




안녕하세요. Physics-based Humanoid Control in AI Robotics를 전공하고 있는 이민경입니다. 2020년에 잠시 추천시스템에 흥미가 생겨서 개인적으로 공부했습니다. 다양한 딥러닝, 로보틱스 관련 공부도 하면서 논문들 읽고 재구현하는 것을 좋아해요.
 Email: blossominkyung@gmail.com
Email: blossominkyung@gmail.com"Netflix and Chill?"
이 말은 "우리 집에서 라면 먹고 갈래?" 미국오빠 버전이다. 여기서 신기한 점은 우리는 "라면 먹고 갈래?" 라고 말하지 농심인지 오뚜기인지 말하지 않는다. 그런데 영어권은 Netflix라는 회사이름을 말한다. 비디오랑 DVD를 대여 및 판매하던 이 회사가 콘텐츠 유통 거대 기업이 되서 슬랭에도 쓰일 지 누가 알았을까?
이처럼 콘텐츠계의 강자가 된 넷플릭스하면 절대 빼놓을 수 없는 것이 있다. 바로 넷플릭스의 추천 시스템이다!
이번 글을 시작으로 넷플릭스의 추천 시스템에 대해 알아보려고 한다.
아 참고로 누군가 본인에게 저 말을 했을때 아무것도 모르고 신나서 무작정 뛰어가면 안된다.
뭐 가끔은 진짜 넷플릭스만 보다 올 수도 있겠지만...ㅎㅎ
이번 글을 시작으로 넷플릭스 추천 시스템 시리즈를 다음과 같은 순서로 작성할 예정이다.
Netflix! How Do You Know Me?
1. Page Generation
2. Artwork Selection
3. Evidence Selection
4. Personalize Messaging
5. Personalization Research
이 글은 시리즈 첫번째인 Page Generation에 대해 작성했다.
"Netflix and Chill?" 이란 말을 듣고 친구집에 놀러가서 감자칩을 껴안고 넷플릭스에 접속했다. 그랬더니 아래와 같은 화면이 떴다. 넷플릭스는 추천의 꽃이라던데 도대체 저 화면 속에 어떤 추천 시스템이 우리를 콘텐츠로 인도하고 있는 걸까? 궁금해졌다. 그래서 넷플릭스 추천 시스템을 공부하게 되었다.
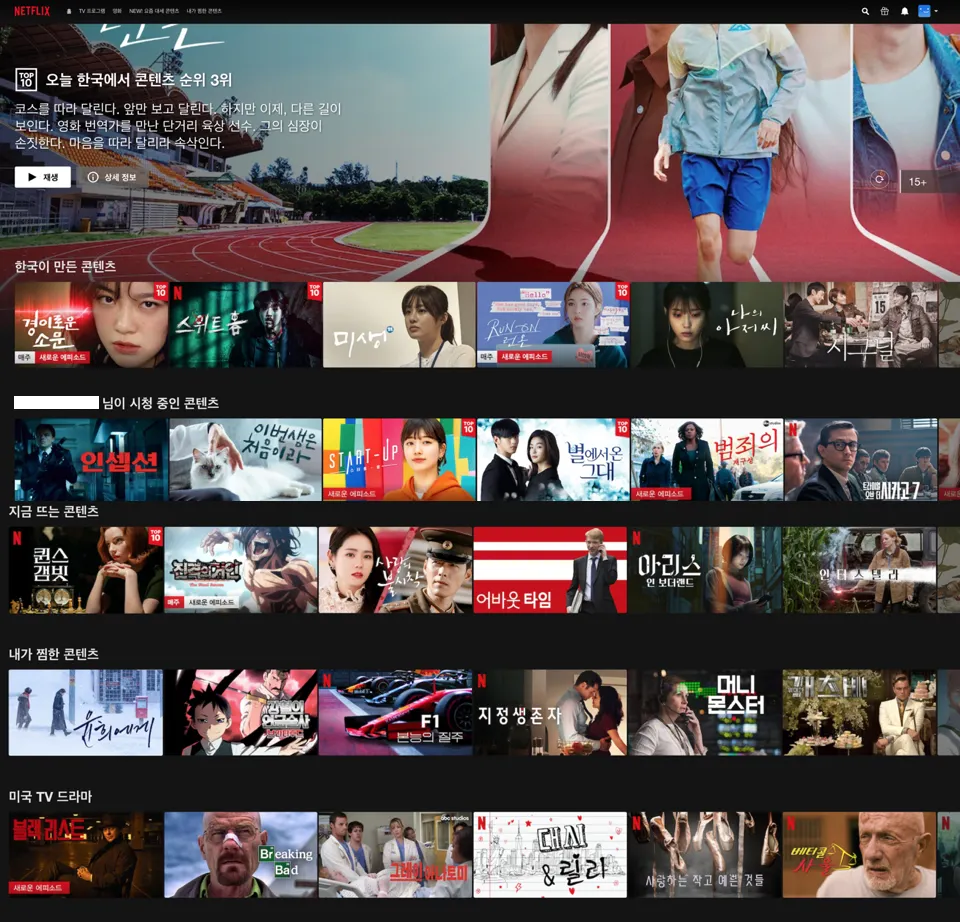
아직은 잘 모르겠지만 아마도 이 화면 안에 다양한 추천 시스템이 녹여져있을 것 같다. 다양한 요소들 중 확연히 잘 보이는 이 홈화면도 과연 추천 시스템으로 이루어져있는지. 그렇다면 어떤 추천 방식이 적용되서 내 취향을 저격하고 있는지 이번 글에서 살펴보고자 한다.
1. 유저 취향저격 홈화면 만들기
홈화면은 가장 최상단에 위치한 일종의 광고 같은 미리보기를 제외하면, 행(row)과 열(column)으로 구성되어있다. 콘텐츠들로만 나열된 열과는 다르게 행은 '한국이 만든 콘텐츠', '시청 중인 콘텐츠' 등 다양한 주제들로 이루어져있다. 행을 살펴보니 콘텐츠들이 주제에 알맞게 들어가 있는 것 같다.
넷플릭스는 유저가 좋아할 만한 동영상들을 묶어서 행(row)단위로 홈화면에 보여주는 방식을 택했다. 유저들은 좌우로 행을 움직여 해당 행에서 추천하는 콘텐츠들을 볼 수 있고, 상하로 스크롤하여 다른 행들을 확인할 수 있다. 그렇다. 넷플릭스의 개인맞춤 홈화면 제공 핵심은 홈화면에 표시할 행을 선택하는 것이다. 그 방법은 다음과 같다.
•
유저와 가장 관심가질 만한 행을 선택하는 방법
•
해당 행을 관련 콘텐츠로 채우는 방법
•
시청할 콘텐츠를 직관적으로 선택하도록 페이지에 배열하는 방법
유저에게 가장 적극적으로 추천되는 행이 가장 상단에 오게 된다. 행에 표시되는 콘텐츠는 좌에서 우로 스크롤하여 볼 수 있는데, 각 행의 콘텐츠 배치 순서는 유저가 좋아할 만한 콘텐츠들 사이의 인기순위로 결정난다. 즉 화면 왼쪽 상단에 위치한 콘텐츠가 가장 내 취향을 저격하는 콘텐츠인 셈이다.
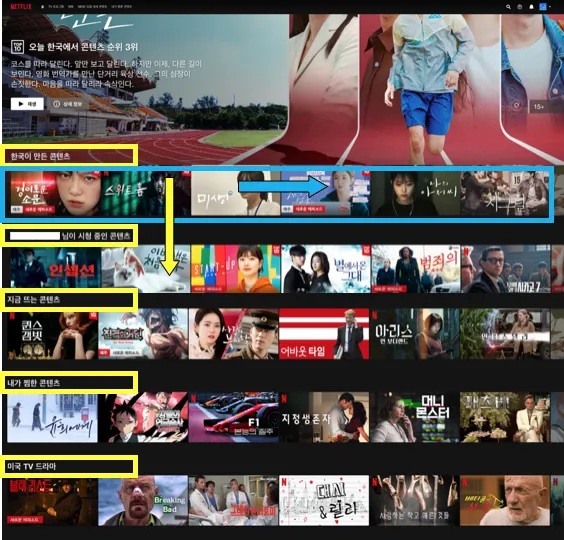
나의 경우를 예로 들면, '한국이 만든 콘텐츠'가 홈화면 최상단에 위치한 행이다. 해당 행의 콘텐츠는 '경이로운 소문 → 스위트룸 → 미생→런온' 순인데, 이 경우 넷플릭스 추천 시스템은 내 취향저격 콘텐츠가 '한국이 만든 콘텐츠' 행의 '경이로운 소문' 이라는 것이다. (이게 그렇게 재밌다는데 아직 못 봤다.)
간단하게 요약하면, 콘텐츠들을 기반으로 유저와 가장 관련있는 행들을 찾는다. 그 후 유저가 이미 시청한 콘텐츠 및 관람 등급 등을 고려하여 각각의 행들을 필터링한다. 필터링 후에는 각 행에 적절한 랭킹 알고리즘을 적용해 행의 콘텐츠들 순위를 매긴다. 그 결과 랭킹이 가장 높은 콘텐츠가 행의 가장 첫번째 자리(가장 왼쪽)에 위치한다. 행 별 콘텐츠 세트가 완성되면 행 선택 알고리즘을 통해 홈화면 전체 배열을 구상할 수 있다. 이때 여러 행에 걸쳐 추천되는 콘텐츠가 있을 수 있다. 예를 들면 내가 찜한 콘텐츠 행과 지금 뜨는 콘텐츠 행에서 추천하는 콘텐츠가 겹칠 수 있기에 중복방지 필터를 적용한다. 또한 넷플릭스에 접속하는 기기에 알맞은 콘텐츠 사이즈를 설정해두는 작업을 마지막으로 하게 된다.
그럼 조금 더 자세하게 넷플릭스가 내 취향저격 콘텐츠를 추천해주는 홈화면 구성을 어떻게 했는지 알아보자.
1.1. 한 눈에 보이는 레이아웃 찾기
넷플릭스는 유저들의 취향과 유사한 콘텐츠를 추천해주기 위해 노력한다. 하지만 동시에 유저의 취향과 관계없는 다양한 콘텐츠들을 또한 자주 노출시켜 클릭률/시청률을 늘리고 싶어한다. 그러나 유저들은 새로운 콘텐츠 보다 취향에 알맞게 추천된 콘텐츠들을 쉽게 찾을 수 있는 안정감을 원한다. 이 두 가지 니즈를 만족하기 위해 넷플릭스가 선택한 홈화면 방식은 행을 이용한 2차원 탐색 레이아웃이다.
행을 이용한 2차원 탐색 레이아웃을 통해 넷플릭스는 다양한 콘텐츠들을 유저에게 노출시킬 수 있고, 유저는 취향 저격 콘텐츠를 쉽고 빠르게 찾을 수 있게 되었다. 만약 추천된 행에 관심이 없다면, 유저는 화면을 아래로 스크롤 하여 해당 행을 건너뛰면 된다. 하지만 취향 저격 행을 찾았다면, 행을 좌우로 스크롤하여 취향과 관련된 더 많은 콘텐츠들을 찾아보고 시청할 수 있게 된다.
즉, 넷플릭스는 홈화면 전체에 노출되는 콘텐츠의 다양성을 유지하면서, 동시에 유저 취향에도 제격인 콘텐츠를 제공하는 관련성을 유지할 수 있게 되었다.
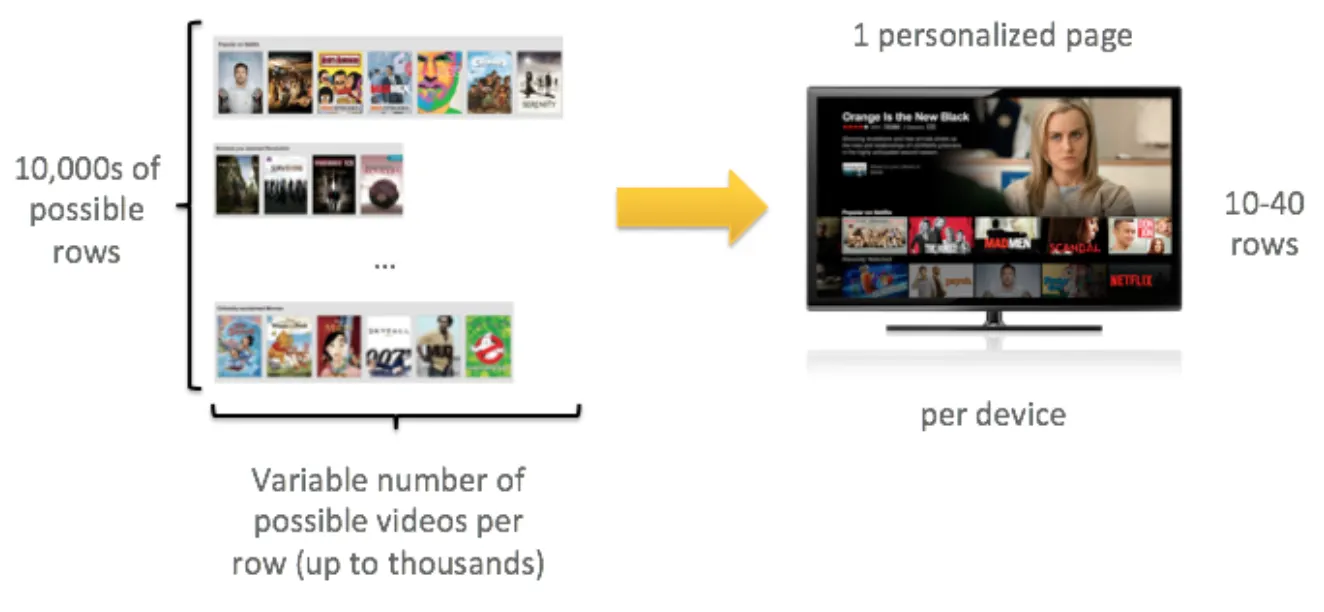
이때 넷플릭스가 보유한 콘텐츠 수를 고려하면, 행들과 콘텐츠들 역시 엄청 많다. 그런데 화면에 최대로 노출될 수 있는 행과 콘텐츠의 수는 제한적이다. 사용자는 10개에서 40개 정도의 행만 확인할 수 있고 한다. 이마저도 심지어 기기마다 다르다. 그래서 유저 취향저격 홈화면 구성에는 다음과 같은 문제들의 균형이 중요하다.
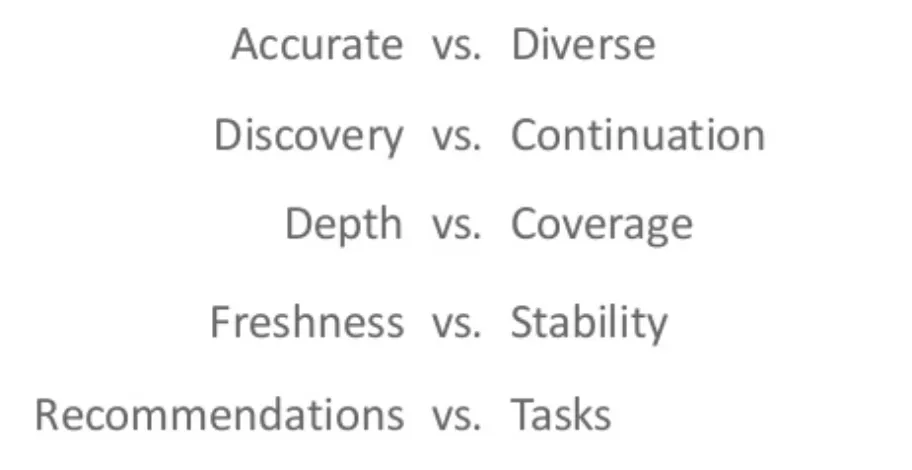
여기서 궁금한 점이 생긴다. 어떻게 위의 균형을 유지하면서 유저 취향저격의 홈화면을 구성할 수 있을까?
1.2. 넷플릭스가 홈화면 최적화를 위해 떠난 여정
•
Rule-based Approach
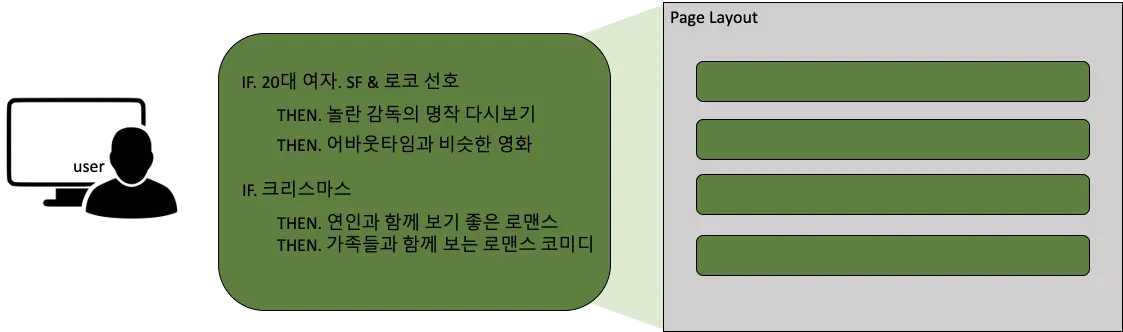
홈화면 구성을 위한 가장 보편적인 방법은 Rule-based approach이다. 여기서 Rule-based란, 홈화면의 행들이 어느 위치에 있어야 하는지 정해진 규칙에 따라 홈화면을 구성하는 방법을 의미한다. 초기에는 이 방법이 도움이 되었지만, 홈화면을 구성하는 행들의 콘텐츠 품질・다양성, 행과 사용자 간의 친밀도, 콘텐츠에 대한 사용자 노출 품질 등 콘텐츠 추천에 중요한 요소들을 고려하기에는 적절하지 않다. 또한 새로운 유형의 행을 추가하기 위해 행에 포함될 콘텐츠를 적절한 순서로 배열하고, 해당 행을 화면에 적절하게 배치해야 하는 등 여러 복잡도를 고려하지 않았다. 이렇듯 Rule-based approach는 시간이 지날 수록 규모의 문제가 발생하여 새로운 행을 추가하기가 어렵고, 다양한 행들과 이를 배치하는 방법 등을 모두 다루기에는 복잡도가 높아지는 문제가 있다.
•
Row-Ranking Approach
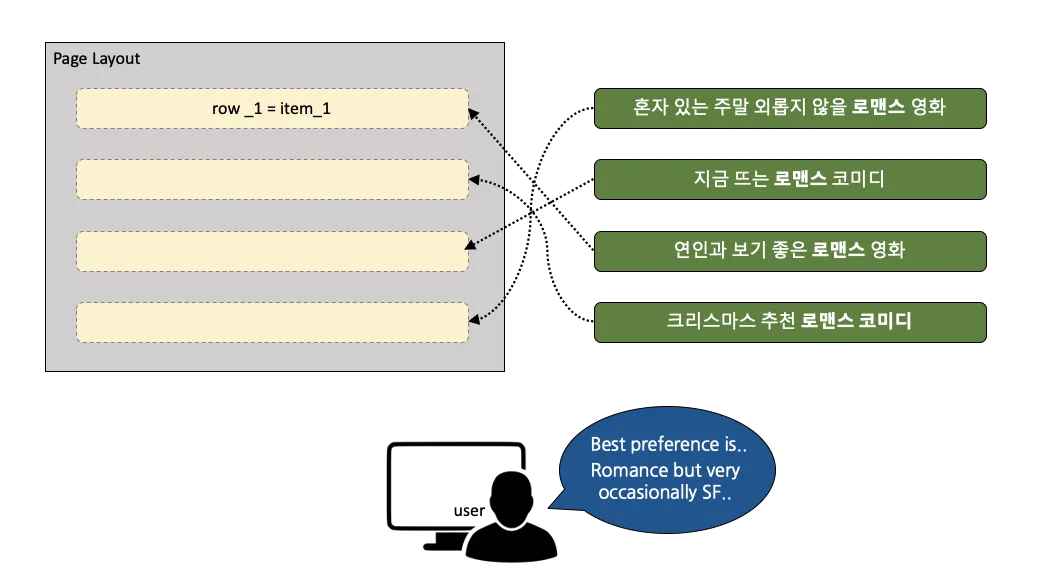
이러한 이슈를 해결하기 위해 넷플릭스는 유저 맞춤형 행 순서 방안을 고안했다. Row-ranking approach의 경우 랭킹 문제에서 행을 아이템으로 간주하는 방법이다. 이렇게 되면 홈화면을 채울 행을 선택하는 방식으로 기존의 Top-N 추천 알고리즘을 활용한다. 이전 행과 홈화면에 대해 이미 선택한 콘텐츠와의 관계도 고려하는 방식이다. 이 경우 행이 차지하는 공간은 커지지만, 상대적으로 빠르고 높은 정확도를 얻을 수 있다. 그러나 보통 유저의 선호는 크게 바뀌지 않는다. 따라서 유저가 가장 선호하는 것과 관련된 행들만 끊임없이 홈화면 상단에 노출되는 문제가 생긴다. 즉, 다양성을 고려하지 않는다는 문제가 발생한다.
그렇다면 다양성을 어떻게 고려할 수 있을까?
•
Stage-wise Approach
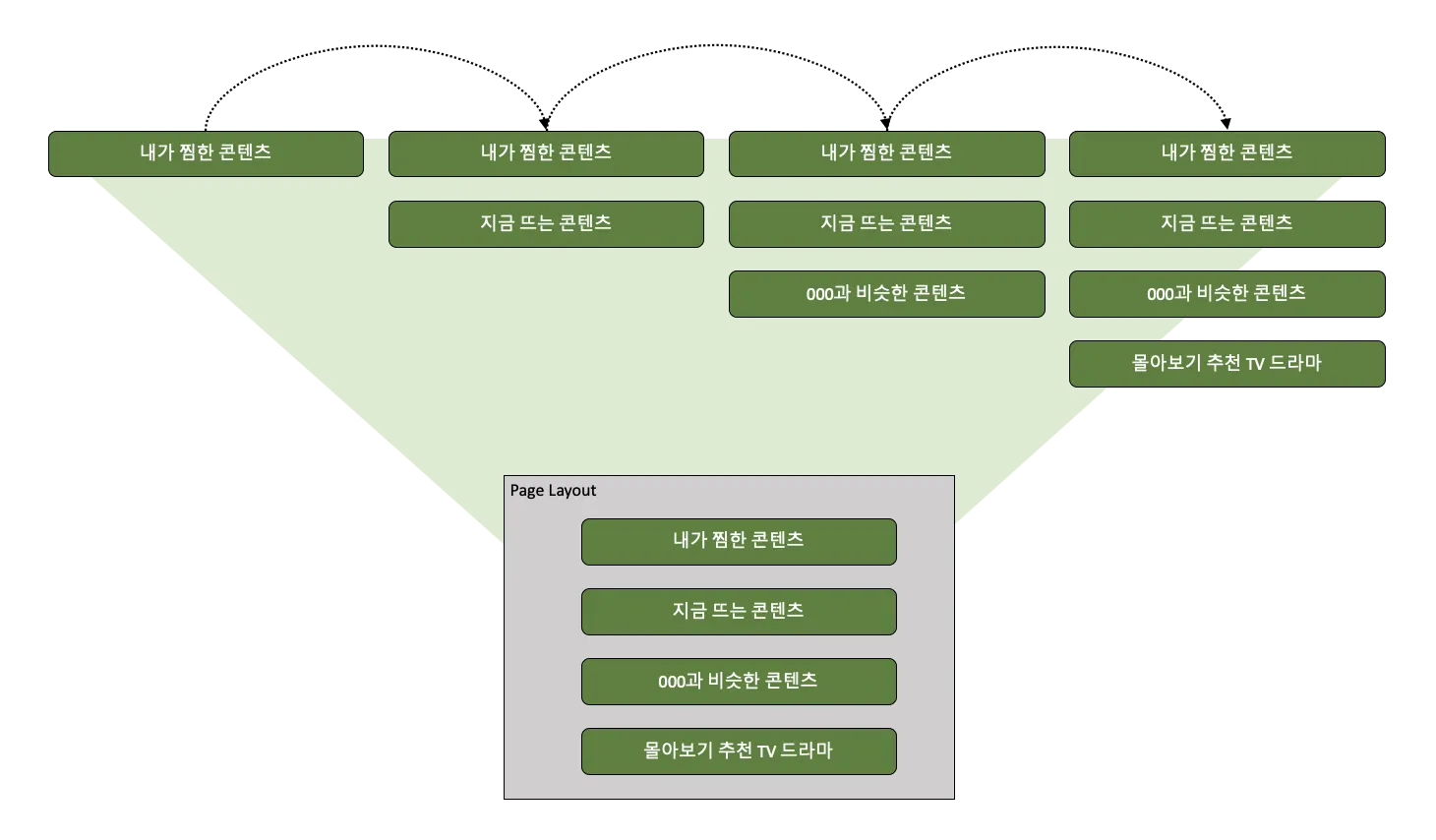
다양성을 고려하기 위해서 Stage-wise approach를 적용한다. Stage-wise approach는 이미 선택한 행의 정보를 통해 스코어링을 하는 것이다. 초기에는 그리디(greedy) 방식으로 사용되었는데, 이 경우 그리디 방식 본연의 한계로 현재의 선택이 다음에 어떤 영향을 미치는지 알 수 없었다. 결과적으로 최적의 홈화면을 구성하지 않을 수 있다. 따라서 k-row lookahead를 Stage-wise approach에 적용해 보았는데, 이는 그리디 방식보다 나은 홈화면을 구성해주지만 매 단계마다 행들간 콘텐츠 중복 여부를 확인해야 한다. 또한 여전히 다음에 올 행만을 고려하므로 홈화면 전체의 완성도는 떨어질 수 있다.
그렇다면 어떻게 해야 홈화면 전체의 완성도를 잡을 수 있을까?
•
Page-wise Approach
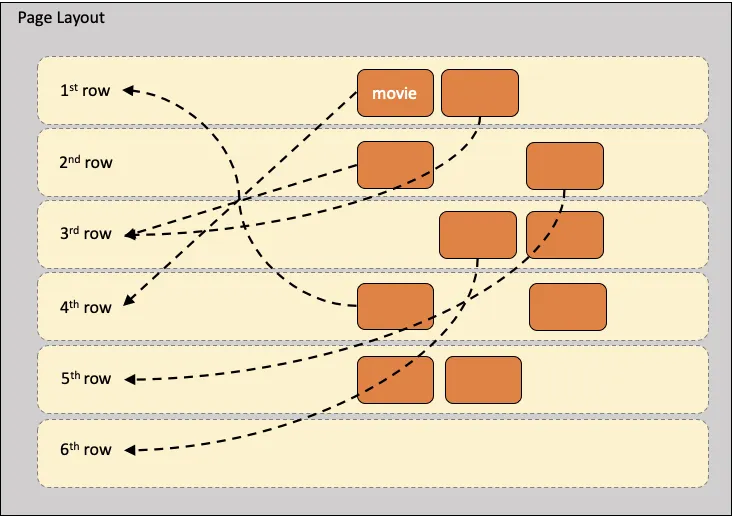
전체 홈화면 스코어링인 Page-wise approach를 적용하면 홈화면 전체를 보면서 행들과 콘텐츠의 적절한 위치를 배치할 수 있다. 적절한 행과 콘텐츠들이 선택되어 최적의 홈화면을 유저에게 제공할 수 있다. 행과 열을 함께 고려하기에 계산복잡도는 매우 크게 올라간다.
이 외에도 홈화면을 구성할 때 유저가 홈화면을 탐색하는 패턴을 고려하는 것도 중요하다. 홈화면에서 어떤 위치를 유저가 자주 보고 어떤 패턴으로 움직이는지 유저의 홈화면 탐색 과정을 고려해야 한다. 그 결과 왼쪽 상단 모서리에 유저의 취향저격 끝판왕인 콘텐츠를 놓으면 유저가 가장 빠르고 쉽게 원하는 콘텐츠를 찾을 수 있었다.
그러나 2차원 홈화면에서 탐색을 모델링 하는 것은 어렵다. 유저마다 홈화면을 탐색하는 패턴이 다를 수 있고, 유저의 탐색 패턴이 시간마다 변할 수도 있다. 또한 접속하는 기기에 따라 탐색 방법에 차이가 생기도 하고, 노출되는 콘텐츠와 유저 간의 관련성에 따라 유저가 홈화면을 탐색하는 패턴은 달라진다. 비 선형적 복잡도를 다루는 방법하면 역시 머신러닝이다. 그래서 넷플릭스는 머신러닝 방법을 고려했다.
1.3. 홈화면 생성에서 생기는 다양한 문제들
머신러닝을 위해 쓸 수 있는 피처들이 recency, user-row interactions, item-row metadata, affinity 등등 엄청 많다. 문제는 쓸 수 있는 피처들이 너무 많은데 이 모든걸 머신러닝으로 스코어링 하기가 다음과 같은 이유로 어려웠다.
•
presentation bias
넷플릭스의 추천 엔진을 통해 제공된 홈화면의 결과라 유저의 자연스러운 행동이 아닐 수 있다. 즉 얻은 원본 데이터가 이미 편향되어 있을 확률이 높고 그 결과 훈련데이터가 좋지 않을 수 있다.
•
position bias
홈화면에서 행이 어디에 위치하는지에 따라 유저가 취향저격 콘텐츠를 못 봤을 수도 있다. 같은 콘텐츠여도 행이 상단에 있으면 볼 확률이 높지만, 하단에 있다면 못보고 지나쳤을 수 있다. 그래서 취향저격 콘텐츠여도 유저에게 선택되지 않아서 추천 리스트에서 사라졌을 수도 있다.
이와 같은 편향에 대해 고려하지 않고 유저의 히스토리 데이터를 무작정 사용하면 안된다. 그래서 넷플릭스는 훈련데이터를 고르는데에 신경을 엄청나게 많이 썼다.
이외에도 attribution-어떤 성격의 행에서 콘텐츠가 노출되었는지- 역시 고려되어야 한다. 예를들어 같은 콘텐츠여도 '신작' 이라는 행에 있는지 아니면 '극찬 받은 다큐멘터리'라는 행에 있는지에 따라 유저가 해당 콘텐츠를 클릭할 확률이 크게 차이가 난다. 같은 콘텐츠여도 '신작' 행으로 상단에 위치하는 것보다, 아래라도 '극찬 받은 다큐멘터리'라는 문구의 행에 콘텐츠가 있는 경우가 더 나을 수도 있다.
또한 diversity 역시 여전히 학습하기가 쉽지 않다. 넷플릭스에 접속하는 기기가 다양해질 수록 더 어려워지고 있다. 기기별 화면 사이즈에 따라 유저에게 보여지는 행과 콘텐츠의 갯수가 달라진다. 다시말해, 티비로 넷플릭스를 보는 경우 화면 사이즈가 커서 다양성이 증가하는 반면, 핸드폰으로 보는 경우 화면 사이즈가 매우 작아 다양성이 감소할 수 밖에 없었다.
이와같은 문제들을 고려해서 넷플릭스는 훈련 데이터를 세심하게 발라냈고 스코어링 메트릭을 설계했다. 그럼 스코어링 메트릭으로 어떤 메트릭을 사용했는지 알아보자.
1.4. 넷플릭스의 홈화면 레이아웃 메트릭
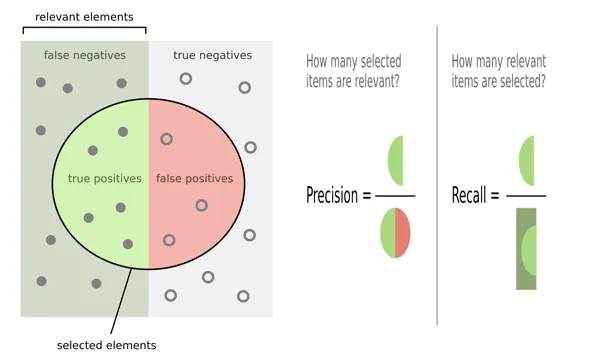
넷플릭스는 유저 맞춤형 홈화면 레이아웃이 얼마나 좋은 성능을 보이는지 평가하기 위해 Recall 방식을 사용했다. 보통의 검색엔진등에서 잘 쓰이는 메트릭은 recall@n이다.
•
Recall
Recall은 실제 유저가 원하는 콘텐츠들(정답)을 얼마나 추천 엔진이 다 골라냈는지를 점수화한 것이다. (Recall = 추천 엔진이 뽑은 콘텐츠들 중 정답 / 실제 정답 전체) 문제는 추천 엔진이 무한히 많은 콘텐츠를 뽑을 수록, 실제 유저가 원하는 콘텐츠들을 맞출 확률이 높아진다. 즉 recall 점수가 올라가는 왜곡이 발생한다.
•
Recall@n
추천 엔진이 제안을 많이 할 수록 recall 점수가 올라가는 문제를 방지해야한다. 그래서 추천 엔진이 추출하는 갯수를 n개로 제한했을 때, 그 중에서 실제 유저가 원하는 콘텐츠(정답)가 몇 개나 포함되는가로 문제를 방지할 수 있는데 이것이 Recall@n이다. 다시 말해 실제로 유저가 관심있는 콘텐츠 중 넷플릭스가 추천한 콘텐츠의 비율을 의미한다. 예를 들어 쉽게 설명해보자.
•
전체 콘텐츠 중 유저가 실제로 관심 있는 콘텐츠 4개
•
넷플릭스가 추천한 콘텐츠 5개
•
추천한 콘텐츠 중 유저가 관심있어 하는 콘텐츠 3개
→ Recall = 3/4 이 된다.
넷플릭스는 2차원 홈화면 레이아웃의 랭킹 퀄리티 측정을 위해 Recall@n을 응용한 메트릭을 사용했다.
•
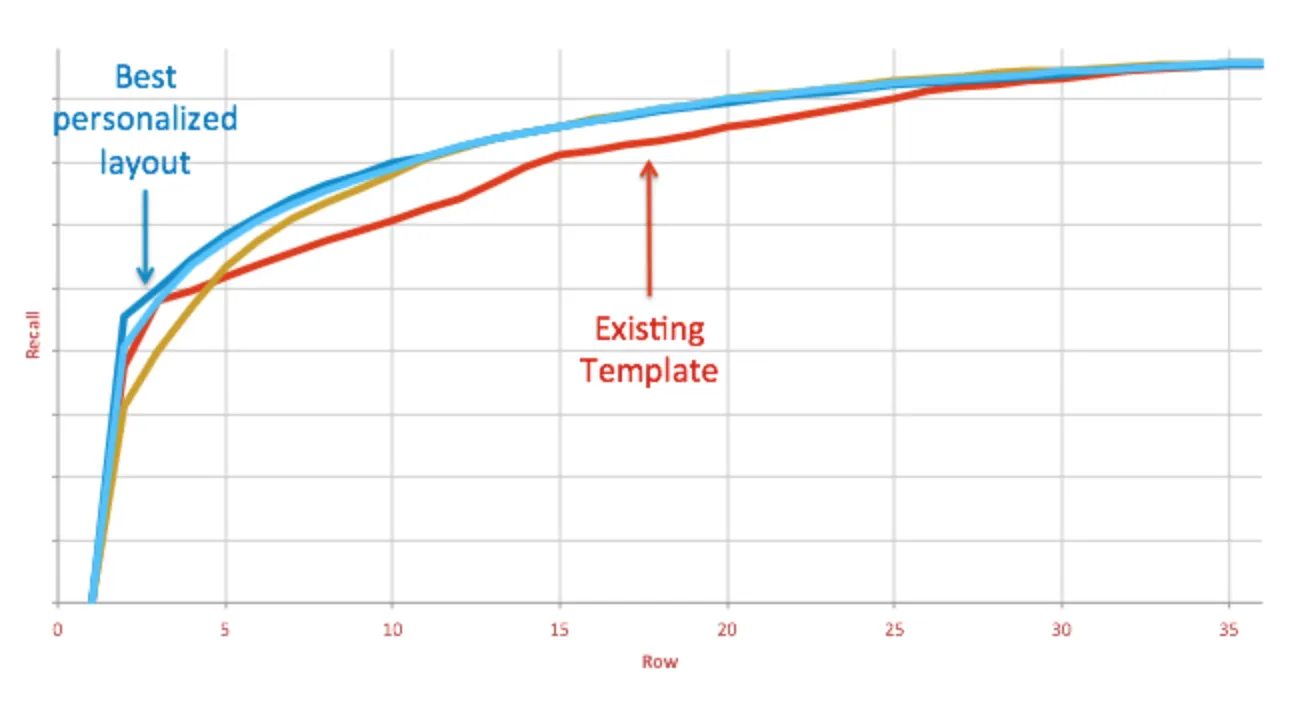
Recall@m-by-n
넷플릭스는 2차원 홈화면 레이아웃 랭킹 퀄리티 메트릭으로 Recall@m-by-n을 사용했다. 이를 통해 첫 번째 m-행 n-열에 추천된 콘텐츠들 중 얼마나 유저의 취향과 일치하는지 측정했다.

2차원 Recall Metrics 그림으로 예를 들어 설명해보자.
•
Page Variant 1의 경우, 유저가 관심있는 콘텐츠 3개 중, 첫 행에서 1개를 맞췄다. 나머지에서는 맞추지 못해서 1/3이다. 1개 밖에 맞추지 못해 좋은 홈화면 레이아웃이 아니다.
•
Page Variant 2의 경우, 유저가 관심있는 콘텐츠 3개 중, 첫 행에서는 0개, 두 번째 행에서는 1개를 맞춰 1/3, 세 번째 행에서 1개를 더 맞춰, 총 2/3이다. 하지만 첫 행에서 정답을 맞추지 못했기에 좋은 홈화면 레이아웃은 아니다.
•
Page Variant 3의 경우, 유저가 관심있는 콘텐츠 3개 중, 첫 행에서 2개, 두 번째 행에서 1개를 맞췄다. 총 3개를 전부 맞췄다. 3번째 행에서도 맞췄지만 1번째 행과 중복되므로 필터링 된다. 이 경우가 위의 그림 중 가장 좋은 홈화면 레이아웃이 된다.
Recall의 장점은 중복된 콘텐츠 또는 짧은 행들 같은 코너케이스(corner-case)를 처리할 수 있다. 또한 행이나 열 중 하나를 고정하고 다른 값을 움직이면서도 Recall 값을 계산할 수 있다.
이외에도 nDCG, MRR로도 2차원 메트릭을 확장할 수 있다. 또한 Expected Reciprocal Rank와 같은 탐색 모델을 조정하여 홈화면을 통한 2차원 탐색을 통합할 수 있다.
2. Conclusion
넷플릭스는 여전히 홈화면 상 유저의 탐색 패턴과 각종 비용들간의 절충안을 찾고 있다. 그리고 유저들에 대한 최소 정보로 어떻게 최적의 홈화면을 구성할 수 있을지도 끊임없이 고민하고 있다. 이 글을 통해 넷플릭스가 유저 취향 저격 콘텐츠를 제공하기 위해 홈화면에서 어떤 방식의 추천 시스템을 적용해왔는지 알 수 있었다.
놀라웠던 점은 2015년 넷플릭스는 이미 콘텐츠 유통업으로 큰 기업이었지만, 최적의 홈화면 레이아웃 구축을 위해 적용한 방식은 fine-grained한 방식이 아닌, 쉽고 간단하며 누구나 적용해 볼 수 있는 방식부터 시작했다는 것이다. 간단한 rule-based를 시작으로 조금씩 살을 덧붙여가다 보니 그 결과 넷플릭스만의 유저 취향저격 홈화면을 구축하게 되었다.
또한 추천 엔진의 데이터가 얼마나 세심하게 선택되야 하는지 그리고 이미 우리의 활동으로 유저들의 데이터가 편향되어 있을 수 있다는 사실이 추천 공부를 시작한지 얼마 안된 나에게는 새로웠다. 넷플릭스가 고려한 요소들인 훈련 데이터 세심한 선택 및 스코어링 기능들은 추천 엔진을 적용한 서비스라면 항시 고려되야하는 요소들임을 알 수 있었다.
친구네 집에서 넷플릭스로 신나게 영화를 다보고 집에 와서 내가 보고싶은 영화를 보려고 다시 넷플릭스를 켰다.
그런데 특이한 점을 발견했다. 분명 친구 넷플릭스 계정에서의 영화 포스터가 내 계정에서는 다른 포스터로 노출되고 있었다. 분명 같은 영화인데...보여주는 포스터가 다를 수 있다니 신기했다.
같은 서비스를 이용하는데 왜 콘텐츠 이미지가 다른 경우가 있을까? 도대체 어떤 알고리즘으로 사용자마다 다른 포스터를 볼 수 있게 제공하는 것일까?
⇒ 다음 글 Art Selection에서 이를 알아보려 한다.
기대하시라. 후후
참고자료