


안녕하세요. Physics-based Humanoid Control in AI Robotics를 전공하고 있는 이민경입니다. 2020년에 잠시 추천시스템에 흥미가 생겨서 개인적으로 공부했습니다. 다양한 딥러닝, 로보틱스 관련 공부도 하면서 논문들 읽고 재구현하는 것을 좋아해요.
 Email: blossominkyung@gmail.com
Email: blossominkyung@gmail.com•
이번 리뷰 논문은 Factorization Machine 관련 논문인 Huifeng Guo의 "DeepFM: A Factorization-Machine based Neural Network for CTR Prediction" 입니다.
Summary
본 논문은 새로운 신경망 아키텍처에서 특성 학습(Feature Learning)을 위해 Feature Engineering이 필요하지 않고 End-to-End 학습을 할 수 있는 FM Component와 Deep Component로 구성된 DeepFM 모델을 제안한다.
Content
클릭율(CTR, Click-Through Rate)은 추천 시스템에서 매우 중요하다. 여러 추천시스템에서 클릭율을 높이는 것을 목표로 삼고 있는데 추정되는 CTR에 의해 아이템 랭킹을 알 수 있고 이를 사용자에게 추천할 수 있게 된다. 또한 온라인 광고 같은 애플리케이션들은 수익 창출 및 증대 역시 중요한 목표이고 이를 위해 CTR x bid 로 랭킹 전략을 세울 수 있다. (여기서 bid는 사용자가 아이템을 클릭할 경우 해당 앱 시스템이 받는 수익을 의미한다.)
이와 같이 사용자 클릭 이면의 Implicit Feature Interaction을 통해 학습하는 것이 CTR 예측에서 중요하다. 사용자 클릭 이면의 Feature Interaction은 매우 복잡하기 때문에, 저차원과 고차원 상호작용 모두 중요하다. 이를 위한 핵심 문제는 Feature Interaction을 효과적으로 모델링하는 것이다.
Factorization Machines은 쌍별 Feature Interaction을 Feature간의 잠재 벡터의 내적으로 모델링하는데 매우 좋은 결과를 보여준다. 또한 Deep Neural Network 역시 복잡한 Feature Interaction을 학습할 수 있는 잠재력을 가지고 있다.
DeepFM논문은 Feature Engineering 없이 종단간 방식으로 모든 차원의 Feature Interaction을 학습할 수 있는 학습 모델을 다음 그림과 같이 제안한다.
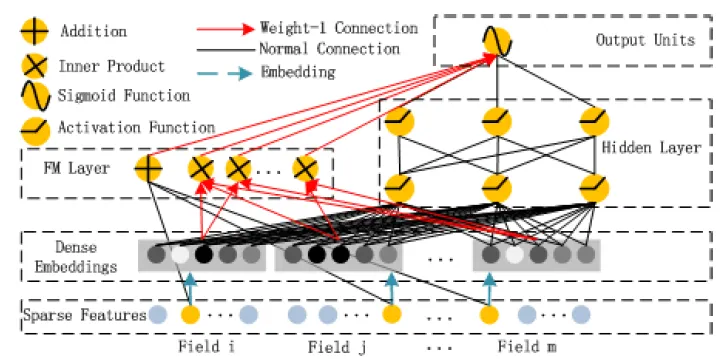
Figure from the DeepFM paper: Wide & Depp Architecture of DeepFM
•
DeepFM은 FM 모델과 DNN 모델이 결합된 새로운 아키텍처이다. 저차원의 Feature Interaction은 FM으로 모델화되고 고차원의 Feature Interaction은 DNN을 통해 모델화 된다. DeepFM은 Feature Engineering 없이 End-to-End 학습을 한다.
•
DeepFM은 Wide 파트와 Deep 파트는 같은 Input과 임배딩 벡터를 공유하기 때문에 효율적이게 훈련할 수 있다.
•
본 연구는 벤치마크 데이터와 상업적 데이터 모두를 가지고 DeepFM를 평가한다. 이를 통해 CTR 예측을 위한 기존 모델보다 개선된 점을 보여준다.
1. Proposed Approach
개의 인스턴스를 가진 학습 데이터셋 이 있다고 가정해보자. 이때 는 사용자-아이템 한 쌍을 표현하는 개의 필드 데이터 레코드이다. 는 사용자 클릭을 가리키는 라벨이다.
에는 범주형 변수(e.g., gender, location)와 연속적 변수(e.g., age)가 포함될 수 있다. 범주형 변수는 원핫인코딩 벡터로 표현되고, 연속적 변수는 값 자체 또는 이산화된 원핫인코딩 벡터로 표현된다. 그러면 인스턴스는 로 표현 할 수 있는데, 여기서 는 차원벡터 구조이고, 를 예로들면, 에서 번째 필드의 벡터값을 의미한다. 대개 는 고차원이고 매우 희소하다.
CTR은 사용자에게 context가 주어진 경우 사용자가 특정 앱을 클릭할 확률을 추정하는 모델을 구축하는 것이 목적이다.
1.2. DeepFM
본 논문은 저차원 & 고차원 Feature Interaction 모두 학습하는 것을 목표로 한다. 이를 위해 본 논문이 제안하는 DeepFM은 같은 Input을 공유하는 FM Component와 Deep Component로 구성되어 있다.
•
: 번째 feature에 대한 스칼라 값으로 1차원의 중요도를 측정한다.
•
: 잠재 벡터(Latent Vector)로 다른 features과의 상호작용의 영향을 측정한다.
◦
FM Component ⇒ 2차원 Feature Interaction 모델화
◦
Deep Component ⇒ 고차원 Feature Interaction 모델화
를 포함하는 모든 파라미터들과 을 포함하는 네트워크 파라미터들은 다음의 통합 예측 모델에서 함께 훈련된다.
1.2.1. FM Component
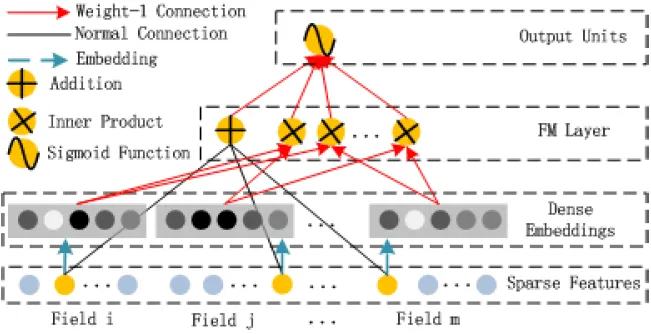
Figure from the DeepFM paper: FM Component Architecture
FM Component는 추천을 위해 Feature Interaction을 학습하는 Factorization Machine(FM)이다. FM은 각 Feature 잠재 벡터의 내적으로 쌍으로 (2차원) Feature Interaction을 모델화한다. 특히 데이터셋이 희소한 경우, 훨씬 더 효과적으로 2차원 Feature Interaction을 포착할 수 있다. 또한 FM은 잠재 벡터로 내적하기 때문에 Feature Interaction에 훨씬 더 효율적이고 유연하다.
FM의 Output은 Addition Unit과 Inner Product Unit의 합으로 다음과 같이 표현된다.
•
Addition Unit : 1차원 Features의 중요도를 반영한다.
•
Inner Product Unit : 2차원 Feature Interactions의 영향을 나타낸다.
1.2.2. Deep Component
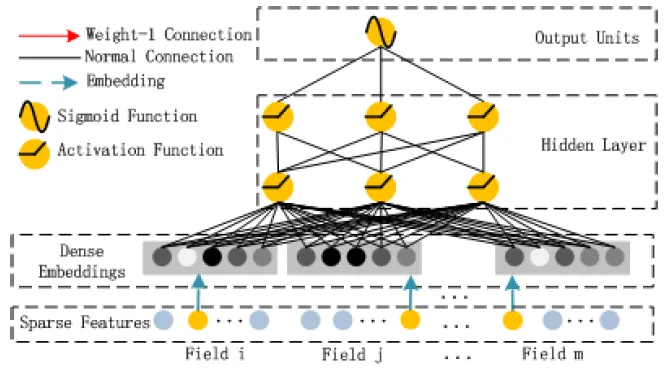
Figure from the DeepFM paper: Deep Component Architecture
Deep Component는 고차원 Feature Interactions를 학습하기 위한 Feed-Forward Neural Network이다. 위 그림과 같이 데이터 레코드(벡터)는 NN에 입력된다. 그러나 CTR 예측을 위한 Raw Feature Input 벡터는 매우 희소하고, 고차원이며, 범주형/연속형 데이터가 섞여 있고, gender/location/age 처럼 필드로 그룹화 되어있다. 이와 같은 Input vector를 Embedding Layer로 압축하여 저차원의 Dense한 실수 벡터로 가공해야 과도한 훈련과정을 방지할 수 있다.
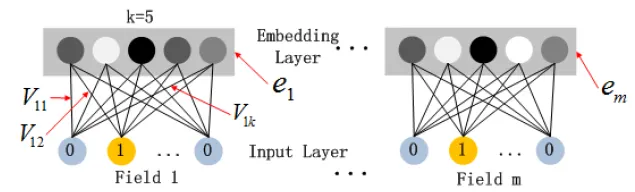
Figure from the DeepFM paper: Embedding Layer Structure
Deep Component의 Embedding Layer은 두 가지 흥미로운 특징이 있다.
•
Input 값인 Field Vector의 길이는 서로 다를 수 있지만, Embedding 크기는 로 동일하다.
•
FM 모델에서 Latent Feature Vector()는 Input 값인 Field Vector를 Embedding Vector로 압축하는데 사용되고 학습되는 네트워크 가중치로의 역할을 한다.
Embedding Layer의 Output은 다음과 같다.
•
: i번재 필드의 임배딩
•
: 필드 수
•
: DNN으로의 공급
Forward Process는 다음과 같다.
•
: 레이어 깊이
•
: 활성 함수
•
: Ouput, 모델 가중치, 번째 층의 편향
이를 통해 Dense한 실수 Feature 벡터가 형성되면 CTR 예측을 위해 Sigmoid 함수로 표현한다.
•
: 은닉계층의 수
여기서 FM Component와 Deep Component는 같은 Feature Embedding을 공유한다는 측면에서 다음과 같이 중요한 이점이 있다.
1.
Raw Feature에서 저차원 & 고차원 Feature Interaction을 모두 학습한다.
2.
전문적인 Feature Engineering이 불필요하다.
2. Relationship with the Other NNs
기존 연구들과 본 논문이 제안하는 DeepFM을 비교 분석하면 다음과 같은 결과를 볼 수 있다.
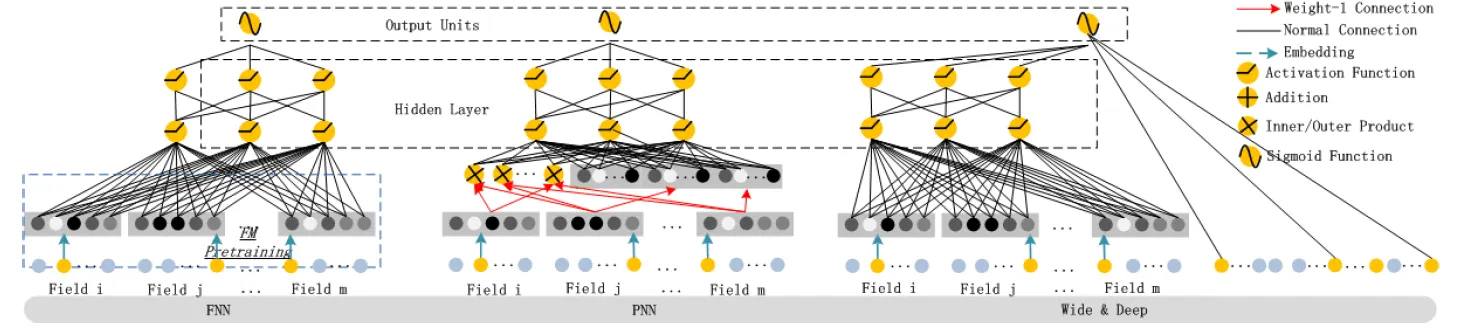
Figure from the DeepFM paper: FNN, DNN, Wide & Depp model for CTR Prediction
•
◦
FM을 사전 초기화 하는 Feed-Forward Neural Network 모델
◦
FM 사전 훈련 전략의 2 가지 한계 존재
1.
Embedding 파라미터는 FM의 영향을 받을 수 있다.
2.
사전 훈련 단계에서 도입된 오버헤드로 효율성이 저하된다.
⇒ DeepFM의 경우
◦
사전 훈련 불필요하다
◦
저차원 및 고차원 모두 Feature Interaction 학습한다.
•
◦
고차원 Feature Interaction을 포착하기 위해 Embedding 계층과 첫 은닉 계층 사이에 Product 계층을 추가한 모델
◦
Product 동작에 따라 : IPNN(내적), OPNN(외적), PNN(내적 외적 둘다)으로 구분
◦
계산을 더 효율적이게 하기 위해 내적(뉴런제거) & 외적(차원압축) 모두 근사 계산
◦
PNN의 3 가지 한계 존재
1.
벡터 외적에서 정보손실 많다.
2.
PNN의 내적은 게산 복잡도가 높다
3.
저차원 Feature Interaction이 무시된다.
⇒ DeepFM의 경우
◦
Product 계층의 Output이 오직 뉴런 1개만 있는 최종 출력 계층에만 연결된다
•
◦
저차원 및 고차원 Feature Interaction을 동시에 모델링하기 위해 제안
◦
Wide 파트의 Input 값을 위해 전문적인 특성 공학(Feature Engineering) 요구됨
⇒ DeepFM의 경우
◦
전문적인 지식 없어도 Input 값인 Raw Features로부터 직접 학습하여 Input 처리 가능
다시 말해, DeepFM은 사전 훈련도 불필요하고 특성 공학(Feature Engineering)도 불필요한 모델이며 저차원 & 고차원 Feature Interaction 모두 포착할 수 있는 유일한 모델이다.
3. Experiments
3.1. Experiment Setup
Datasets
1) Criteo Dataset : 4천 5백개의 사용자 클릭 레코드 데이터셋으로 13개의 연속형 특성들과 26개의 범주형 특성들로 구성되어있다. 본 논문은 훈련:테스트 = 9:1 의 비율로 무작위하게 나누어 진행했다.
2) Company Dataset : DeepFM이 실제 산업에서의 CTR 예측에도 DeepFM 성능을 검증하기 위해 채택된 데이터 셋으로 훈련을 위해 회사 앱 스토어의 게임 센터에서 7일 연속 사용자 클릭 기록을 수집하고 테스트를 위해 하루 동안 사용자 클릭 기록을 수집하였다.
전체 수집된 데이터 셋에는 대략 1억개 정도의 레코드가 있고, 데이터셋은 앱 특성(신분, 범주 등) , 사용자 특성(사용자가 다운로드한 앱 등), Context 특성(사용시간 등)들로 구성되어 있다.
Evaluation Metrics - AUC 와 Logloss(cross entropy)
Model Comparison
9가지 모델을 비교하였다: LR, FM, FNN, PNN(3 variants), Wide&Deep, DeepFM
Parameter Setting
•
dropout: 0.5
•
network structure: 400-400-400
•
optimizer: Adam
•
activation function: tanh for IPNN, relu for others
3.2. Performance Evaluation
두 데이터셋 상에서 유효성과 효율성을 비교
Efficiency Comparison :
에 따라 효율성을 평가하였고 결과는 다음 그래프와 같다.
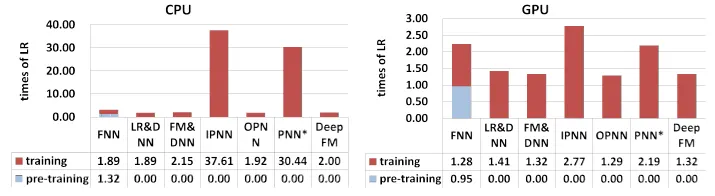
Figure from the DeepFM paper: Time Comparison
•
FNN의 사전 훈련은 효율이 낮다
•
IPNN과 PNN의 속도가 GPU 상에서 높지만 내적 계산의 비용이 높다.
•
DeepFM이 CPU와 GPU상에서 가장 효율적이다.
Effectiveness Comparison :
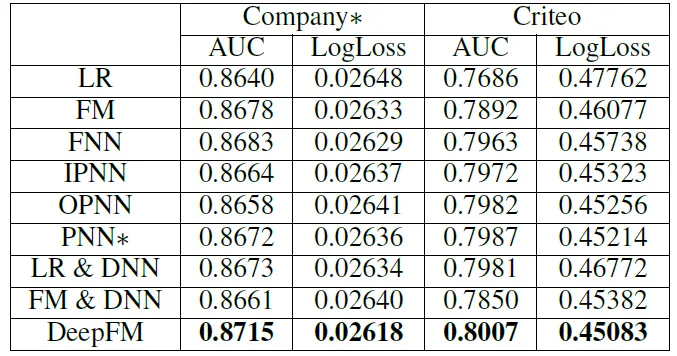
Figure from the DeepFM: CTR Prediction Performance
이를 통해 우리는 DeepFM 모델이 기존의 모델들 보다 우수하다는 것을 알 수 있다.
3.3. Hyper-Parameter Study
Deep 모델들의 다양한 하이퍼파라미터의 영향을 연구한다: Activation Function, Dropout, Number of Neurons per Layer, Number of Hidden Layers, Network Shape
4. Conclusions
본 논문은 CTR 예측을 위한 Factorization-Machine 기반의 Neural Networks 모델인 DeepFM을 제안하였다. DeepFM은 FM Component와 Deep Component 가 함께 훈련되는 모델로서, 사전 훈련이 필요하지 않고, 저차원&고차원 Feature Interactions 모두 학습하며, Feature Engineering을 피하기 위한 Feature Embedding의 공유 전략을 도입했다는 장점이 있다.