
•
2017년도 WWW에서 발표한 Pinterest(핀터레스트)의 추천시스템 논문, ‘Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time’, 리뷰 글입니다.

Summary
수십억개의 유저와 아이템을 가지고 실시간 초개인화 추천을 제공하기 위해 핀터레스트는 본 논문에서 그래프 랜덤워크를 개선한 Pixie Random Walk 알고리즘을 제안했습니다.
Pixie는 2017-2018년도 당시 실제로 핀터레스트 추천 시스템에 적용된 모델이다. 이 논문은 Pixie Random Walk 라는 핀터레스트만의 그래프 기반 추천 모델을 제안하여 핀터레스트가 직면한 과제들을 해결하는데 초점을 두고 있다.
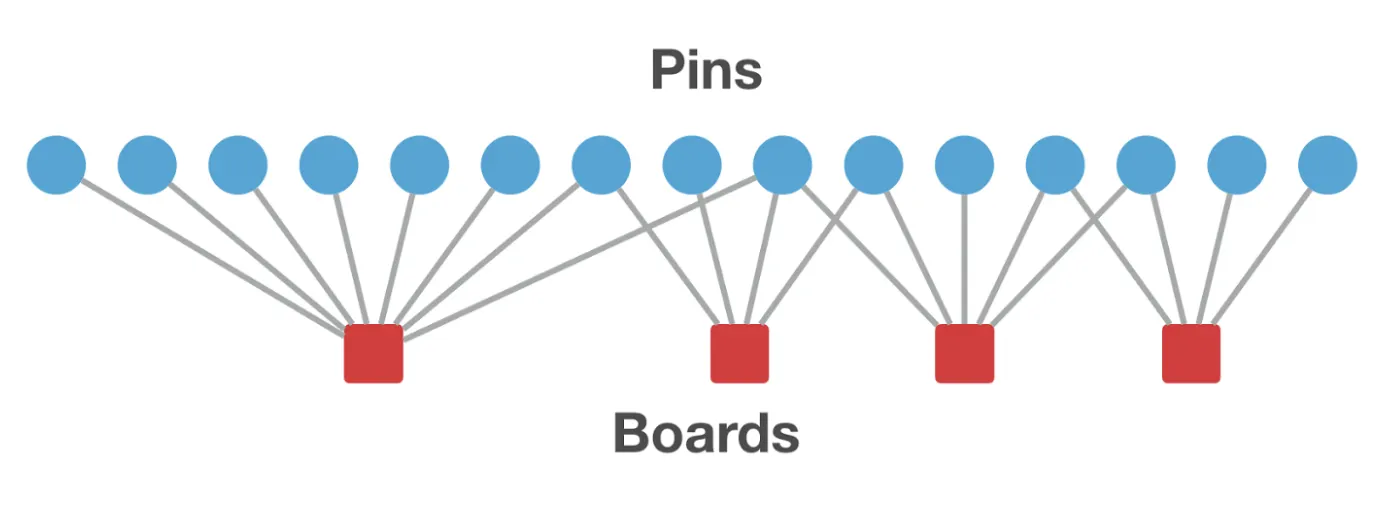
설명에 앞서 핀터레스트에 대해 소개하자면, 핀터레스트는 Pin(핀)과 아이템(이미지, 동영상)을 통해 유저와 상호작용하고 이때 유저는 Board(보드)를 만들어서 자신이 핀한 아이템들을 저장할 수 있다. 즉 핀터레스트는 유저가 관심있는 아이템들을 핀하고 이를 보드에 저장하면서 동시에 다른 유저들과도 공유할 수 있는 이미지 중심의 소셜 네트워크 서비스이다.
1. Problem Description
핀터레스트는 2억명이 넘는 유저와 30억개 이상의 아이템들을 기반으로 유저에게 실시간으로 가장 최적화된 추천을 제공해야 되는 주요한 과제를 가지고 있다. 이와같으려면 모든 유저에 대한 추천이 일일 스케쥴에 따라 미리 계산되고 구체화되어야 된다. 또한 가입한 총 유저 수는 일반적으로 일일 활성 유저 수보다 훨씬 많기 때문에 비활성 유저에 대한 추천을 업데이트 하는데 많은 시간과 리소스를 낭비하면 안된다.
간단하게 정리하면 핀터레스트가 해결하기 위해 집중하는 2가지 과제는 다음과 같다.
1.
수십억 개의 Pin들 중에서 유저에게 가장 최적화된 추천을 제공해야 한다.
2.
수십억 개의 아이템과 수억 명의 유저들로 구성된 핀터레스트의 추천이 실시간이어야 한다.
(img) Pinterest Blog
앞서 말한 바와 같이 핀터레스트는 유저가 핀과 상호작용하면서 보드에 핀들을 큐레이션 할 수 있다. 즉 핀터레스트는 핀과 보드, 그리고 아이템과의 관계를 보여주는 Edge(엣지)인 Bipartite Graph 구조로 구성되어있다. 핀터레스트는 위 두가지 챌린지를 해결하기 위해 이러한 bipartite graph구조에 random walk를 적용한 Scalable Real-Time Graph-based 추천시스템인 Pixie Random Walk를 제안한다.
2. Pixie Random Walk
2.1. Basic Random Walk
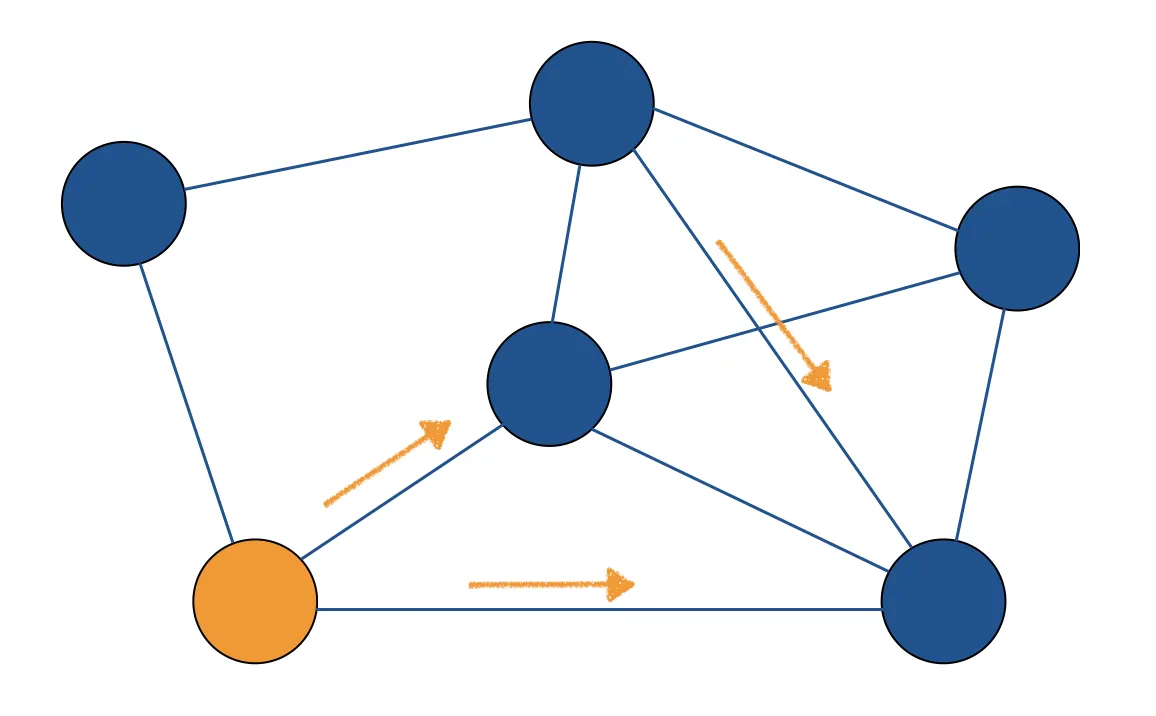
Pixie Random Walk 알고리즘을 이해하기에 앞서서 그래프의 random walk가 무엇인지 알면 용이하다.
(img) Random Walks on Graph
그래프의 랜덤워크란 주어진 그래프 상의 아무 노드에서 시작해서 랜덤하게 인접한 노드를 선택하면서 이동하는 것을 의미한다. 처음 정한 N번의 과정이 끝나면 노드에 방문한 횟수만큼을 각 노드의 가중치로 계산해 리턴해주는데 이때 같은 노드에서 시작해서 랜덤워크를 여러번 반복한 뒤 그 평균값을 리턴하기도 한다.
def basic_random_walk(query_pin q, edges E, visiting_count N):
total_steps = 0
visit_counter = {}
while True:
current_pin = q
step_size = sample_walk_length()
for i in (step_size):
current_pin = E[current_board].random_neighbor()
current_board = E[current_pin].random_neighbor()
visit_counter[current_pin] += 1
total_steps += step_size
if total_steps > N:
break
return visit_counter
Python
복사
(algorithm)basic random walk python pseudo code version
이와같은 일반적인 랜덤워크은 아쉽게도 개인화된 추천을 제공하지 못한다. 특히 연결된 엣지가 적은 저차노드의 경우 토픽에 더 집중하며 관련성이 높은 추천을 생성할 가능성이 높지만, 일반적인 랜덤워크는 이를 중요하게 여기지 않는다. 따라서 본 논문에서는 최적화된 추천을 위해 앞서 살펴본 랜덤워크을 개선한 Pixie Random Walk를 제안한다. Pixie Random Walk가 랜덤워크의 어떤 부분들을 어떻게 개선했고 어떤 결과를 얻었는지 살펴보도록 하자.
2.2. Pixie Random Walk
•
Biasing the Pixie Random Walk
핀터레스트 그래프에는 언어와 토픽이 다른 핀과 보드가 존재하는데 이때 유저는 본인이 관심 있는 토픽에 대해 본인이 설정한 언어로 추천을 받아야 한다. 즉 ‘해리포터’와 관련된 수많은 핀과 보드들이 핀터레스트 그래프 내에 존재하고 핀터레스트에서 내가 설정한 언어가 영어라고 가정해보자. 이때 일본어로 된 ‘해리포터’를 추천받게 되면 이는 개인화에 실패한 추천이고, 몇 번 반복되다보면 나는 핀터레스트를 이탈할 수 밖에 없다.
이러한 문제를 해결하기 위해, Pixie Random Walk는 토픽이나 언어와 같은 유저 피처를 고려해서 유저와 더 관련있는 엣지에 높은 가중치를 부과하는데, 가중치가 높다는건 더 중요하다는 뜻이므로 추천의 개인화, 퀄리티, 관심사 등이 개선되는데 중요한 역할을 한다. 이처럼 유저와의 연관성이 더 높은 엣지에 가중치를 부과하는 편향을 랜덤워크에 부여한다면 같은 쿼리에서도 유저마다 개인화된 추천을 받을 수 있게 된다.
즉 Pixie는 관련도가 높은 엣지에 가중치를 부여함으로 유저에게 개인화된 추천을 제공하고 이는 높은 유저 참여율을 야기한다.
•
Multiple Query Pins with Weights
전체적으로 유저를 모델화하려면 주어진 유저의 전체 히스토리 맥락을 기반으로 추천을 구축하는 것이 중요한데 이때 여러 핀들을 기반으로 쿼리를 형성하는 것이 좋다. 쿼리 내의 각각의 핀은 서로 다른 가중치를 가지고 있다. 여기서 가중치는 유저가 핀과 상호작용한 이후의 시간과 그 유형으로 할당된다.
의미있는 방문수를 얻기위해 요구되는 스텝수는 쿼리 핀의 차수에 따라 다르다. 즉 여러 보드에서 일어나는 높은 차수의 쿼리 핀에서 추천하는 것은 낮은 차수보다 더 많은 스텝을 요구한다. 따라서 각 쿼리 핀에 할당된 스텝수를 차수에 비례하도록 조정해야 한다. 그러나 이때 선형으로 스텝수를 할당하게 되면 차수가 낮은 핀으로 한 스텝도 가지 않는 문제가 발생할 수 있다. 쿼리 핀 추세에 따라 선형적으로 증가하는 함수를 기반으로 스텝수를 할당하고 핀 당 가중치를 배율 인수로 조정하여 스텝 분포를 만들어야 한다.
•
Multi-hit Booster
Pixie 알고리즘는 일련의 핀이 있는 쿼리의 경우 여러 쿼리 핀과 관련된 추천을 선호한다. 총 방문횟수가 모두 동일하다고 가정했을 때, 여러 쿼리 핀에서 방문 횟수가 높은 후보는 모두 단일 쿼리 핀에서 오는 후보 보다 쿼리와 더 관련이 있다.
이처럼 하나의 쿼리 핀 보다 여러 쿼리 핀에서 후보 핀을 방문할 수록 ‘multi-hit’ 핀 비율이 높아지게 된다. 다시말해 쿼리에서 수많은 핀이 방문한 핀일 수록 중요도가 커진다.
•
Early Stopping
Pixie 런타임은 방문수에 의존되기 때문에 방문수를 가능한 최소한으로 하는 랜덤워크를 실행해야 한다. 이를 위해 본 논문은 높은 우선순위에 있는 후보자 세트가 얻어지면 랜덤워크를 종료하는 방법으로 런타임 문제를 해결했다.
def pixie_random_walk(query_pin q, edges E, visiting_count N, nv, np):
total_steps = 0
high_visited = 0
visit_counter = {}
while True:
current_pin = q
step_size = sample_walk_length()
for i in (step_size):
current_pin = E[current_board].personalized_neighbor(U)
current_board = E[current_pin].personalized_neighbor(U)
visit_counter[current_pin] += 1
if visit_counter[current_pin] == nv:
high_visited += 1
total_steps += step_size
if total_steps > N or high_visited > np:
break
return visit_counter
Python
복사
(algorithm)pixie random walk python pseudo code version
def multiple_pixie_random_walk(query_pin q, query_pin_weight w,
scaling factor for a query pin q Sq,
edges E, user_personalize_feature U):
for q in Q:
nq = (wq * N * Sq) / sum(sr) # Eq(2) in paper
vq = pixie_random_walk()
for p in G:
visit_counter[p] += sqrt(vq) # Eq(3) in paper
return visit_counter
Python
복사
(algorithm)multiple pins on pixie recommendation python pseudo code version
(*nv: 추천 세트의 핀이 충족해야 하는 방문 횟수의 최소 임계값, np: random walk를 중지하기 전에 이 임계값에 도달하는 최소 핀의 수)
2.2. Graph Pruning
핀터레스트 그래프는 70억개의 노드와 1000억개의 엣지를 가지고 있기 때문에 모든 보드에 핀들이 정확하게 알맞게 들어간다고 확신할 수 없다. 크고 다양한 보드들이 너무 많은 방향으로 Pixie Random Walk 내에 퍼져있는데 이는 추천 성능을 떨어트리는 요인이 된다. 많은 핀들 역시 잘못된 보드로 카테고리 되있다.
Graph Pruning은 토픽에 초점을 잘 맞출 수 있도록 그래프 크기를 줄여주어 추천 퀄리티를 개선하는데 도움을 준다. 본논문은 랜덤으로 엣지를 무시하는 것보다 LDA 토픽 모델링과 유사도 계산 등을 통해 핀이 잘못 카테고리 되어있거나, 토픽이 맞지 않는 보드에 속해잇는 엣지들을 제거하는 방법을 사용한다.
3. Experiments
3.1. Pixie Recommendation Quality
•
Ranking the most related pin
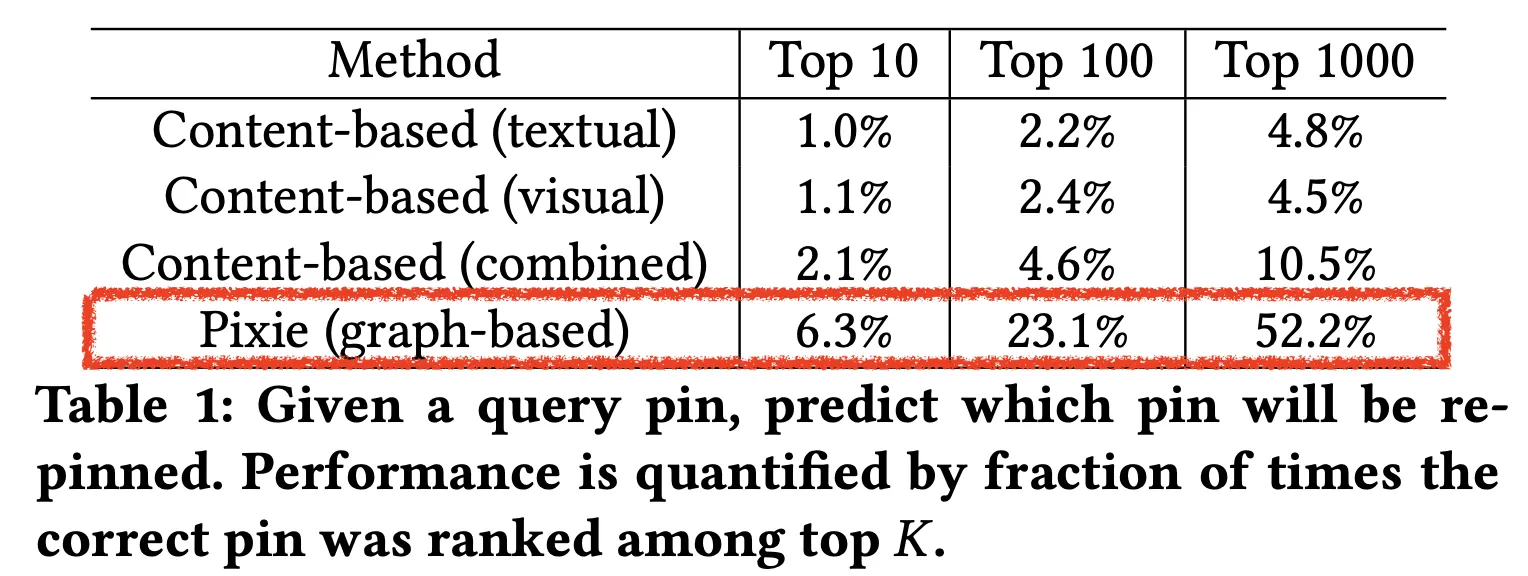
쿼리 핀과 가장 관련있는 핀을 예측한 성능을 알기위해 hit rate으로 성능을 측정했는데 K=10, 100, 1000 전부 Pixie가 가장 높은 성능을 보였다.
•
Result of A/B experiments

유저가 클릭, 좋아요, 및 저장을 통해 참여하는 핀의 비율을 정량화 하여 유저 참여도를 측정하는데, 통제된 A/B 테스트에서 Pixie가 추천하는 핀의 참여율이 13%~48% 정도 증가했다는 걸 알 수 있다.
3.2. Pixie Performance and Stability
•
Pixie Runtim
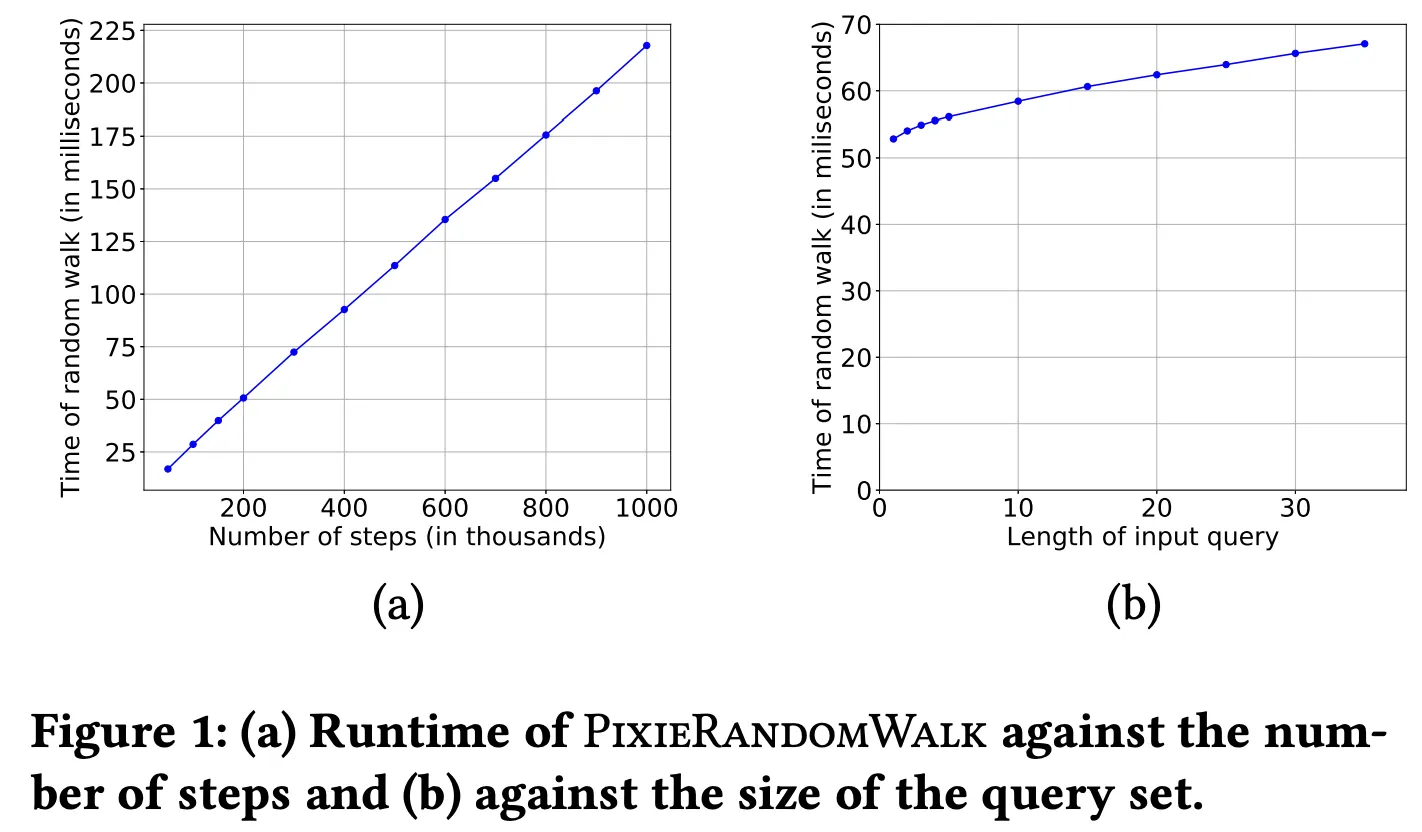
스텝수와 쿼리 크기가 Pixie 런타임에 어떤 영향을 미치는지 평가한 결과이다. (a)를 보면, 런타임은 스텝수에 따라 선형적으로 증가한다. (b)를 보면, 쿼리 크기에 따라 런타임이 느리게 증가하는 걸 알 수 있는데 주로 캐시 미스 때문이다. 이를 통해 쿼리가 길면 캐시가 더 자주 콜드되고 런타임이 증가한다는 사실을 알 수 있다.
•
Variance of Top Results
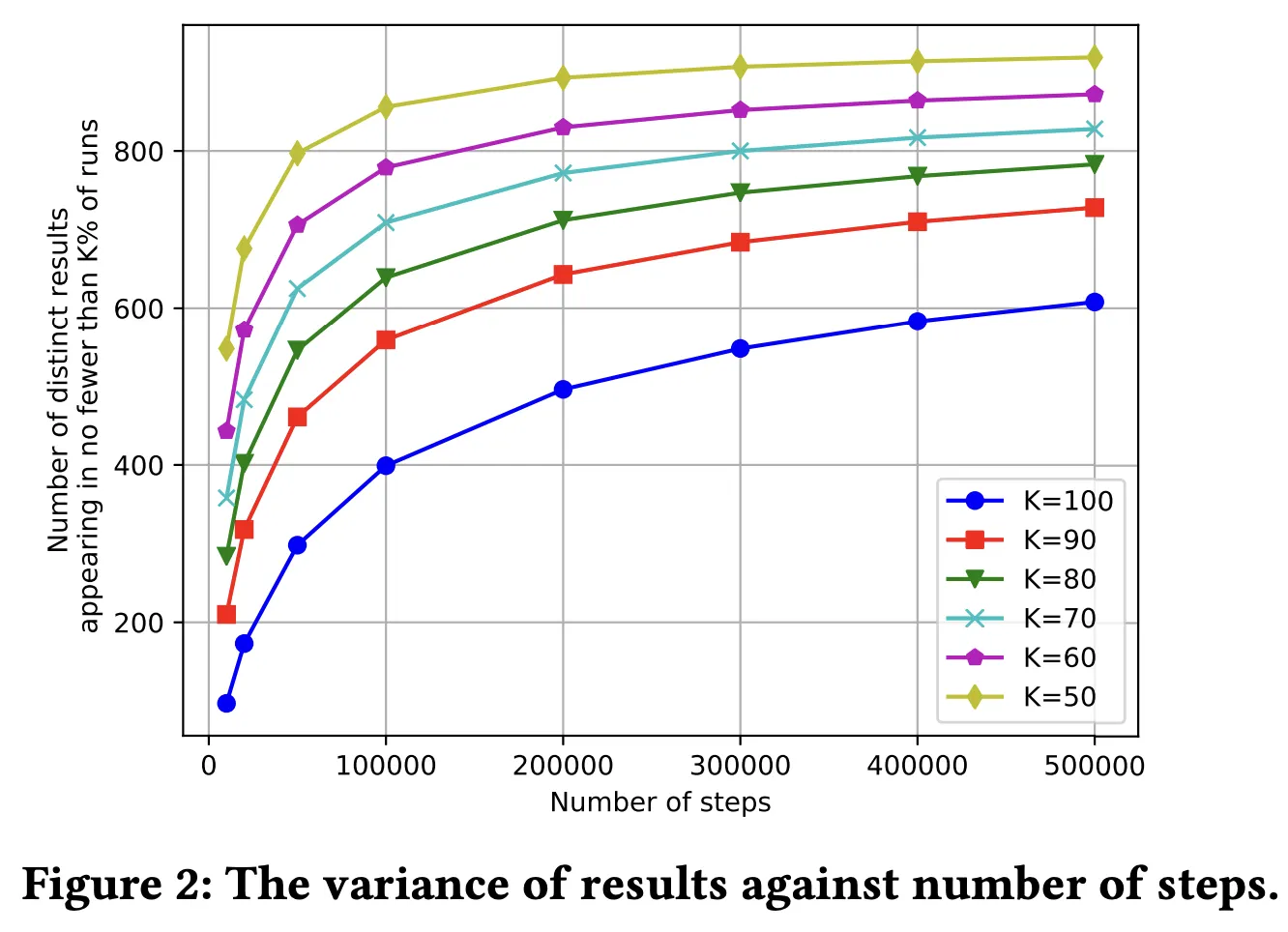
낮은 실행시간과 높은 안정성의 균형을 맞추기 위해 가장 많이 방문한 핀 세트의 안정성이 스텝수에 따라 어떻게 달라지는 평가한 결과이다. fig2는 스텝수에 따라 안정성이 향상됨을 보여준다. 예를 들어 K=50일 때를 보면, 100,000걸음에서 응답의 50% 이상에 800개 이상의 결과가 나타난다. 즉 안정적인 추천셋을 얻기 위해서는 수십만 단계면 충분하고, 그 이상은 불필요하다는 걸 알 수 있다.
•
Evaluation of the Biased Walk
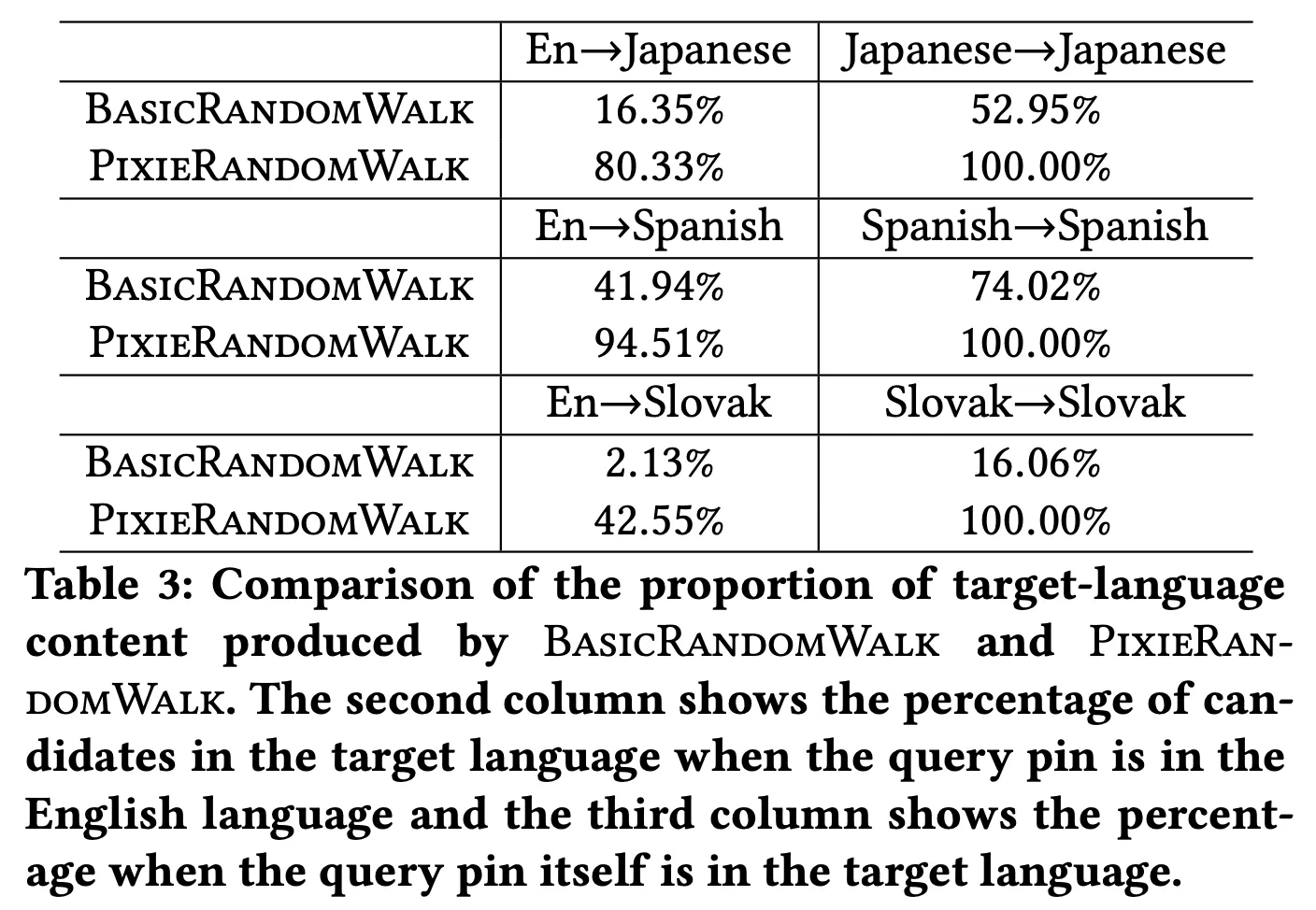
일본어, 스페인어, 슬로바키아어를 대상으로 각 언어에 대해 일반 랜덤워크 및 Pixie 에 의해 생성된 응답에서 대상 언어 핀의 백분율을 표시한 결과이다. Pixie Random Walk가 쿼리 응답에서 대상 언어 콘텐츠를 크게 향상시키는 걸 알 수 있다. 즉 유저가 사용하는 언어, 설정한 언어대로 아이템이 추천되는 확률이 높아졌다.
•
Early Stopping

3.3. Evaluating Graph Pruning
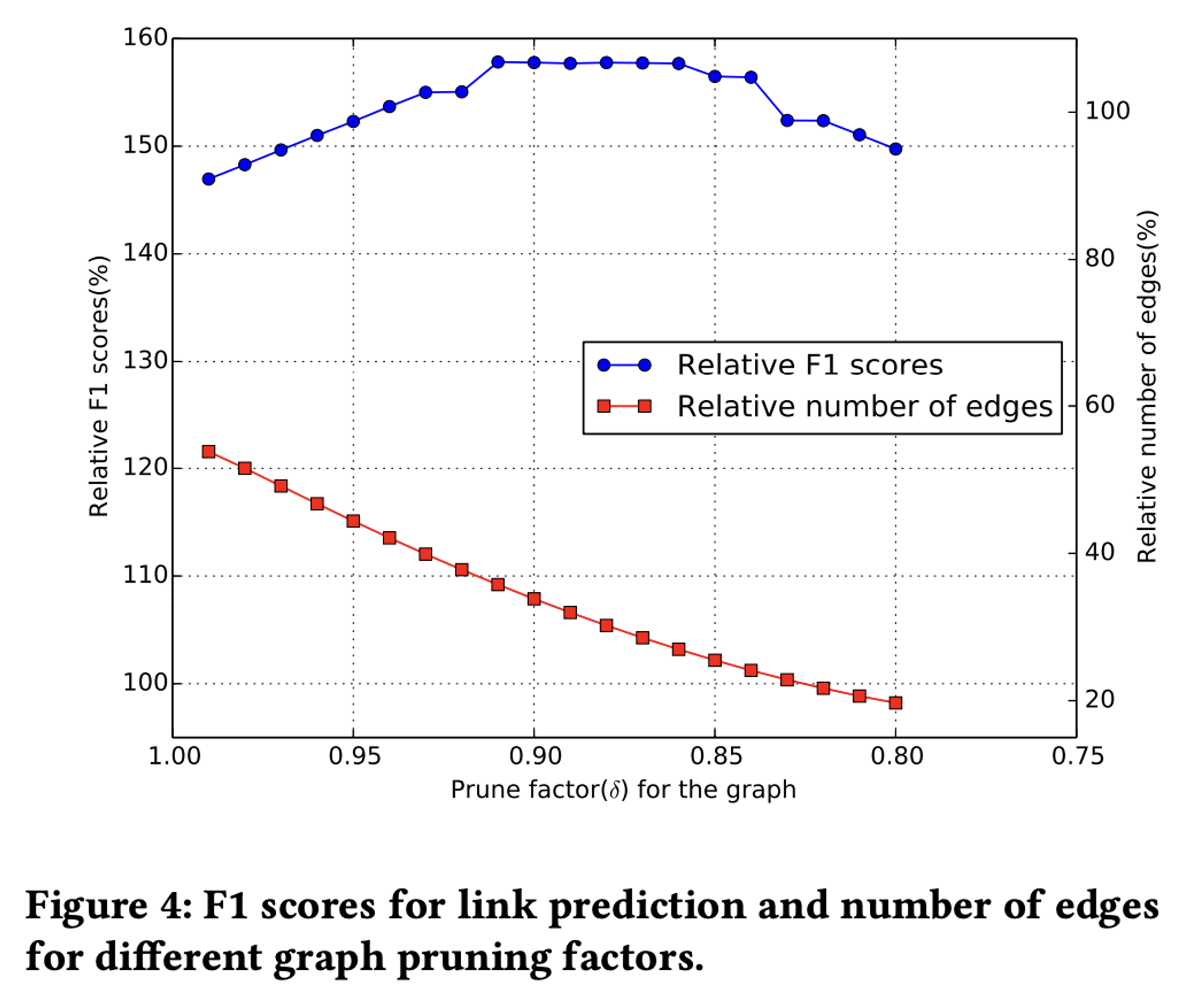
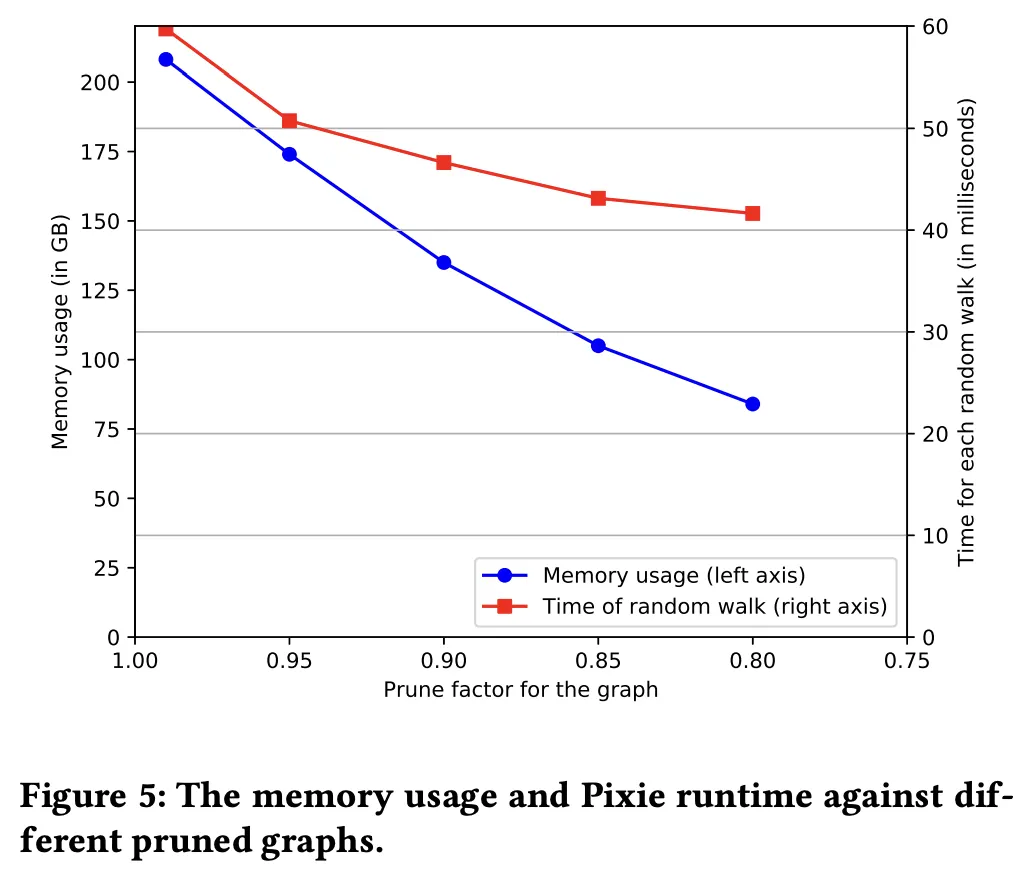
Pixie 논문을 공부하면서 머신러닝을 사용하지 않고 단순한 그래프 랜덤워크만으로도 추천의 성능을 개선했다는 점이 신선하게 다가왔다. 그리고 현재까지 핀터레스트가 발표한 추천 논문들을 미루어봤을 때, 핀터레스트가 그래프 알고리즘을 잘 활용할 수 있도록 하는데 Pixie가 그 첫걸음이 되어준 것 같다.
Pixie는 그래프 랜덤워크에서 일부를 개선한 알고리즘인데 많은 쿼리와 관련된 추천을 리워드하는 여러 독립적인 랜덤워크의 결과를 결합한 것으로 유저의 과거 동작에 대한 전체 맥락을 캡처할 수 있다는 큰 장점이 있다. 무엇보다 그래프 구조를 토대로 콜드 스타트 문제를 해결하는데 도움이 되는 핀과 보드 둘다를 추천할 수 있다는 강점 역시 존재한다. 그래프 구조에서 랜덤워크 방식을 채택함으로서 자유도가 더 증가했다는 점으로 미루어 짐작했을 때 단순한 아이디어지만 핀터레스트 구조에 가장 최적화된 방법을 채택했다고 생각한다.
다음 논문은 Pixie에서 한걸음 더 나아가 Graph Convolutional Networks를 응용한 PinSage 논문에 대해 리뷰하고자 한다.
레퍼런스