Mixture-of-Experts 구조를 적용하여 Wide & Deep model을 확장한 모델로, Shallow Tower를 도입하고 선택편향(Selection Bias)을 제거하였다.
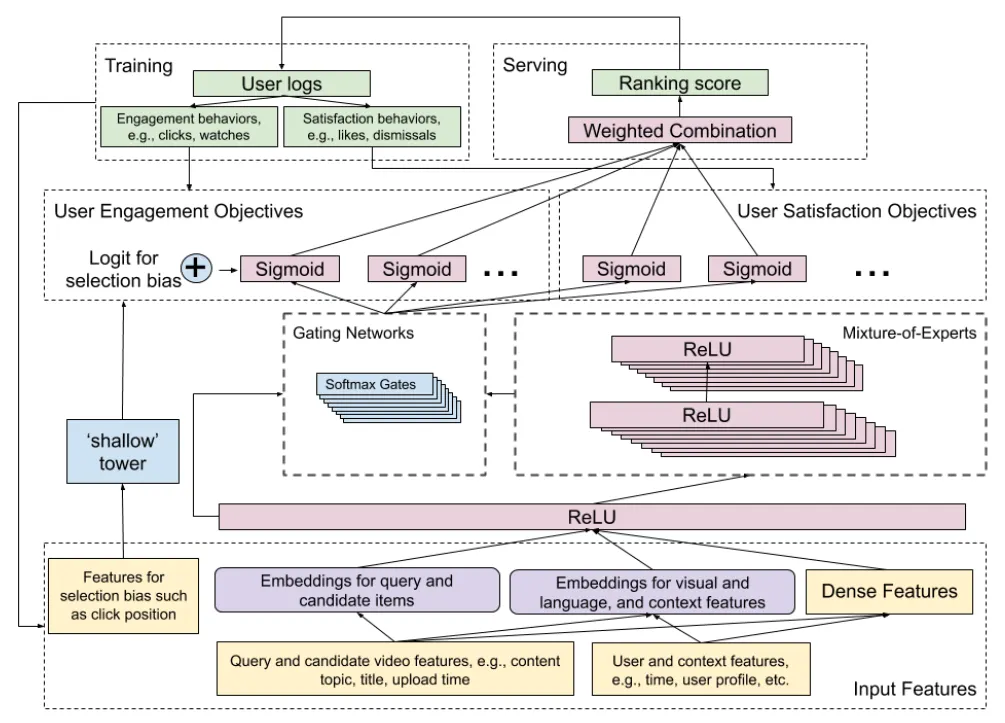
Model Architecture of the Proposed Ranking System.
1.2. Roughly Overview
간략하게 모델에 대하여 설명하자면, 우선 여러 목표들을 참여 및 만족도 표현으로 그룹화한다. 그후, 여러 유형의 사용자 행동을 학습하고 추청하기 위해, MMoE를 사용하여 잠재적으로 혼란스러운 목표들을 공유하기 위해 필요한 매개변수를 자동으로 학습한다.
또한 편향된 훈련 데이터에서 위치 편향과 같은 선택 편향을 모델링 하고 줄이기 위해, 메인 모델에 Shallow Tower을 추가했다. (Shallow Tower는 현재 시스템에 의해 결정된 랭킹 순서처럼 선택편향과 관련된 입력을 받고, 메인모델의 최종 예측에 대한 편향 항 역할을 하는 스칼라를 출력한다.) 이 모델은 훈련 데이터의 레이블을 두 가지 파트인 메인모델에서 학습한 편향되지 않은 사용자 유틸리티와 Shallow Tower에서 학습한 예상 성향 점수로 분해한다. 이때 Shallow Tower는 Wide & Deep 모델에서 Wide 파트에 해당된다.
이와 같이 논문이 제안 하는 모델은 Wide & Deep model의 확장버전으로 이와 함께 Shallow Tower을 직접 학습함으로 성향 점수를 얻기 위해 무작위 실험에 의존하지 않고 선택 편향을 학습할 수 있다. 이를 통해 현재 시청 중인 비디오와 컨텍스트를 고려하는 동영상 랭킹 목록을 제공할 수 있다.
앞서 말했듯 본 논문은 랭킹 모델에 중점을 두고 설명하고 있다. 따라서 랭킹 모델에 대해 조금 더 자세하게 다음과 같이 설명하고 있다.
2. Ranking Model Architecture
랭킹 시스템은 클릭, 시청 시간과 같은 사용자 참여도(engagement)와 좋아요, 관심없음으로 나타낼 수 있는 사용자 만족도(satisfaction) 피드백에 의해 학습된다. 학습을 위한 후보가 주어진 경우, 후보, 쿼리, 컨텍스트의 피처들이 랭킹 시스템의 입력값으로 사용되고, 랭킹 시스템은 여러 사용자들의 행동을 예측하기 위해 학습을 한다(learning-to-rank)
랭킹 문제를 여러 objectives의 classification과 regression 조합으로 모델링한다. 쿼리, 후보, 컨텍스트가 주어졌다면, 랭킹 모델은 '클릭, 시청, 좋아요, 노관심' 처럼 사용자가 취할 수 있는 행동들의 확률을 예측한다. 이때 각 후보를 예측을 하는 방법으로 Pointwise 접근법을 택했다.
랭킹 시스템은 훈련 레이블로 사용자 행동을 사용한다. 사용자가 추천된 아이템들에 대해 각기 다른 유형의 행동 양상을 보일 수 있어서, multiple objective를 지원하도록 랭킹 시스템을 설계한다. 이때 각각의 objective는 사용자 유틸리티와 관련된 사용자 행동 양상의 유형을 예측한다. 이때 사용자 행동양상 유형은 다음과 같다.
(1) 사용자 참여도 - 사용자 클릭(binary classification), 시청 시간 (regression)
(2) 사용자 만족도 - 좋아요(binary classification), 순위(rating) 평가(regression)
최종적으로 모델은 multitask ranking model을 학습하여 multiple ranking objective를 combined score로 갖게 된다.
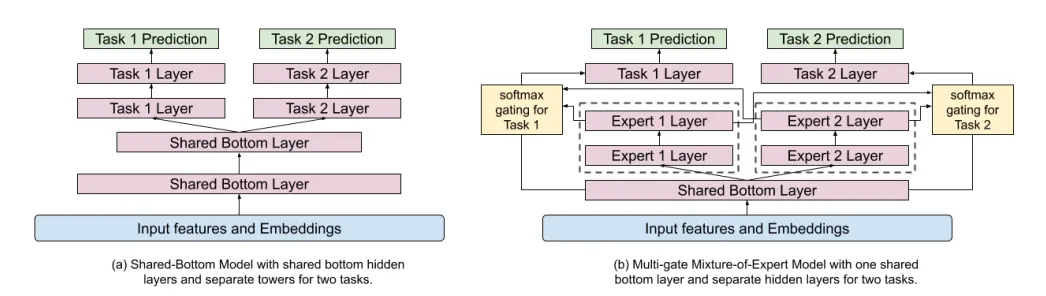
[From Paper]Replacing shared-bottom layers with MMoE
MoE layer는 입력에서 모듈화된 정보를 학습하는데 도움을 줄 수 있다. 따라서 유튜브 랭킹 시스템의 경우 MMoE 모델(그림 b)을 도입했다. MMoE 모델을 도입하면, 입력 레이어 또는 하위 은닉 레이어에서 직접 사용할 때 Multimodal feature space을 더 잘 모델링 할 수 있다는 장점이 있다.
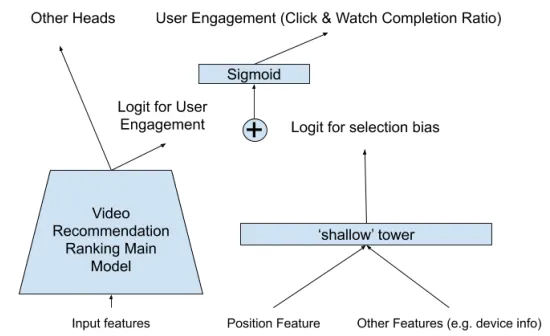
[From Paper]Adding a shallow side tower to learn selection bias
논문의 또다른 포인트로는 Selection Bias가 있다.
랭킹 시스템에서 사용자는 실제 사용자 유티리티와 관계없이 리스트 상단에 더 가깝게 표시된 영상을 시청하는 경우가 있다. 유튜브는 랭킹 모델에서 이와 같은 포지션 편향을 제거하고자 Wide&Deep 모델과 유사한 모델을 설계했다. 위 그림처럼 포지션 편향에 대해 포지션 피처와 같이 Selection Bias에 기여하는 피처를 사용해서 shallow tower를 훈련한 뒤 최종모델에 추가하는 방식을 선택한다.
3. Experiment Results
3.1. Experiment Setup
다중 후보 생성 알고리즘에서 수백개의 후보를 가져와서 실험을 진행한다. TensorFlow를 사용해서 모델학습 및 모델 제공을 구축한다: TPU(모델학습) 및 TFX Servo(모델제공)
추천시스템의 가장 큰 난관이 데이터 분포 및 사용자 패턴이 시간마다 다이나믹하게 변한다는 것인데 이를 위해 이 논문은 가장 최근의 데이터들을 가져다 사용한다. 오프라인 실험에서는 AUC를 모니터하고 온라인 환경에서는 A/B 테스트로 진행한다. (조금더 자세한 사항은 논문을 참조하기 바란다.)
3.2. Modeling and Reducing Position Bias
훈련 데이터로서 사용자 암시적 피드백을 사용하는 가장 큰 난관은 실제 사용자 유틸리티와 암시적 피드백 간의 갭을 모델링하는 것이 어렵다는 점이다. 선택적 편향(포지션 편향)을 어떻게 줄이고 모델링할 것인지에 대해 제안한 경량화 모델 아키텍처의 성능을 통해 보여준다. 이때 논문에서 제안하는 솔루션은 랜덤 평가 또는 복잡한 연산의 비용 등 과하게 불필요한 비용 지불을 없애준다.
이 부분에 대해 CTR 분석으로 다음과 같이 보여준다.
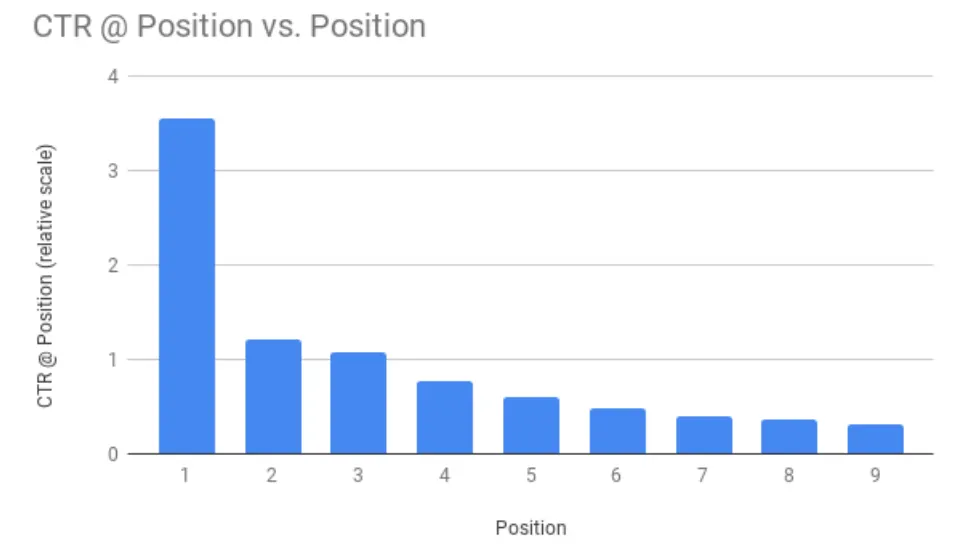
[From Paper] CTR for position 1 to 9
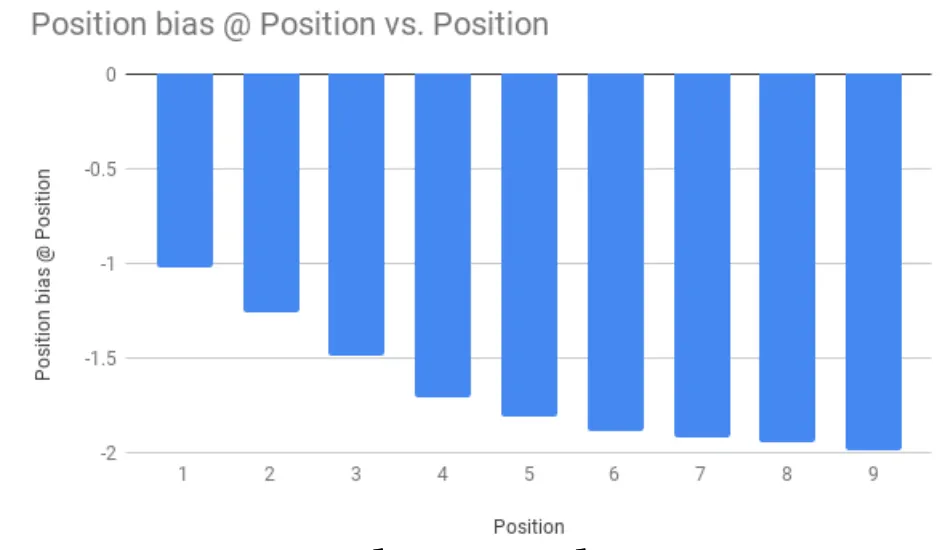
[From Paper] Learned position bias per position
3.3. Discussion
논문에서는 랭킹 시스템을 구축하고 실험하면서 얻은 몇 가지 인사이트와 한계점을 알려준다.
1) Neural Network Model Architecture for Recommendation and Ranking
•
Multimodal feature spaces: 논문이 제안하는 랭킹 시스템은 쿼리와 아이템의 콘텐츠 피처, 컨텍스트 피처 등 여러 리소스의 피처들에 의존한다. 이러한 피처들은 희소 범주 공간에서 자연어 및 이미지에 이르기까지 다양하다. 이처럼 피처 공간들이 혼합된 곳에서의 학습은 어렵다.
•
Scalability and multiple ranking objectives: 여러 모델 아키텍처는 피처 교차 또는 순차적 정보처럼 한 가지 유형의 정보를 캡처하도록 설계되었다. 이러한 아키텍처들은 보통 랭킹 objective를 개선하지만 동시에 다른 objectives를 해칠 수 있다. 또한 시스템에 복잡한 모델 아키텍처 조합을 사용하면 모델 확장이 어렵다.
•
Noisy and locally sparse training data: 논문이 제안하는 랭킹 시스템은 쿼리와 아이템 모두 임베딩 벡터를 훈련해야한다. 하지만 대부분의 희소 피처는 멱 법칙 분포(power-law distribution)를 따르고 사용자 피드백에 큰 variance가 있다. 이로 인해 꼬리 아이템의 임베딩 공간 최적화가 어렵다.
•
Distributed training with mini-batch stochastic gradient descent: 제안하는 모델의 경우 피처 간의 연관성을 파악하기 위해 강력한 표현력을 가진 대규모 신경망 모델에 의존하는 경향이 있다. 많은 양의 훈련 데이터를 사용하기에 본질적인 난제가 있는 분산 훈련을 사용해야한다는 한계가 있다.
2) Tradeoff between Effectiveness and Efficiency: 실제 랭킹 시스템의 경우 효율성은 서비스 비용과 사용자 경험에도 영향을 준다. 추천된 아이템을 생성할 때 지연시간을 크게 늘리도록 구현된 복잡한 모델은 사용자 만족도와 실시간 메트릭을 감소시킬 수 있다. 따라서 일반적으로 더 간단하고 직관적인 모델 아키텍처를 선호한다.
3) Biases in Training Data: 포지션 편향 외에도 여러 유형의 편향들이 있는데 대부분 알려지지 않았거나 예측할 수 없는 것들이다. 따라서 훈련 데이터 내 다양한 편향들을 포착하고 자동으로 훈련하는 방법 역시 아직 해결 할 수 없는 난제이다.
4) Evaluation Challenge: 논문이 제안하는 랭킹 시스템에서는 대부분 사용자 암시적 피드백을 사용했다. 따라서 실시간 평가로 이를 학습하는 것은 어려웠다. 전반적으로 간단한 모델을 사용하는 것이 온라인 성능을 일반화하기는 더 좋은 방법이다.
5) Future Directions: MMoE와 선택 편향 제거 외에도 이 논문은 다음 세 가지를 개선하려고 한다.
•
Exploring new model architecture for multi-objective ranking - balancing stability, trainability, and expressiveness.
•
Understanding and Learning to factorize - to model various biases including unknown
•
Model compression - to reduce serving cost
본 논문은 사용자 피드백의 암시적 선택 편향과 다중 경쟁 랭킹을 다룬다. large-scale multi-objective 랭킹 시스템을 제안하고 이를 다음에 어떤 영상을 볼지 추천하도록 유튜브에 적용했다. 이 논문의 가장 큰 부분은 기존의 널리 알려진 Wide & Deep Learning 모델과 MMoE를 사용해서 경량화된 효율적인 방안을 제안했다는 부분이다.
이 논문을 마지막으로 기존에 알려진 유튜브 추천 논문 리뷰를 마치려고 한다.
유튜브 추천 논문은 (1)일반적인 추천 (2)후보 생성에 초점을 둔 추천 (3)랭킹 모델에 초점을 둔 추천 논문으로 나눌 수 있었다. 추천 시스템은 비즈니스 차원에서 많이 응용되고 있고 발전되었다고 말할 수 있지만 사람의 심리를 반영해야 한다는 부분에서 여전히 해결해야 될 난제들이 많다. 다음 추천 논문 리뷰로는 해도해도 아무리 해봐도 제대로 알기 어렵고 비즈니스 측면으로도 여전히 어려운 CTR Prediction 시리즈 대장정을 가보려고 한다.