
2022년 CVPR에서 발표된 “Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation” 논문을 정리했습니다.
 Summary
Summary이동할 환경을 보지 않은 상태에서 언어 지시에 따라 이동하는 것이 agent에게 챌린지이다. agent는 시각적 장면에서 언어를 기반으로 하지만, 목표에 도달하기 위해 환경을 탐색해야한다. 논문에서는 공동의 장기 액션 플래닝과 세분화된 크로스 모달 이해를 위해 토폴로지 매핑 모듈과 글로벌 액션 플래닝 모듈로 구성된 DUET을 제안하고 있다. 토폴로지 매핑 모듈을 통해 agent는 시간이 지남에 따라 토폴로지 맵을 구축하며 글로벌 액션 플래닝 모듈을 통해 글로벌 액션 공간에서 효율적인 탐색을 할 수 있게 된다. 또한 큰 그래프에서 세분화된 언어 그라운딩과 액션 공간 추론의 복잡성 사이에서 균형을 맞추기 위한 동적 결합을 제안하고 있다.
Insights1.
대규모의 액션 공간 추론과 세분화된 언어 근거 간의 균형을 맞추기 위해 로컬 관측에 대한 fine-scale encoding과 그래프 트랜스포머를 통한 글로벌 맵에 대한 coarse-scale encoding을 dynamic fusion.
2.
노드와 지시 간의 관계를 모델링하는 cross-attention layer와 환경 레이아웃을 인코딩하는 GASA layer를 제안. 특히 GASA의 경우, 그래프 구조를 추가로 고려한 attention을 통해 노드 간의 시각적 유사성으로 인한 이슈를 해결.
3.
pseudo interactive demonstrator(PID)를 통해 정책을 추가로 훈련했는데, 대부분의 연구들이 강화학습을 선택하는 점에서 새로웠다.
Future works실험에서 보여준 눈에 보이는 환경과 보이지 않는 환경 간의 격차로 인한 문제를 해결할 계획.
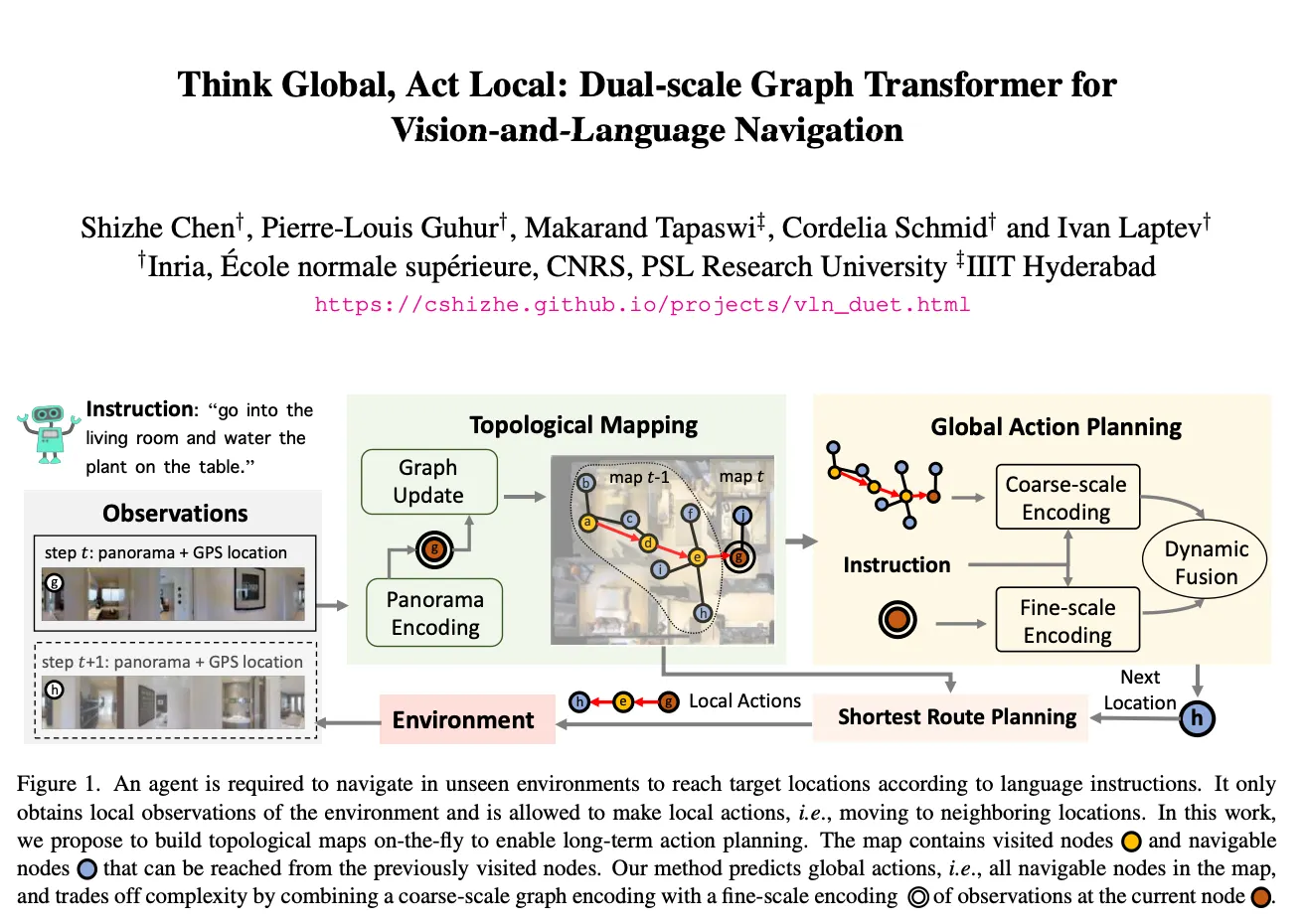
Vision-Languag Navigation(VLN)에서 새로운 지역이나 이전의 올바른 결정들을 효율적으로 탐색하기 위해서 agent는 메모리 내에서 이미 실행된 지시나 방문한 위치를 추적해야 한다. 특히 언어 지시를 따르고 보이지 않은 환경에서 목표 위치에 도달하기 위해 탐색을 해야 한다.
Problem Statement
•
VLN의 많은 연구들이 RNN을 통해 메모리를 구현하고 탐색 기록을 고정 크기 벡터에 압축한다.
◦
이러한 방법은 이전 경험을 풍부한 시공간 구조로 저장하고 활용하기에 비효율적이다.
•
RNN의 한계를 보완한 연구들이 있는데 과거 관찰과 행동들을 저장하고 트랜스포머를 통해서 행동 예측을 위한 장기적 의존성을 모델링한 방법들이다.
◦
문제는 이들 역시 로컬 액션, 즉 인접한 위치로의 이동만을 고려한다.
•
잠재적인 해결책은 지금까지 관찰된 모든 방문 및 탐색 가능한 위치를 명시적으로 추적하는 토폴로지 맵을 구축하는 것으로 이를 통해 agent는 장기적인 탐색 계획을 세울 수 있게 된다.
◦
토폴로지 맵을 사용한 이전 연구들 있는데 다음과 같이 두가지 측면에서 여전히 한계가 존재한다.
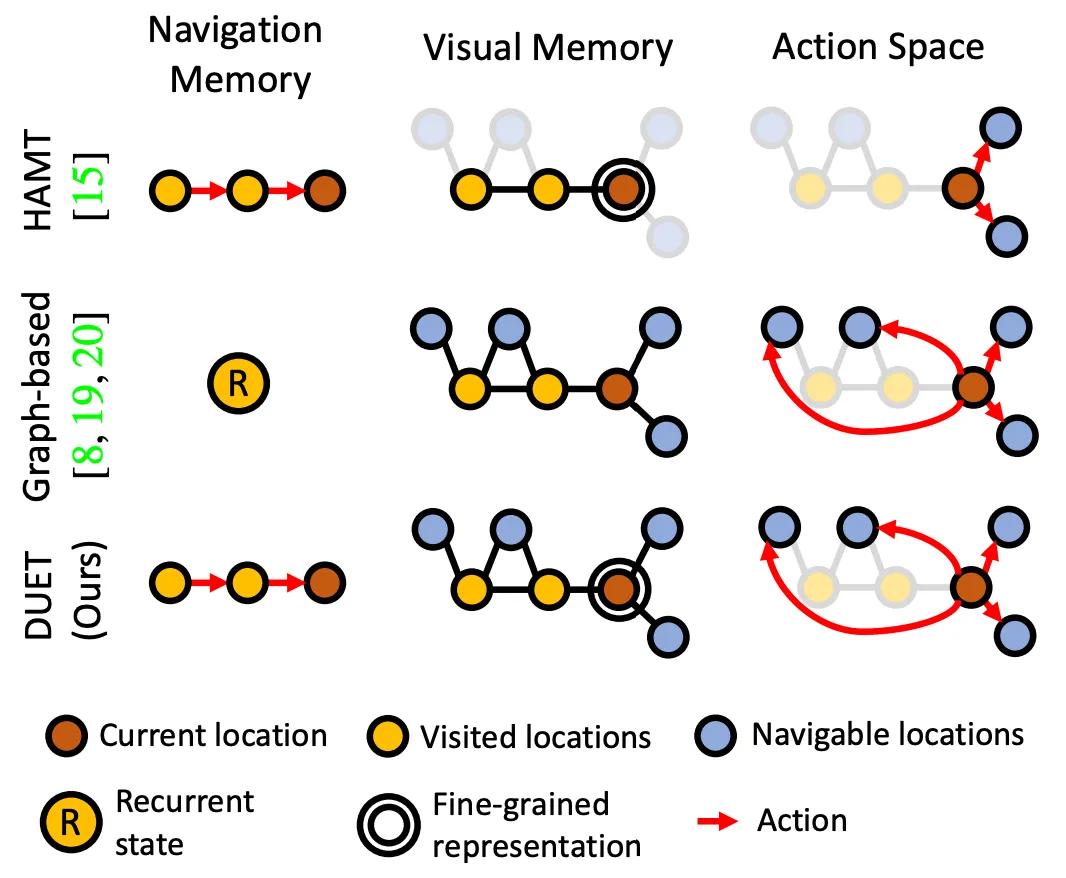
1.
왼쪽 그림의 Graph-based 부분과 같이 네비게이션 상태를 트래킹하기 위해 RNN에 의존
a.
exploration을 위한 장기적인 추론 능력에 큰 장애가 될 수 있다.
2.
토폴로지 맵의 각각의 노도는 일반적으로 압축된 시각적 피처들로 표현
a.
이와같은 coarse한 표현은 복잡성을 줄이지만 지시에서 세분화된 객체 및 장면 설명을 뒷받침하기엔 디테일이 부족할 수 있다.
•
따라서 본논문은 이슈들을 해결하기 위해 그림1처럼 Dual-Scale graph Transformer (DUET)을 제안한다.
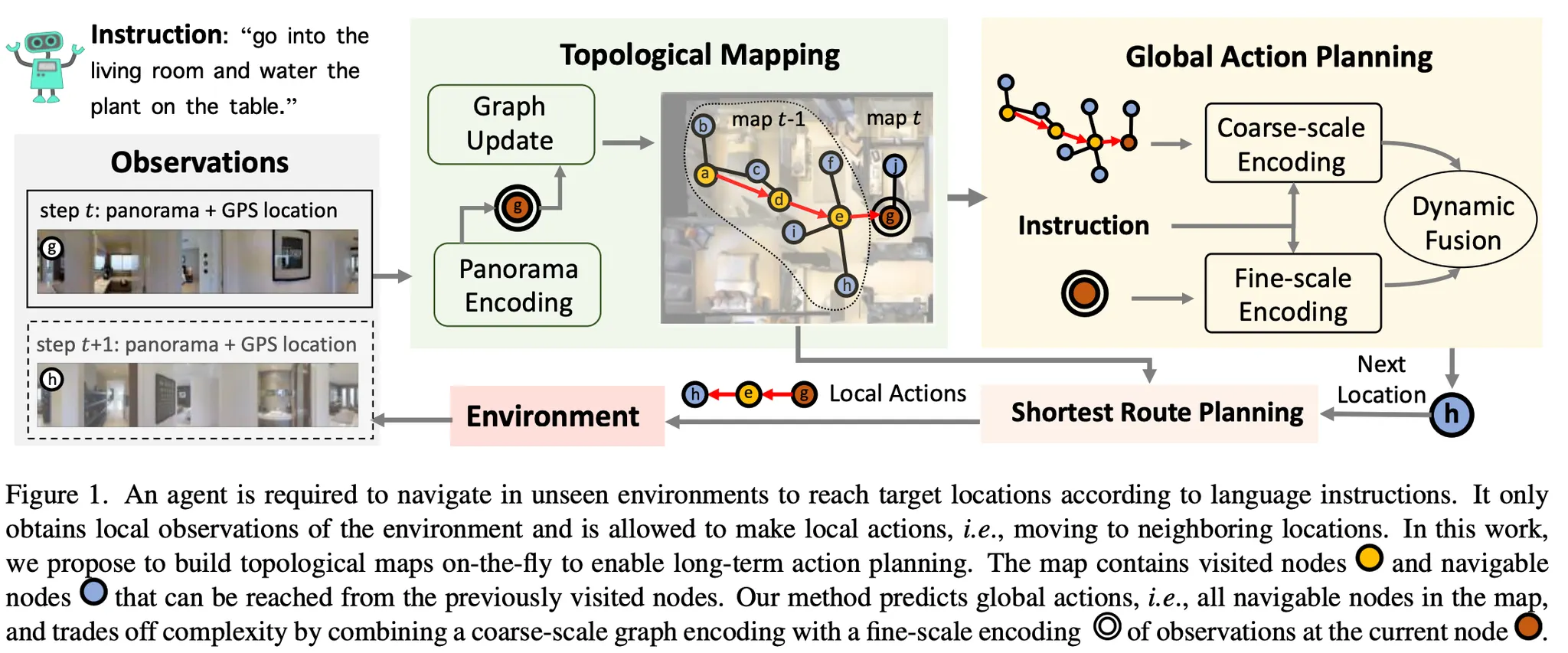
논문이 제안하는 DUET은 Topological Mapping과 Global Action Planning 모듈로 구성되어 있다.
DUET에 대해 간단하게 설명하자면,
1.
topological mapping
a.
새로 관찰된 위치 맵에 추가 + 노드의 시각적 표현 업데이트 → 시간이 지남에 따라 토폴로지 맵 구축.
2.
global action planning
a.
다음 위치나 스탑 액션을 예측.
3.
dynamic fusion
a.
큰 그래프에서 세분화된 언어 그라운딩과 추론 사이의 균형을 맞추기 위해.
b.
fine-scale local observation + coarse-scale global observation
⇒ dual-scale action prediction & reasoning
4.
training
a.
behavior clonning과 auxiliary task로 모델 사전훈련
b.
pseudo interactive demonstrator 제안 → policy learning 개선.
•
-? behavior cloning
◦
순차적인 예측을 위해 가장 널리 사용되는 훈련 알고리즘
◦
훈련과 테스트 사이의 분포 변화로 인한 한계가 존재
◦
이를 위해 스케줄 샘플링, DAgger, RL 등 다양한 방법들이 제안됨. 대부분은 behavior cloning과 A3C(RL)을 결합하는 방식을 채택.
•
하지만 리워드가 희박한 테스크에서 RL을 사용하는 것은 어렵기 때문에
◦
본논문은 interactive demonstrator를 사용해서 전문가를 모방하고 순차적인 훈련에서 감독을 제공하는 방식을 사용
Approach
•
agent의 목표
◦
지시어를 해석하고 그래프를 따라 목표 위치로 이동하여 지시에 지정된 object를 찾는 것.
◦
따라서 agent가 어떤 위치에서 멈춘 뒤, 파노라마 안에서 목표 위치를 예측하는게 필요.
•
Exploration & language grounding
◦
agent에게 필수적인 능력
◦
기존의 연구는 로컬 액션만 허용 → long-range action planing을 방해 또는 object representation 부족 → fine-grained grounding에 불충분
따라서 본논문은 이중 스케일 표현과 글로벌 액션 플래닝으로 두가지 이슈를 해결한다.
Topological Mapping
agent는 초기에 env-graph를 모른다. 따라서 agent는 경로를 따라 관찰한 내용을 사용하여 점차적으로 자체 맵을 구축하게 된다. 또한 agent는 현재 노드와 방문한 노드에 대한 파노라마 뷰에 액세스할 수 있다. 맵에서 탐색 가능한 노드는 아직 탐색하지 않은 곳이고 이미 방문한 위치에서 부분적으로 관찰된 곳들이기에 다른 시각적 표현을 갖는다. 탐색 가능한 노드에서 새로운 관찰이 주어지면 현재 노드와 탐색 가능한 노드의 시각적 표현이 그림3처럼 업데이트 된다.(이때 세가지 노드타입이 있는데 이는 다음과 같다: (1) 노랑노드: 방문한 노드 (2) 파랑노드: 탐색가능한 노드 (3) 빨강노드: 현재 노드.)

•
Visual representation for nodes
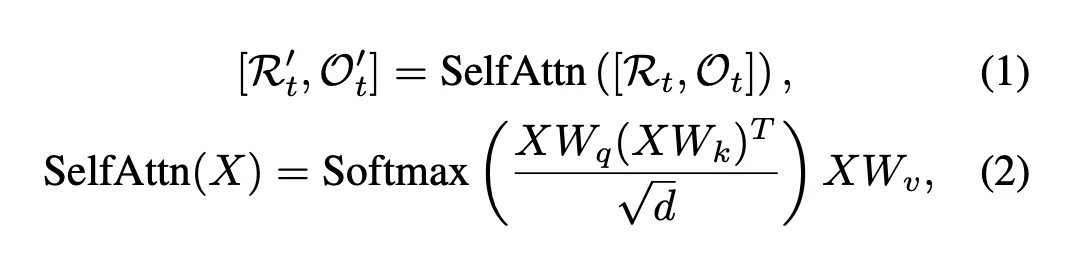
◦
image와 object 간의 공간적 관계를 모델링하기 위해 multi-layer transformer 사용.
◦
coarse-scale representation은 큰 그래프에 대한 효율적인 추론을 가능하게 하지만, object에 대한 fine-grained language grounding을 마련하기에는 충분한 정보를 제공하지 못할 수 있다.
◦
현재 노드에 대한 fine-grained visual representation으로 image feature와 object feature를 유지하여 fine-scale의 세부 추론을 지원한다.
Global Action Planning
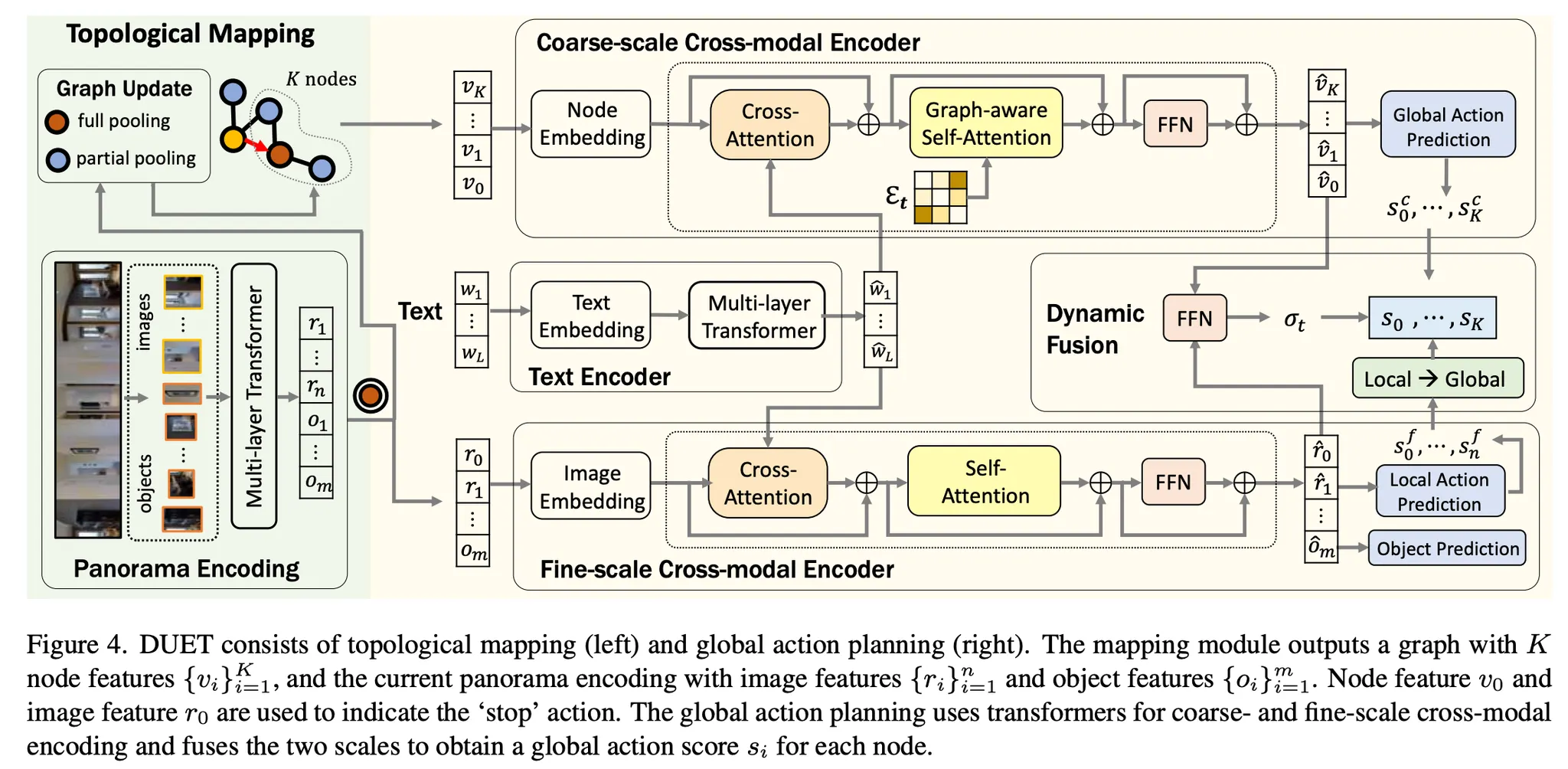
그림4를 보면 coarse-scale encoder는 이전에 방문한 모든 노드에 대해 예측을 수행하지만 coarse-scale visual representation을 사용한다. 대신 fine-scale encoder는 현재 위치에 대한 fine-grained visual representation을 사용해서 local action을 예측한다. dynamic fusion은 글로벌 액션과 로컬 액션에 대한 예측을 결합한다.
•
Coarse-scale Cross-modal Encoder
◦
global action space를 넘어서는 네비게이션 예측을 생성
1.
Node Embedding
•
노드의 시각적 피처에 위치 인코딩과 네비게이션 단계 인코딩 추가.
•
위치 인코딩은 현재 노드를 기준으로 한 방향과 거리인 자기중심 뷰로 맵에 노드의 위치를 임베딩
•
네비게이션 단계 인코딩은 방문한 노드에 대해 가장 최근에 방문한 시간 단계를 임베딩하고 탐색하지 않은 노드에 대해 0을 임베딩.
•
이런 방법으로 방문한 노드는 지시와의 정렬을 개선하기 위해 다른 네비게이션 히스토리로 인코딩됨.
2.
Graph-aware Cross-modal Encoding
•
인코딩된 노드와 단어 임베딩은 multi-layer graph aware cross-modal transformer로 입력
•
트랜스포머 레이어는 노드와 지시 간의 관계를 모델링하는 cross-attention layer와 env-layout을 인코딩하는 graph-aware self-attention(GASA) 레이어로 구성
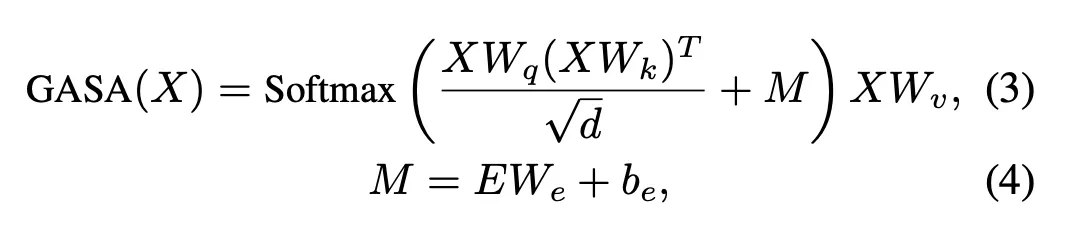
◦
앞의 식(2)는 노드 간의 시각적 유사성만 고려하기 때문에 먼 노드보다 관련성이 높은 가까운 노드를 간과할 수 있다.
◦
따라서 식(3)처럼 그래프 구조를 추가로 고려해서 attention을 계산하는 GASA 제안.
3.
Global Action Prediction
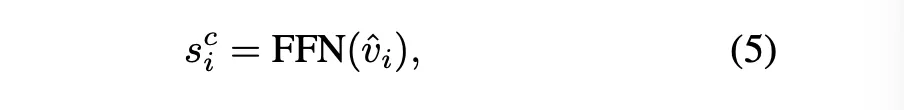
•
그래프 내의 각 노드의 네비게이션 스코어 예측
•
대부분의 VLN 테스크는 agent가 노드를 다시 방문할 필요가 없다.
◦
특별하게 언급하지 않는 이상 방문한 노드에 대한 스코어는 마스킹한다.
•
Fine-scale Cross-modal Encoder
◦
맵에서 현재 위치에 주목하여 fine-scale cross-modal reasoning을 가능하게 한다.
◦
지시와 현재 노드의 fine-grained 시각적 표현을 입력값으로 받는다.
◦
모듈은 로컬 액션 공간에서 네비게이션 액션을 예측하고 최종 시간 단계에서 object를 그라운딩.
1.
Visual embedding
•
두가지 유형의 위치 임베딩 추가
(1) 시작 노드를 기준으로 한 맵의 현재 위치
(2) 현재 노드에 대한 각 이웃 노드의 상대적인 포지션.
•
인코더가 자기중심적 방향을 구현하는 데 도움됨.
2.
Fine-grained Cross-modal Reasoning
•
vision-language 관계를 모델링 하기 위해 multi-layer cross-modal transformer 활용.
3.
Local action prediction and Object grounding
•
로컬 액션 공간에서 네비게이션 스코어 예측
•
목표지향적 VLN은 object grounding이 필요 → FFN 통해 객체 스코어 추가 생성.
Dynamic Fusion
•
더나은 글로벌 액션 예측을 위해 coarse-scale과 fine-scale 동적으로 결합.
•
fine-scale encoder는 coarse-scale encoder와 일치하지 않는 로컬 액션 공간에서 액션을 예측.
•
따라서 로컬 액션 스코어를 글로벌 액션 공간으로 변환.
•
현재 노드와 연결되지 않은 다른 미탐색 노드로 이동하려면 agent는 인접한 방문 노드를 역추적해야 함.
•
전환된 글로벌 액션 스코어는 다음과 같다.

•
최종 네비게이션 스코어는 다음과 같다.
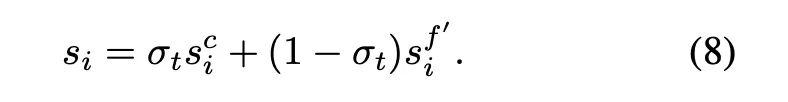
Experiments
Datasets
•
REVERIE : 목표 위치와 object를 묘사한 높은 수준의 지시 데이터셋
•
SOON : 목표 방들과 object들을 묘사한 지시 데이터셋 (단 object boxes 제공하지 않음)
•
R2R : 단계별 네비게이션 지시들 데이터셋
Evaluation Metrics
1.
Navigation metrics.
•
trajectory length(TL)
◦
average path length in meters
•
navigation error(NE)
◦
average distance in meters between agent’s final location and the target
•
success rate(SR)
◦
the ratio of paths with NE less than 3 meters
•
oracle SR (OSR)
◦
SR given oracle stop policy, SR penalized by Path Length(SPL) - the success rate under oracle stop policy
2.
Object grounding metrics.
•
remote grounding success(RGS)
◦
the proportion of successfully executed instruction
•
RGSPL
◦
RGS penalized by Path Length
Ablation study
•
Ablation study는 REVERIE 데이터셋으로만 진행

1.
[표1] Coarse-scale vs. fine-scale encoders
•
표 첫줄과 두번째 줄 지표를 비교해봤을 때 SR/OSR 을 제외하고 나머지는 coarse-scale의 성능이 좋은 것을 알 수 있다.
◦
coarse-scale의 경우 RGS, RGSPL 지표가 없는데, coarse-scale 인코더의 경우 object representation이 안됨. 즉 fine-grained visual representation만 목표 위치를 확인할 수 있음.
◦
대신 coarse-scale의 경우 구축된 맵의 이점을 활용해 높은 OSR, SPL 메트릭으로 더 많은 영역을 효율적으로 탐색할 수 있음
2.
[표1] Dual-scale fusion strategy
•
[Q?] 어떤 지표는 average가 높고 어떤 지표는 dynamic이 높은데 그 이유가 뭘까? 제안한 사항은 multi-scale에서의 dynamic인데 그럼 어떤 어떤 지표를 우선으로 보는게 맞을까. 그냥 multi-scale이 전반적으로 높다는거에 의의를 두는건가? multi에서 SR, SPL은 dynamic이 높아서 효율적인 탐색이 average보다 잘되는구나를 알 수 있지만 RGS는 낮고 RGSPL은 높아서 object representation은 multi에서 fusion에 크게 영향을 받지 않는다고 해석하면 되려나.
3.
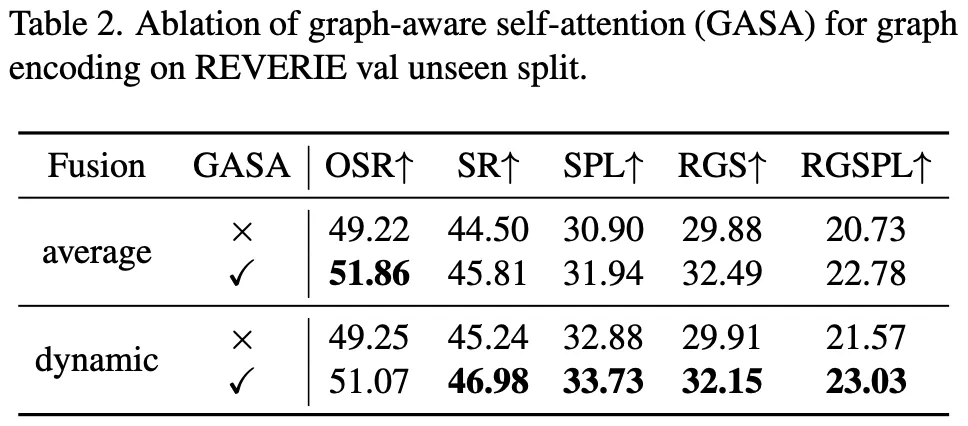
[표2] Graph-aware self-attention
•
“Graph-aware”가 짧은 거리에서의 목표 탐색을 강조하는 SPL 점수를 향상시키는 데 더 유리하다는 걸 알 수 있다.
•
[Q?] 왜 동적일때 GASA를 적용하면 더 두드러지게 지표가 좋아질까?

4.
[표3] Training Losses
•
여러 훈련 손실을 비교한 실험인데 pretrain에서 auxiliary proxy task인 MLM과 MRC를 추가했을 때, object grounding에 해당하는 성능만 개선된 것을 볼 수 있다.
•
파인튜닝으로는 강화학습 또는 PID를 비교했는데. 전반적으로 PID가 RL보다 뛰어남을 볼 수 있다.
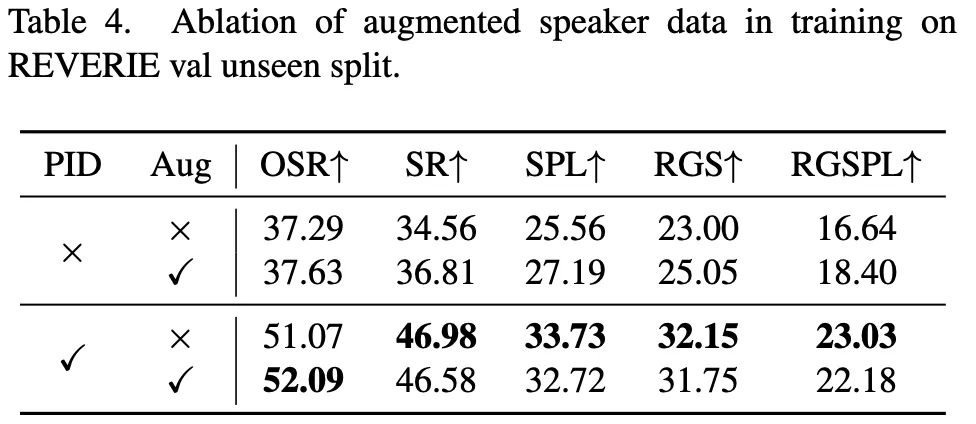
5.
[표4] Data augmentation with synthetic instructions
•
데이터 증강 여부에 따른 사전 학습 결과를 보여주는 실험으로 일반적으로 증강된 데이터가 사전훈련에서 유용하다는 걸 알 수 있다.
•
그런데 policy를 개선하기 위해 PID를 사용한 경우 데이터 증강을 해도 성능 개선 없다.
◦
사전학습의 auxiliary proxy task는 노이즈가 있는 증강된 데이터를 활용하는데 도움되지만,
◦
policy를 학습할 때는 여전히 클린한 데이터가 필요하다는 걸 보여준다.
•
[Q?] 추가적으로 궁금한건 ablation study에서 왜 REVERIE 데이터셋만 가지고 실험했을까? 최신 연구와의 비교에서 보면 REVERIE, SOON, R2R 데이터셋이 달라서 각각의 결과 지표도 다르던데.
Comparison with state-of-the-art

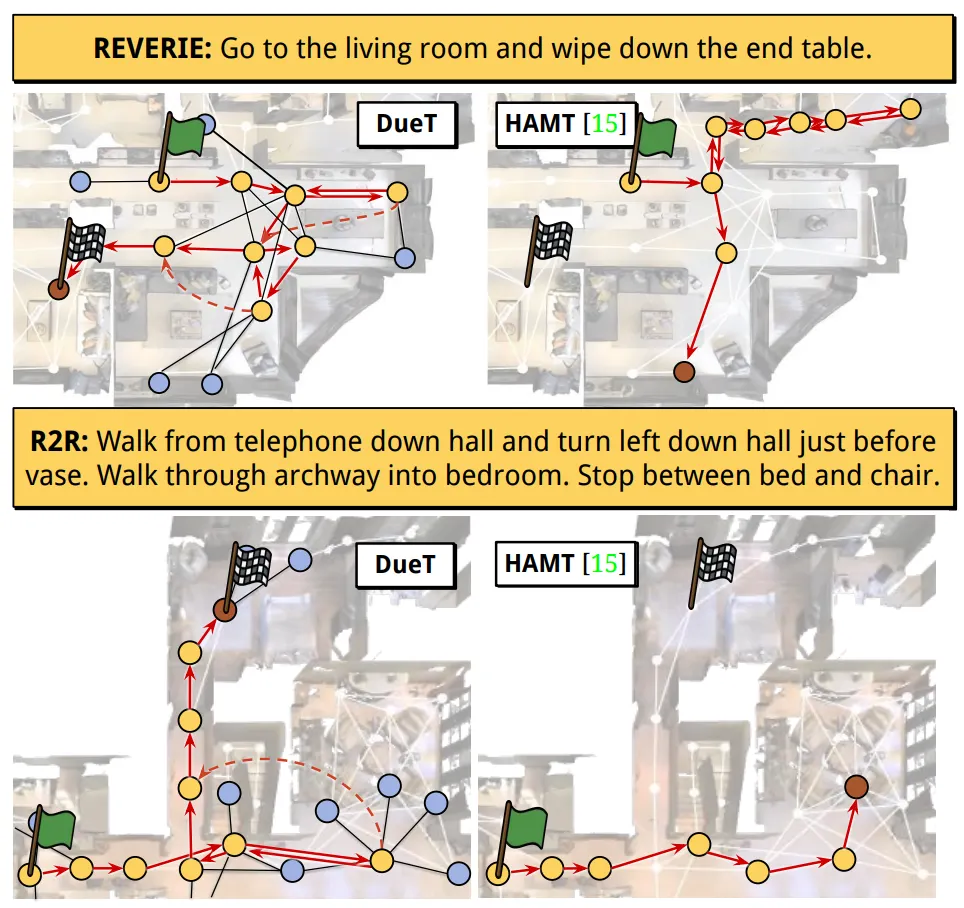
•
표7처럼 R2R 데이터셋을 통한 추가적인 실험에 대해 이야기 하자면, 논문이 제안하는 DUET의 SR은 최근 연구들 보다 우수하다. 그러나 SPL에서는 다른 연구들과 비슷한걸 볼 수 있다.
◦
왜냐하면 이는 맵 기반의 경우 역추적이 권장되서 궤적 길이가 길어지기 때문이다.
이 논문은 공동의 장기 액션 플래닝과 세분화된 크로스 모달 이해를 위한 DUET을 제안하였다. agent가 즉석에서 토폴로지 맵을 구축하며 글로벌 액션 공간에서 효율적인 탐색을 가능하게 한 점이 흥미로웠다. 또한 대규모의 액션 공간 추론과 세분화된 언어 근거의 복잡성 사이에서 균형을 맞추기 위해 로컬 관측에 대한 세밀한 인코딩과 그래프 트랜스포머를 통한 글로벌 맵에 대한 거친 인코딩을 동적으로 결합한 것이 새로웠다.
coarse-scale cross-modal encoding에서 노드와 지시 간의 관계를 모델링하는 cross-attention layer와 env-layout을 인코딩하는 GASA 레이어를 제안한 부분 역시 인상 깊었다. 특히 GASA의 경우 그래프 구조를 추가로 고려한 어텐션을 통해 관련성이 높은 가까운 노드를 간과하는 이슈를 해결했다.
글에서는 설명하지 않았지만 논문의 policy learning 부분도 굉장히 흥미로웠다. 논문에서는 DAgger와 유사한 pseudo interactive demonstrator(PID)를 통해 정책을 추가로 훈련했다. 대부분의 연구들이 강화학습을 선택하는데 PID로 훈련한 점 역시 새로웠다.
하지만 실험에서 보여준 눈에 보이는 환경과 보이지 않는 환경 간의 격차를 통해 DUET 역시 개별 환경으로 제한되어있다는 걸 알 수 있었고, REVERIE 데이터셋을 통한 실험에서 세밀한 장면 이해가 여전히 까다롭기에 정확한 위치에 agent가 도달하는 것이 여전히 챌린지라는 걸 알 수 있었다.
그리고 실험에 대해 궁금한 부분들이 글에 적은 것 외에 몇 개 더 있었는데 몇 개는 돌려보면 해결 될 것 같고, 아직 논문 appendix까지 자세히 안읽은 상태라 해결될 지는 잘 모르겠다.