
2022년 NeurIPS에서 Google Research가 발표한 “Zero-shot Transfer Learning within a Heterogenous Graph via Knowledge Transfer Networks”논문과 Google Research Blog에 기재된 “Teaching old labels new tricks in heterogenous graphs”에 대해 정리한 글입니다.
 Summary
Summary본논문은 리얼월드에서 다양한 유형을 가진 데이터의 통합적인 시각을 위해Heterogeneous Graphs를 사용하는 방법을 설명하고 있다. Heterogeneous Graph Neural Networks는 각 노드의 관계를 요약하는 노드 임베딩을 학습한다. 그러나 실제 상황에서는 서로 다른 노드 유형 간에 레이블 불균형으로 인해 학습이 어려운 문제가 발생한다. 이 문제를 해결하기 위해 본논문은 HGNN을 위한 Zero-shot transfer learning module인 Knowledge Transfer Networks을 제안한다. KTN은 HG에서 제공되는 풍부한 관계 정보를 통해 label이 풍부한 노드 유형에서 zero-label 노드 유형으로 지식을 전송한다.
Insights•
HGNN 환경에서 흔하게 발생하는 레이블 불균형 문제를 해결하기 위해 제로샷 전이학습 방법을 사용해서 레이블이 없는 타겟 노드를 레이블이 풍부한 소스 노드로의 변환 행렬로 표현하는 방법인 KTN을 제안.
•
실험에서 6개의 다른 HGNN 모델의 타겟 노드 유형에 KTN을 사용했을 때 다른 베이스를 적용했을 때보다 성능이 월등히 뛰어남을 확인.본논문이 제안한 KTN이 HGNN 모델에서 보편적으로 사용하기에 적합.
•
KTN을 통해 외부 정보 없이도 자체 그래프 데이터 구조를 통해 더 나은 학습 가능 및 추가적인 데이터셋 없이도 모델 품질 보존 가능.
Future research•
HG에서 서로 다른 노드 유형에서 실행되는 서로 다른 테스크 간에 지식을 전공하는 작업으로의 확장.

Domain
•
Heterogenous Graphs
•
Heterogeneous Graph Neural Networks
리얼월드 환경은 내부 로그에서 파생된 대규모 관계형 데이터셋을 보유하고 있고, 이는 여러 유형의 노드와 엣지로 구성된 Heterogeneous Graph(HG)로 표현되거나 결합될 수 있다. 예를 들어, 이커머스 환경에서는 [제품, 사용자, 리뷰] 노드가 있고, 이들은 지출(사용자-제품), 리뷰(사용자-리뷰), 리뷰에 대한(제품-리뷰) 처럼 상호 작용을 나타내는 여러 엣지 유형으로 표현될 수 있다. 따라서 HG의 복잡한 멀티모달 구조를 나타내는 피처를 학습하기 위해 Heterogenous Graph Neural Network(HGNN)이 제안됐다.
여기서 HGNN은 노드와 이웃 노드의 정보를 포함해서 각 노드의 로컬 구조를 요약하는 노드 임베딩을 계산한다. 이러한 노드 임베딩은 분류기가 각 노드의 레이블을 예측하는데 활용된다. 특정 노드 유형에 대한 레이블을 예측하기 위해 HGNN 모델과 분류기를 훈련하려면 해당 유형에 대해 충분한 양의 레이블이 필요하다.
문제는 레이블 희소성인데, 다양한 노드 유형으로 인해 HGNN의 경우 이 문제에 직면할 가능성이 훨씬 높다.
Problem Statement
Label Imbalance(Scarcity)
앞서 언급한 것과 같이 HGNN에서 공통적으로 발생하는 문제는 서로 다른 노드 유형 간의 레이블 불균형이다.
쉽게 설명하자면, 예를 들어, 비디오, 텍스트, 이미지와 같은 콘텐츠 노드의 레이블은 사용 가능하고 풍부하지만, 사용자나 계정 노드처럼 그 외의 유형은 개인 정보 보호 제한으로 인해 사용할 수 없거나 수집시 많은 비용이 발생한다. 다시 말해 아래 그림과 같이 [제품, 리뷰, 사용자] 노드가 있다고 가정했을 때, [제품, 리뷰] 노드의 레이블은 풍부하고 언제든 사용할 수 있지만 반면 [사용자] 노드의 경우 개인 정보 문제로 인해 아예 접근 조차 안 될 수가 있고 이는 레이블 불균형 문제를 초래하게 된다.
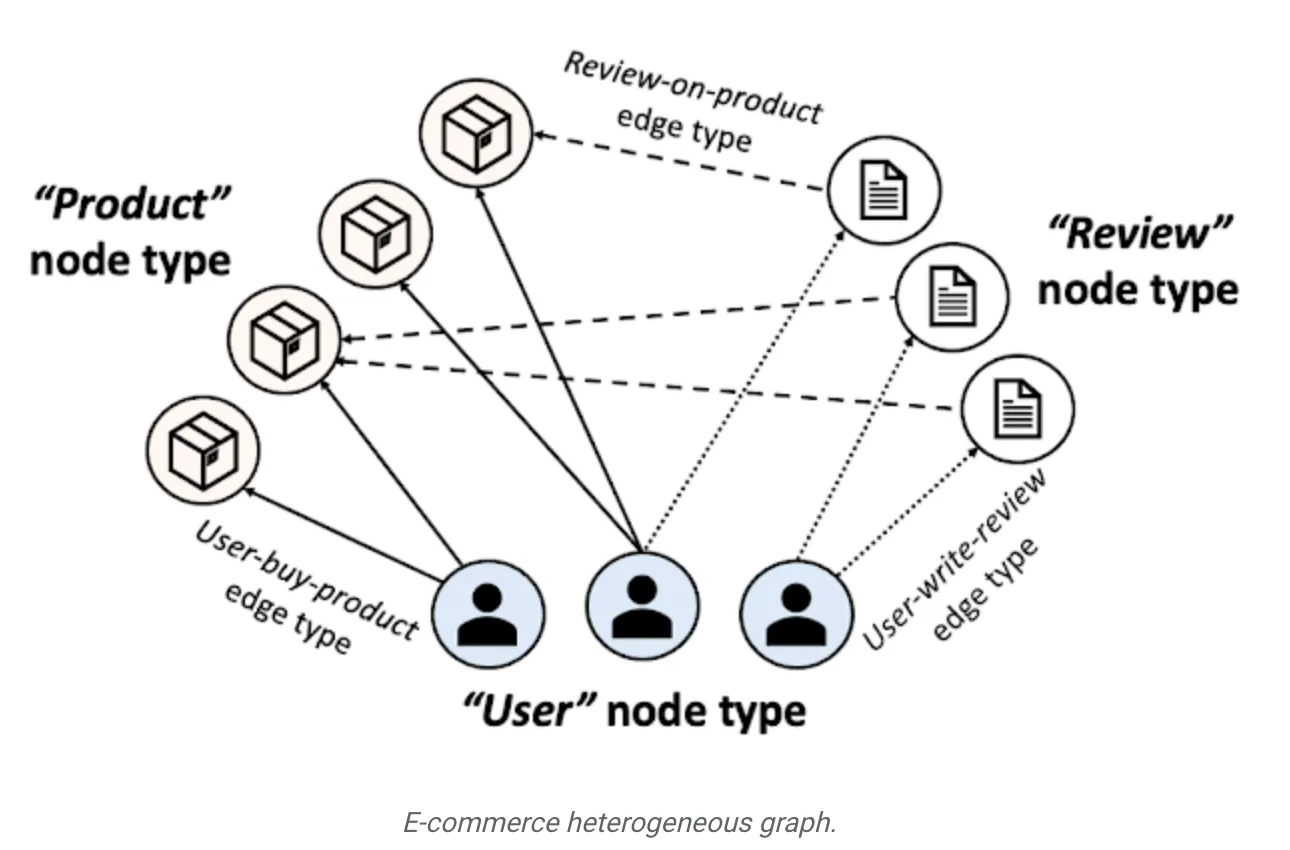
[출처: 구글 리서치 블로그] Teaching old labels new tricks in heterogeneous graphs
즉 대부분의 표준 학습 환경에서 HGNN 모델은 레이블이 풍부한 몇 개의 노드 유형에 대해서만 제대로 추론하는 법을 학습할 수 있고, 레이블이 없는 나머지 노드 유형에 대해서는 그 어떤 추론도 할 수 없다.
그렇다면 이와 같은 궁금증을 가질 수 있다.
•
추론 작업을 공유하는 레이블이 풍부한 노드와 레이블이 없는 노드 유형이 있을 때, 이 둘 간의 지식을 전송할 수 있지 않을까?
실제로 두 개의 서로 다른 HG에서 동일한 유형의 노드 간에 지식을 전이하는 실험, 그래프 간 전이학습 시나리오를 실험해보았지만 아래와 같은 이유로 리얼월드 상황에서 적용되지 않았다.
1.
그래프 간의 전이 학습 환경에서, 사용 가능한 외부의 대규모 HG는 “독점적”이다. 즉 공유하지 않을 확률이 높다.
2.
외부 HG에 접근할 수 있어도 소스 그래프의 분포가 전이학습을 적용할 만큼 타겟 그래프와 일치하지 않을 가능성이 높다.
3.
레이블 희소성 문제를 겪고 있는 노드 유형은 다른 HG에서도 동일한 문제를 겪을 확률이 높다.
⇒ 따라서 본 논문은 단일 HG에 대한 제로샷 전이 학습 접근법을 통해 레이블이 지정된 노드 유형에서 레이블이 지정되지 않은 노드 유형으로 지식을 전이하는 방법을 소개한다. 이와같은 설정은 소스 도메인과 타겟 도메인이 동일한 HG 데이터셋 내에 존재하고, 노드 유형은 서로 다르다고 가정하기 때문에 (즉, 노드는 다르지만, 동일한 HG의 일부) 앞서 언급한 그래프 간 전이학습 시나리오와 다르다고 볼 수 있다.
Preliminaries
Heterogenous graph
HG는 멀티모달 시스템의 관계형 데이터를 모델링하는데 중요한 추상화로, 로 정의된다.
•
: 노드 집합
•
: 정렬된 튜플 로 구성된 엣지 집합,
•
: 연관된 맵 를 가진 노드 타입 집합
•
: 연관된 맵 을 가진 관계 유형 집합
Heterogeneous graph neural networks
Fully-specified HGNN 모델은 노드, 엣지, 메타-경로 유형 별로 특화된 파라미터를 가지고 있어 HGNN 데이터 구조에 인코딩된 복잡한 관계를 가장 효과적으로 활용할 수 있다.
본 논문은 논문에서 제안하고 있는 Knowledge Transfer Network를 위한 베이스 모델로 Heterogeneous Message-Passing Neural Networks(HMPNN)이라는 HGNN을 사용한다. HMPNN은 각 노드/엣지 유형에서 모든 변환과 메시지 행렬을 특화하여 표준 MPNN을 확장한 것으로 범용성이 뛰어나 HGNN의 기본 모델로도 많이 사용된다. HMPNN에서 임의의 노드에 대해 -번째 레이어에서 노드의 임베딩은 아래와 같은 일반적인 공식을 통해 구할 수 있다.
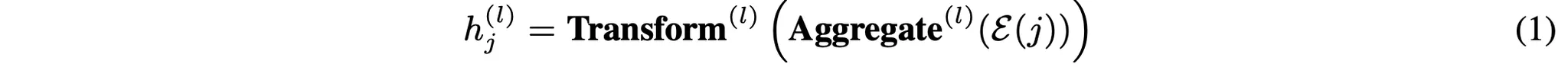
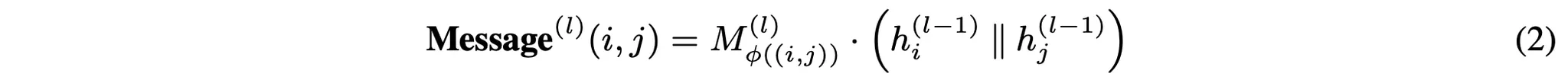
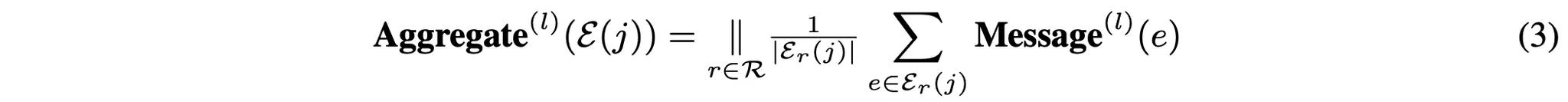
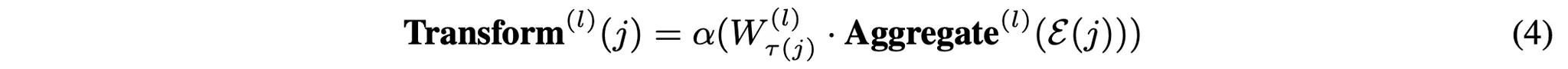
우선 식(2)를 통해 선형 Message 함수를 정의한다. 그 다음 Aggregate 함수(3)는 엣지 유형별로 메시지를 mean-pools하고 concat한다. 마지막으로 Transform 함수(4)는 메시지를 유형별 잠재 공간으로 매핑한다.
-레이어를 반복함으로 HMPNN은 고도로 컨텍스트화된 최종 노드 표현을 출력하고, 최종 노드 표현은 노드 분류 또는 링크 예측과 같은 다운스트림 이기종 네트워크 작업을 수행하기 위해 다른 모델의 입력값이 될 수 있다.
Problem Definition
Zero-shot cross-type transfer learning running on a HG.
의 노드 속성을 가진 HG, 에서 노드 유형 와 가 분류 작업 를 공유한다고 가정한다. 테스트 단계에서 훈련에 타겟 유형 노드의 레이블이 사용되지 않은 레이블 을 예측해야 한다.
Cross-Type Feature Extractor Transformations in HGNNs
는 유형 의 입력 노드 속성을 공유하는 피처 공간 에 매핑하는데 참여하는 파라미터로 구성된 HGNN의 “피처 추출기”로 정의한다. HMPNN 내의 피처 추출기 간의 변환(Transformation)을 도출한다.
Feature extractors in HMPNNs
먼저 그림1 (a)에 표시된 Toy HG를 사용해서 일때 와 의 차이를 직관적으로 추론한다. 라는 점에 주목하면서 노드 를 고려한다.위의 HMPNN 방정식 (2)-(4)를 사용해서 모든 에 대해 다음과 같다. (*식에 대한 자세한 사항은 논문 참고)
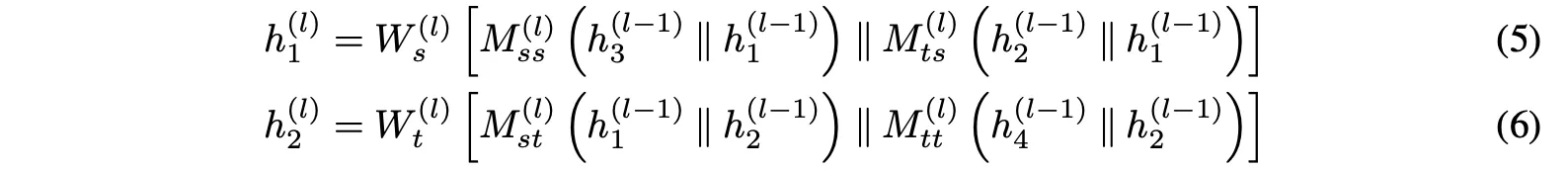
즉, 노드 유형 와 에 동일한 HMPNN이 적용되더라도 피처 추출기 와 는 계산 경로가 다르다. 따라서 노드 피처를 서로 다른 잠재 공간에 투영하고 훈련 중에 서로 다른 업데이트 방정식을 갖는다. (각 노드 유형에 대한 임베딩을 계산하기 위해 서로 다른 모듈 세트를 사용: 그림1-(b),(c) 참고)
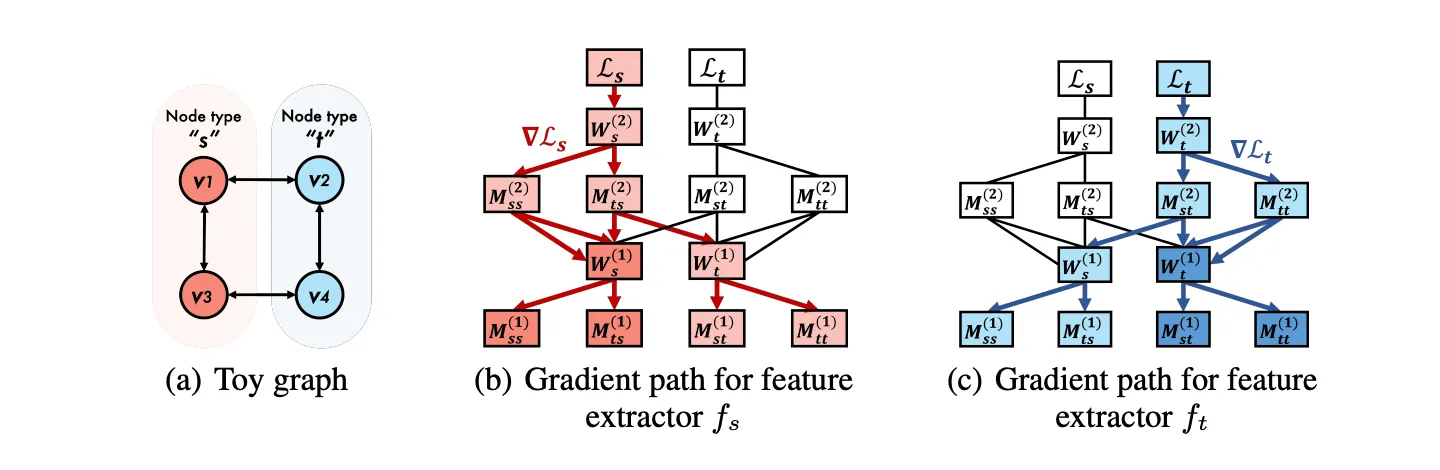
그림1. Illustration of a toy heterogeneous graph and the gradient paths for feature extractors
그렇다면 여기까지의 시뮬레이션을 통한 실험 결과를 살펴보자. 소스 노드 유형에 대해 HGNN을 사전훈련할 때, HGNN의 소스 모듈은 잘 훈련되었지만, 타깃 모듈은 소량의 그레디언트만 유입되어서 훈련이 소스 모듈만큼 되지 않는다.
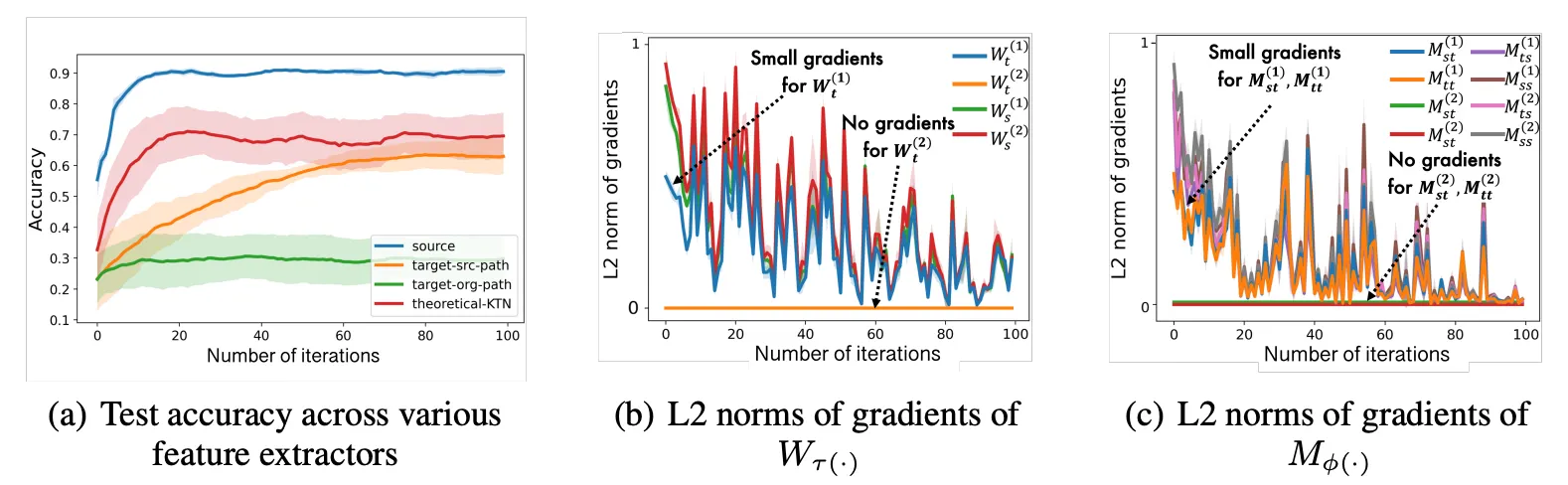
그림2. HGNNs trained on a source domain underfit a target domain even on a nice heterogeneous graph
→ 이 경우 HMPNN 모델은 타겟 노드 유형에 대해 잘못된 노드 임베딩을 출력하여 작업 성능 저하를 초래하며 이는 단순히 입력 데이터 분포를 일치시키는 것만으로는 해결되지 않은 문제임을 알 수 있다. 또한 사전학습된 HGNN과 분류기를 타겟 노드 유형에 직접 재사용 할 수 없다.
Relationship between feature extractors in HMPNNs
HMPNN 모델은 각 노드 유형에 대해 서로 다른 피처 추출기를 제공한다는 것을 보여주지만 여전히 는 하나의 HMPNN 모델 내에 구축되며 서로 중간에서 피처 임베딩을 교환한다.
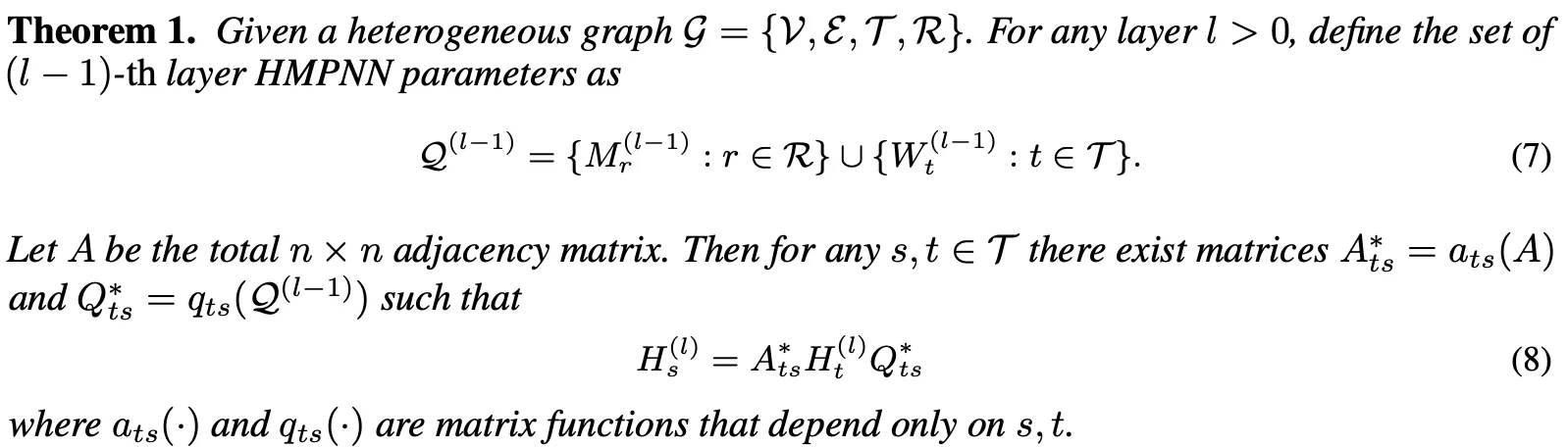
KTN: Trainable Cross-Type Transfer Learning for HGNNs
다시말해 본논문은 사전 학습된 HGNN 모델에 의해 계산된 (레이블이 없는) 타깃 노드 임베딩이 소스 노드 임베딩의 분포를 따르도록 변환하는데 중점을 둔다. 그런 다음 소스 노드 유형에 대해 사전 학습된 분류기는 타겟 노드 유형에 재사용할 수 있다.
HGNN은 연결된 노드 임베딩을 집계하여 각 레이어에서 타켓 노드의 임베딩을 보강한다. 즉 소스 유형과 타겟 유형 둘다 이전 레이어의 노드 임베딩이라는 동일한 입력을 통해 업데이트한다. 이는 서로가 서로를 표현할 수 있다는 것을 의미한다(Theorem 1 참고).
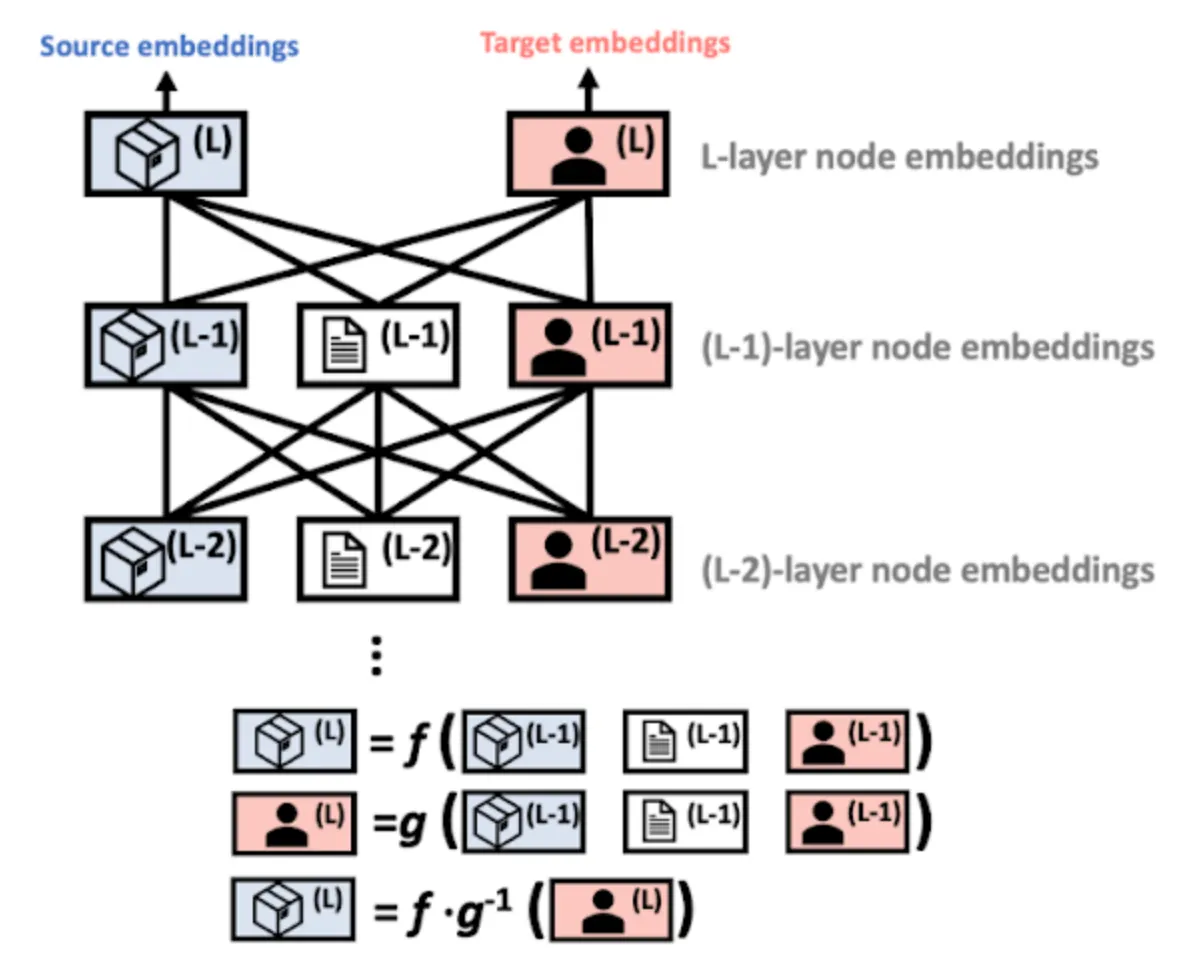
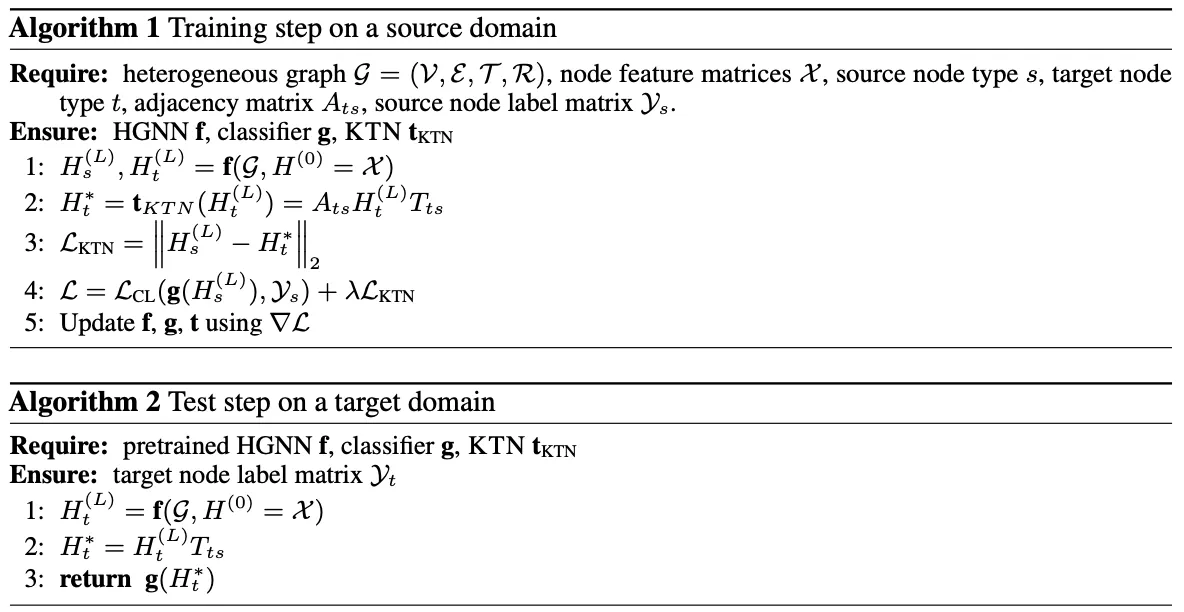
그후 타겟 노드 임베딩을 소스 도메인에 매핑하기 위한 과정을 거치는데 이때 임의의 HG와 HGNN에 대한 매핑 함수를 직접 계산하는 대신, 식(8)을 학습 가능한 그래프 컨볼루션 네트워크로 모델링하여 매핑 함수를 학습한다. 이를 Knowledge Transfer Network(KTN)이라고 한다. 그 후 사전 훈련 단계에서 성능 손실을 최소화하는 정규화 기법을 통해 KTN을 훈련하고, 테스트 시에는 분류를 위해 훈련된 KTN을 사용하여 사전 훈련된 HGNN에서 계산된 타겟 임베딩을 소스 도메인에 매핑한다.
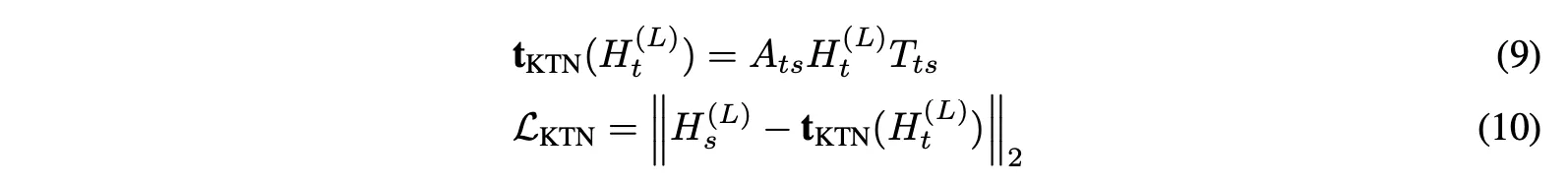
최종적으로는 다음과 같이 HGNN 모델, 분류기, KTN에 대해 분류 손실과 전달 손실을 공동으로 최소화한다.
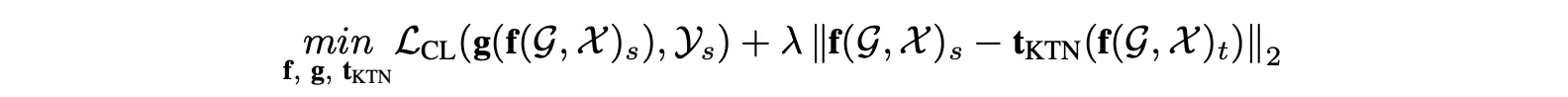
•
알고리즘1은 소스 도메인에서의 훈련 단계를, 알고리즘2는 타겟 도메인에서의 테스트 절차를 보여준다.
Experiment
Datasets.
•
Open Academic Graph(OAG).
◦
check download here → [dataset]
◦
OAG 데이터는 5가지 유형의 노드로 구성되어있다: papers(P), authors(A), institutions(I), venues(V), fields(F). Paper와 author 노드는 텍스트 기반의 속성이고, institution, venues, fields 노드는 텍스트와 그래프 구조 기반의 속성을 지니고 있다.
◦
본논문은 OAG로부터 computer science, computer networks, machine learning academic 그래프라는 세가지 특정 분야의 하위그래프를 통해 실험을 진행했다.
•
PubMed.
◦
check download here → [dataset]
◦
PubMed 데이터는 4가지 유형의 노드로 구성되어있다: genes(G), diseases(D), chemicals(C), species(S). Genes와 chemicals 노드는 그래프 구조 기반의 속성을, disease와 species 노드는 텍스트 기반의 속성을 지니고 있다.
Experiments.
18개의 다른 제로샷 전이 학습 테스크를 세개의 OAG와 PubMed 그래프에 돌렸고,
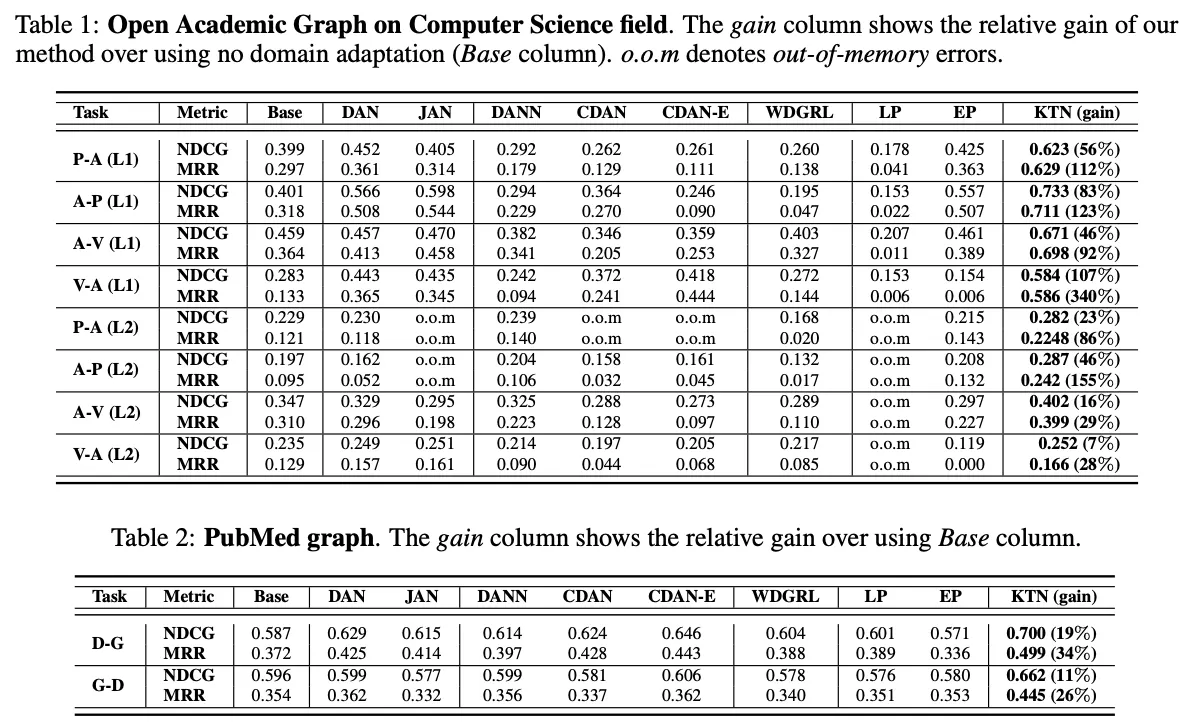
표 1과 표2를 보면, 본논문에서 제안한 KTN 모델이 모든 테스크 상의 모든 베이스라인들보다 뛰어난 결과를 보여준다는 걸 알 수 있다.
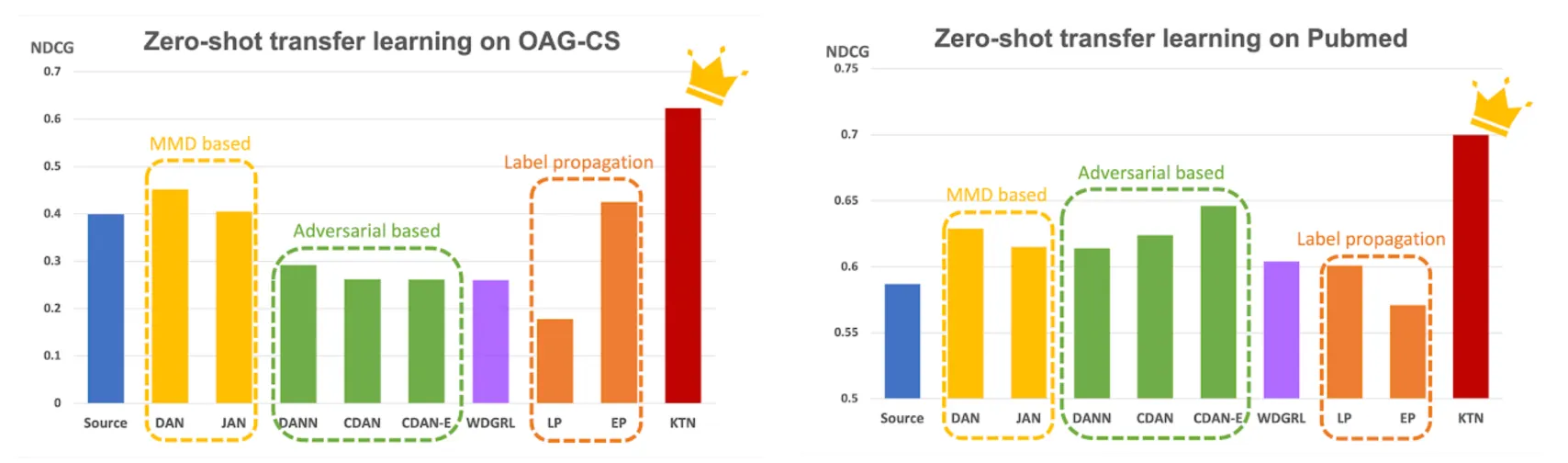
[출처: google research blog] 표1과 표2의 결과를 직관적으로 보여주는 그림
•
KTN의 보편성에 대한 실험
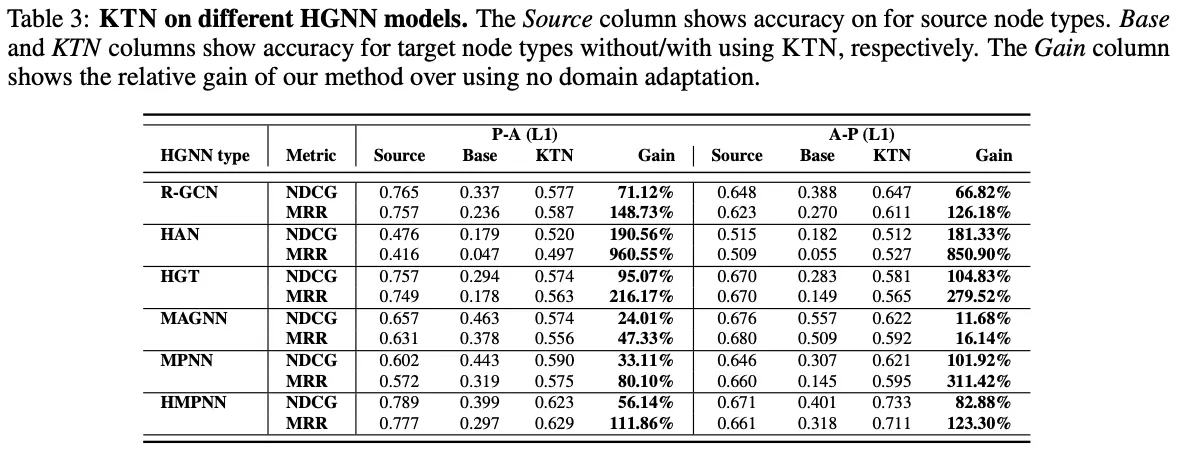
◦
6개의 다른 HGNN 모델의 타겟 노드 유형 정확도를 실험하기 위해 베이스 모델과 KTN을 사용한 모델을 비교한 실험이다. 표 3에서 본논문이 제안한 KTN은 모든 HGNN 모델에서 타겟 노드의 정확도를 엄청나게 향상시킨 걸 볼 수 있다.
◦
결과적으로 KTN을 HGNN 모델에서 보편적으로 사용하기 적합하다는 것을 알 수 있다.
정리하자면, 레이블이 없는 타겟 노드를 레이블이 풍부한 소스 노드로의 변환 행렬로 표현하는 방법이 꽤 흥미롭고 실용적인 논문이다. 하지만 이 논문에 대해 궁금한 점이 있다. (1) HGNN에서 보편적으로 사용될 수 있다는 실험결과가 있지만, 같은 HG내의 다른 노드 유형 간이라는 한정적인 제약사항이 있기에, 보편적으로 사용할 수 있다고 하기에 적합한지 궁금하다. (2) 논문에서 사용한 데이터셋들이 리얼월드에서 구축한 데이터라고 하지만 아카데미와 메디컬에 한정되있기 때문에, 이커머스처럼 좀더 일반적인 리얼월드 데이터셋을 가지고 테스트를 하는게 본논문이 주장하는 보편성 부분에 더 적합하지 않았을까 라는 개인적인 생각도 든다.
결국 궁극적으로는 리얼월드 상황에서는 같은 HG 내에서의 레이블 불균형 문제 해결보다 다른 HG 간의 같은 유형의 노드 또는 다른 유형의 노드의 레이블 불균형 문제를 해결하는 일이 리얼월드에서는 더 중요해보이는데. 이런 부분으로의 연구 확장 가능성 역시 궁금하다.